数据本地性
数据计算尽可能在数据所在的节点上运行,这样可以减少数据在网络上的传输,毕竟移动计算比移动数据代价小很多。进一步看,数据如果在运行节点的内存中,就能够进一步减少磁盘的I/O的传输。在spark中,数据本地性优先级从高到低为PROCESS_LOCAL>NODE_LOCAL>NO_PREF>RACK_LOACL>ANY即最好是运行在节点内存中的数据,次要是同一个NODE,再次是同机架,最后是任意位置。
PROCESS_LOCAL 进程本地化:task要计算的数据在同一个Executor中
NODE_LOCAL 节点本地化:速度比 PROCESS_LOCAL 稍慢,因为数据需要在不同进程之间传递或从文件中读取
NODE_PREF 没有最佳位置这一说,数据从哪里访问都一样快,不需要位置优先。比如说SparkSQL读取MySql中的数据
RACK_LOCAL 机架本地化,数据在同一机架的不同节点上。需要通过网络传输数据及文件 IO,比 NODE_LOCAL 慢
ANY 跨机架,数据在非同一机架的网络上,速度最慢
延迟执行
在任务分配到运行节点时,先判断任务最佳运行节点是否空闲,如果该节点没有足够的资源运行该任务,在这种情况下任务会等待一定的时间;如果在等待的时间内该节点释放出足够的资源,则任务在该节点运行,如果还是不足会找出次佳节点进行运行。通过这样的方式进行能让任务运行在更高级别的数据本地性节点,从而减少磁盘I/O和网络传输。一般情况下只对PROCESS_LOCAL和NODE_LOCAL两个数据本地性优先级进行等待,系统默认延迟时间为3S;
spark任务分配的原则是让任务运行在数据本地性优先级别更高的节点上,甚至可以为此等待一定的时间。该任务分派过程是由TaskSchedulerImpI.resourceOffers方法实现,该方法先对应用程序获取的资源进行混洗,以使任务能够更加均衡的分散在集群中运行,然后对任务集对应的TaskSetManager根据设置的调度算法进行排序,最后对TaskSetManager中的任务按照数据本地性分配任务运行节点,分配时先根据任务集的本地性从优先级高到低分配任务,在分配过程中动态判断集群中节点的运行情况,通过延迟执行等待数据本地性更高的节点运行。
High Available(HA)
Master异常
Master作为spark独立运行模式的核心,如果Master出现异常,则整个集群的运行状况和资源都无法进行管理,整个集群就处于群龙无首的状况,spark在设计的时候就考虑到了这个情况,在集群运行的时候,Master将启动一个或者多个Standy Master,当Master出现异常的时候,Standy Master将根据一定的规则确定其中一个接管Master。在独立运行模式中,spark支持如下几种策略,可以在配置文件spark-env.sh配置项spark.deploy.recoveryMode进行设置,默认为None.
①ZOOKEEPER:集群的元数据持久化到ZooKeeper中,当Master出现异常时,Zookeeper会通过选举机制选举出新的Master,新的Master接管时需要从Zookeeper获取持久化信息并根据这些信息回复集群状态
②FILESYSTMEM:集群的元数据持久化到本地文件系统中,当Master出现异常时,只要在该机器上重新启动Master,启动后新的Master获取持久化信息并根据这些信息恢复集群状态。
③CUSTOM:自定义恢复方式,对StandaloneRecoveryModeFactory抽象类进行实现并把该类配置到系统中,当Master出现异常时,会根据用户自定义方式恢复集群状态
④NONE:不持久化集群的元数据,当master出现异常时,启动新的Master不进行恢复集群状态,而是直接接管集群
如何配置spark master的HA
1.配置zookeeper,下载SPARK并解压
2.配置spark-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_101
export HADOOP_HOME=/root/hadoop/hadoop-2.7.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SCALA_HOME=/root/scala/scala-2.11.8
export HIVE_HOME=/root/hive/apache-hive-2.1.1
export LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$LIB_NATIVE_DIR"
export SPARK_CLASSPATH=$SPARK_HOME/mysql-connector-java-5.1.39.jar
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=spark1:2181,spark2:2181,spark3:2181,spark4:2181 -Dspark.deploy.zookeeper.dir=/spark"
说明: -Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。就是说用zookeeper做了spark的HA配置,Master(Active)挂掉的话,Master(standby)要想变成Master(Active)的话,Master(Standby)就要像zookeeper读取整个集群状态信息,然后进行恢复所有Worker和Driver的状态信息,和所有的Application状态信息; -Dspark.deploy.zookeeper.url=spark1:2181,spark2:2181,spark3:2181,spark4:2181#将所有配置了zookeeper,并且在这台机器上有可能做master(Active)的机器都配置进来;
-Dspark.deploy.zookeeper.dir=/spark -Dspark.deploy.zookeeper.dir是保存spark的元数据,保存了spark的作业运行状态; zookeeper会保存spark集群的所有的状态信息,包括所有的Workers信息,所有的Applactions信息,所有的Driver信息,如果集群
a.在Master切换的过程中,因为程序在运行之前,已经申请过资源了,driver和Executors通讯,不需要和master进行通讯的,所有的已经在运行的程序皆正常运行!因为Spark Application在运行前就已经通过Cluster Manager获得了计算资源,所以在运行时Job本身的调度和处理和Master是没有任何关系的!
b. 在Master的切换过程中唯一的影响是不能提交新的Job:一方面不能够提交新的应用程序给集群,因为只有Active Master才能接受新的程序的提交请求;另外一方面,已经运行的程序中也不能够因为Action操作触发新的Job的提交请求;
3.复制slaves.template成slaves,配置如下:
spark1
spark2
spark3
spark4
4.将配置好安装包分发给其他节点
5.各个节点配置环境变量,并使之生效
6.启动zookeeper
所有节点均要执行zkServer.sh start
7.启动hdfs集群
任意一个节点执行即可
8.启动spark集群
在一个节点启动start-all.sh,其他节点启动start-master.sh
driver的功能
1.一个Spark作业运行时包括一个Driver进程,也是作业的主进程,具有main函数,并且有SparkContext的实例,是程序的人口点;
2.功能:负责向集群申请资源,向master注册信息,负责了作业的调度,负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler。
spark的部署模式
本地模式 运行在一个机器上,可以多线程执行,默认启动和CPU核数一样的线程,此模式主要用于本地调试测试
伪分布模式 一台机器上模拟集群运行,master,worker,sparkcontext这些进程都在一台机器上
独立运行模式 spark自身实现的资源调度框架,由客户端,master节点,worker节点组成,sparkcontext可以运行在本地客户端,也可以运行在master节点上,spark-shell的spark-shell在master节点上运行,使用spark-submit提交的或者IDEA等平台开发的,sparkcontext运行在本机客户端。资源管理和任务监控是Spark自己监控,这个模式也是其他模式的基础
Spark on yarn模式 分布式部署集群,资源和任务监控交给yarn管理,但是目前仅支持粗粒度资源分配方式,包含cluster和client运行模式,cluster适合生产,driver运行在集群子节点,具有容错功能,client适合调试,dirver运行在客户端
Spark On Mesos模式。官方推荐这种模式(当然,原因之一是血缘关系)。正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。用户可选择两种调度模式之一运行自己的应用程序:
1) 粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
2) 细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。
spark的组件
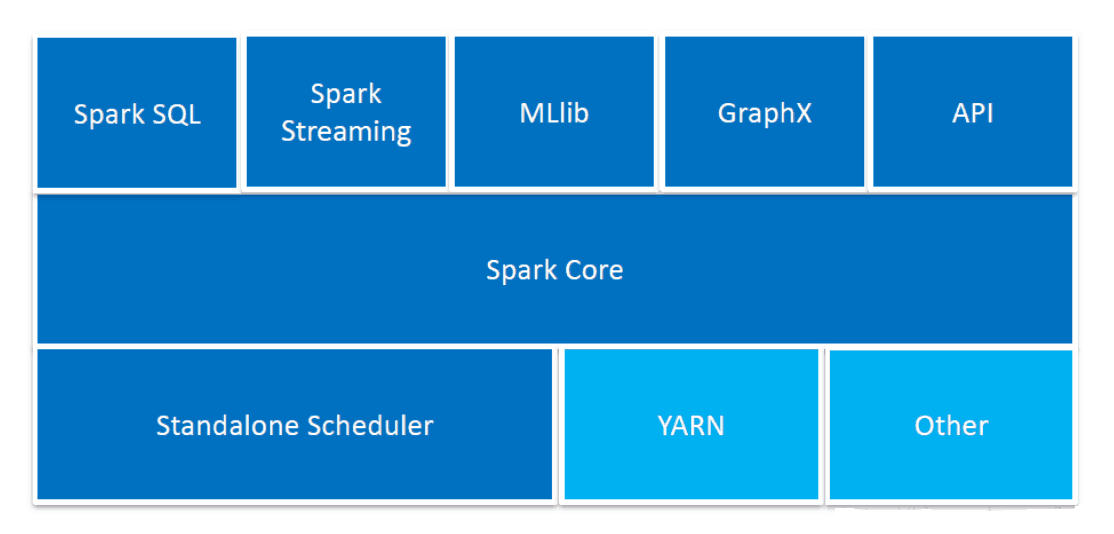
Spark core:核心组件,是个分布式大数据处理架构,提供了多种资源调度管理,通过内存计算,DAG等机制保证分布式计算的快速,并引入了RDD的抽象保证数据的高容错性。
SparkStreaming是一个对实时数据流进行高吞吐、高容错的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部系统.数据库或者应用到仪表盘。
spark sql:能够统一处理关系数据表和RDD,是开发人员轻松使用SQL命令进行玩不查询,同时进行复杂的数据分析
MLlib:机器学习
BlinkDB :是一个用于在海量数据上运行交互式 SQL 查询的大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
GraphX图计算
worker的主要工作
主要功能:管理当前节点内存,CPU的使用状况,接收master分配过来的资源指令,通过ExecutorRunner启动程序分配任务,管理分配新进程,做计算的服务。需要注意的是:1)worker会不会汇报当前信息给master,worker心跳给master主要只有workid,它不会发送资源信息以心跳的方式给mater,master分配的时候就知道worker,只有出现故障的时候才会发送资源。2)worker不会运行代码,具体运行的是Executor是可以运行具体appliaction写的业务逻辑代码,操作代码的节点,它不会运行程序的代码的。
Spark为什么比mapreduce快?
1)基于内存计算,减少低效的磁盘交互;2)高效的调度算法,基于DAG;3)容错机制Linage(血统),精华部分就是DAG和Lingae
Spark的并行计算
spark用户提交的任务成为application,一个application对应一个sparkcontext,app中存在多个job,每触发一次action操作就会产生一个job。这些job可以并行或串行执行,每个job中有多个stage,stage是shuffle过程中DAGSchaduler通过RDD之间的依赖关系划分job而来的,每个stage里面有多个task,组成taskset有TaskSchaduler分发到各个executor中执行,executor的生命周期是和app一样的,即使没有job运行也是存在的,所以task可以快速启动读取内存进行计算。
RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
RDD的属性
A list of partitions 分区,并行计算
A function for computing each split 一个函数应用于各个分区(并行计算)
A list of dependencies on other RDDs 依赖其他RDD 传递依赖 RDD1=>RDD2=>RDD3
Optionally(可选), a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
cache后面能接其他算子的结果
如下例:
scala> val bb=mapRDD.cache.count
bb: Long = 10
cache后面接其他算子没有问题,但是本来打算cache的是一个RDD,由于后面的count重新触发了cache,结果cache了8,没达到缓存RDD的目的
数据本地性的确定环节
task运行在那他机器上,是在DAGscheduler进行stage的划分的时候,确定的
RDD的弹性表现在哪几点?
1、自动的进行内存和磁盘数据存储的切换;
2、基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
3、Task如果失败会自动进行特定次数的重试(默认4次);
4、Stage如果失败会自动进行特定次数的重试(可以只运行计算失败的阶段);只计算失败的数据分片;
5、checkpoint和persist
6、数据调度弹性:DAG TASK 和资源 管理无关
7、数据分片的高度弹性(人工自由设置分片函数),repartition
常规的容错方式
1).数据检查点,会发生拷贝,浪费资源
2).记录数据的更新,每次更新都会记录下来,比较复杂且比较消耗性能
Spark的持久化
把RDD持久化到内存极大的提高了迭代以及各计算模型之间的数据共享,一般情况下执行点60%内存用于缓存数据,剩下40%用于运行任务,如果某个计算步骤比较多,计算复杂,网络传输shuffle,最后只有一个结果,如果在计算中途做保存一些临时数据,失败的的风险很高,重算成本更高。可以在shuffle之后做一个persist.
序列化
序列化的好处就是可以减少空间,高效存储,传输更快,但使用数据的时候要反序列化,耗时耗CPU
HashPartitioner与RangePartitioner
HashPartitioner根据给定的KEY随机生成分区ID,弊端是数据不均匀,容易导致数据倾斜
RangePartitioner分区则尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,也就是说一个分区中的元素肯定都是比另一个分区内的元素小或者大;但是分区内的元素是不能保证顺序的
如下例所示
scala> import org.apache.spark.HashPartitioner
import org.apache.spark.HashPartitioner
scala> import org.apache.spark.RangePartitioner
import org.apache.spark.RangePartitioner
scala> mapRDD.collect
res23: Array[(Int, Int)] = Array((0,1), (1,2), (1,3), (2,4), (2,5), (3,6), (4,7), (4,8), (5,9), (5,10))
scala> mapRDD.partitionBy(new RangePartitioner(5,mapRDD)).map(x=>(TaskContext.getPartitionId,x)).collect
res24: Array[(Int, (Int, Int))] = Array((0,(0,1)), (0,(1,2)), (0,(1,3)), (1,(2,4)), (1,(2,5)), (2,(3,6)), (3,(4,7)), (3,(4,8)), (4,(5,9)), (4,(5,10)))
scala> mapRDD.partitionBy(new HashPartitioner(5)).map(x=>(TaskContext.getPartitionId,x)).collect
res25: Array[(Int, (Int, Int))] = Array((0,(0,1)), (0,(5,9)), (0,(5,10)), (1,(1,2)), (1,(1,3)), (2,(2,4)), (2,(2,5)), (3,(3,6)), (4,(4,7)), (4,(4,8)))
Spark自定义partitioner分区器
derby数据库是单实例,不能支持多个用户同时操作
窄依赖父RDD的partition和子RDD的parition,不一定都是一对一的关系,比如join操作的每个partiion仅仅和已知的partition进行join,就是窄依赖,不是一对一的关系
shuffle
shuffle在中文的意思是洗牌,混洗的意思,shuffle阶段会涉及到磁盘的读写以及网络的传输,因此shuffle的性能高低直接影响整个程序的性能和吞吐量。就是将各个节点上的同一类数据汇集到某一个节点进行计算,把这些分布在不同节点的数据按照一定的规则聚集到一起的过程称为shuffle。
spark的处理方式是一个迭代的过程。shuffle的写操作分为基于哈希的shuffle写操作和基于排序的shuffle的写操作两种类型,基于hash写操作在map和reduce数量较大的情况下会导致写数据文件数量大和缓存开销过大,产生很多小文件,甚至导致数据倾斜,基于排序的shuffle写操作,每个shuffle map task不会为后续的每个任务创建单独的文件,而是会将所有结果写到一个文件中,同时生成一个索引文件index进行索引,通过这种机制避免了大量文件的产生,减轻了文件管理系统额压力,节省了内存避免了GC的风险和频率。
HashBaseShuffle 缺点:小文件过多,数量为task*reduce的数量
优化:使用spark.shuffle.consolidateFiles机制,修改值为true,默认为false,没有启用。文件数量为:reduce*core,在一个core里面并行运行的task其中生成的文件数为reduce的个数。一个core里面并行运行的task,将数据都追加到一起。
spark支持两种方式的Shuffle,即Hash Based Shuffle和Sort Based Shuffle。
Spark 1.2的默认Shuffle机制从Hash变成了Sort。从而使得spark在集群上处理更大规模的数据
如果需要Hash Based Shuffle,在spark-defaults.conf中,将spark.shuffle.manager设置成“hash”即可。
parition和block
hdfs中的block是分布式存储的最小单元,等分,可设置冗余,这样设计有一部分磁盘空间的浪费,但是整齐的block大小,便于快速找到、读取对应的内容;
Spark中的partion是弹性分布式数据集RDD的最小单元,RDD是由分布在各个节点上的partion组成的。partion是指的spark在计算过程中,生成的数据在计算空间内最小单元,同一份数据(RDD)的partion大小不一,数量不定,是根据application里的算子和最初读入的数据分块数量决定;
block位于存储空间、partion位于计算空间,block的大小是固定的、partion大小是不固定的
-----------------
二次排序就是首先按照第一字段排序,然后再对第一字段相同的行按照第二字段排序,注意不能破坏第一次排序的结果。
scala> val aa=sc.makeRDD(1 to 21,5)
aa: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at <console>:25
scala> val mapRDD=aa.map(x=>(TaskContext.getPartitionId,x))
mapRDD: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[12] at map at <console>:27
scala> mapRDD.groupByKey().collect
res3: Array[(Int, Iterable[Int])] = Array((0,CompactBuffer(1, 2, 3, 4)), (1,CompactBuffer(5, 6, 7, 8)), (2,CompactBuffer(9, 10, 11, 12)), (3,CompactBuffer(13, 14, 15, 16)), (4,CompactBuffer(17, 18, 19, 20, 21)))
scala> mapRDD.groupByKey().map(x=>(x._1,x._2.toList.sorted.reverse)).sortByKey(false).collect //首次排序sorted.reverse//二次排序sortByKey(false).
res16: Array[(Int, List[Int])] = Array((4,List(21, 20, 19, 18, 17)), (3,List(16, 15, 14, 13)), (2,List(12, 11, 10, 9)), (1,List(8, 7, 6, 5)), (0,List(4, 3, 2, 1)))
----------------
hash shuffle与sorted shuffle
处理少量数据的时候,hash shuffle会快于sorted shuffle,但数据量大的时候,sorted shuffle回比hash shuffle快许多,因为hash shuffle 会产生很多小的文件,分布不均匀,导致数据倾斜,耗内存
Sort-basesd shuffle产生的临时文件数量 为:每个Mapper任务产生2个文件,一个data,一个index索引文件。(M代表Mapper中并行partition的总数量,其实就是Mapper端SHuffleMapTask的总数量)
Sort-basesd shuffle的缺陷:
如果Mapper 中Task的数量过大,依旧会产生很多小文件。此时Shuffle在传递数据到Reducer端的过程中,传数据的过程有序列化和反序列化,要内存消耗,对GC的压力会比较大,造成系统缓慢甚至奔溃!坞丝计划就是很好的解决方案。
如果需要在分片内也进行排序的话,此时需要进行Mapper端和Reducer端的两次排序!!!这对性能也是巨大的消耗。可以改造Mapper的实现来解决这个问题。
序列化
在分布式计算中,序列化和压缩是提升性能的两个重要手段,spark通过序列化将链式分布的数据转化为连续分布分数据,这样就能够进行分布式的进程间数据通信或者在内存进行数据的压缩等操作,通过压缩能够减少内存查勇以及IO和网络数据传输开销,提升spark整体引用性能。
spark shell启动会启动spark sql,spark sql默认使用derby保存元数据,但是尽量不要用derby,它是单实例,不利于开发。会在本地生成一个文件metastore_db,如果启动报错,就把那个文件给删了 ,derby数据库是单实例,不能支持多个用户同时操作,尽量避免使用.
conf/spark-default.conf 中的相关配置
- parallelism:'pærəlɛl'ɪzəm/ 并行度,并行
spark.default.parallelism:用于设置每个stage的默认task数量,合理设置可以提高执行效率,In general, we recommend 2-3 tasks per CPU core in your cluster.
//导入隐式转换,如果不导入则无法将RDD转换成为DataFrame
import sqlContext.implicits._
二分法
scala> def sconderyfind(arr:Array[(String,String,String)],ip:Int):Long={var low=0;var high=arr.length-1;while(low<=high){val middle=(low+high)/2;if(ip>=arr(middle)._1.toInt&&ip<=arr(middle)._2.toInt) return middle;if(ip<arr(middle)._1.toInt) high=middle-1 else low=middle+1}; -1}
sconderyfind: (arr: Array[(String, String, String)], ip: Int)Long
scala> def sconderyfind(arr:Array[(String,String,String)],ip:Int):Long=
{
var low=0;
var high=arr.length-1;
while(low<=high){
val middle=(low+high)/2;
if(ip>=arr(middle)._1.toInt&&ip<=arr(middle)._2.toInt)
return middle;
if(ip<arr(middle)._1.toInt)
high=middle-1
else low=middle+1
};
-1
}
sconderyfind: (arr: Array[(String, String, String)], ip: Int)Long
scala> val arr=Array(("100","200","aaa"),("300","500","bb"),("800","900","bb"),("1000","1500","bb"))
arr: Array[(String, String, String)] = Array((100,200,aaa), (300,500,bb), (800,900,bb), (1000,1500,bb))
scala> sconderyfind(arr,850)
res2: Long = 2
RDD写入mysql
查看MySQL中的数据
mysql> select * from t_name;
Empty set (0.00 sec)
scala> import java.sql.{Connection,DriverManager, PreparedStatement,Date}
import java.sql.{Connection, DriverManager, PreparedStatement, Date}
scala> def rddtodb(iter:Iterator[(Int,String)]){var con:Connection=null;var ps:PreparedStatement=null;val sql="insert into t_name(id,name,createtime)values(?,?,?)" ;try{con=DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "root");iter.foreach(line=>{ps=con.prepareStatement(sql);ps.setInt(1,line._1.toInt);ps.setString(2,line._2.toString);ps.setDate(3,new Date(System.currentTimeMillis));ps.executeUpdate()}) }catch{case e:Exception=>println("mysql exception")} finally{if(con!=null)con.close;if(ps!=null)ps.close}}
rddtodb: (iter: Iterator[(Int, String)])Unit
scala> def rddtodb(iter:Iterator[(Int,String)]){
var con:Connection=null;
var ps:PreparedStatement=null;
val sql="insert into t_name(id,name,createtime)values(?,?,?)" ;
try{
con=DriverManager.getConnection("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=UTF-8", "root", "root");
iter.foreach(line=>{
ps=con.prepareStatement(sql);
ps.setInt(1,line._1.toInt);
ps.setString(2,line._2.toString);
ps.setDate(3,new Date(System.currentTimeMillis));
ps.executeUpdate()})
}catch
{case e:Exception=>println("mysql exception")}
finally{if(con!=null)con.close;if(ps!=null)ps.close}}
rddtodb: (iter: Iterator[(Int, String)])Unit
scala> val nameRDD=sc.makeRDD(Array((1,"tian"),(2,"wang"),(3,"liu"),(4,"ma"),(5,"lilei"),(6,"hanmeimei")),3)
nameRDD: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[2] at makeRDD at <console>:25
scala> nameRDD.foreachPartition(rddtodb)
查看mysql中的数据
mysql> select * from t_name;
+------+-----------+---------------------+
| id | name | createtime |
+------+-----------+---------------------+
| 1 | tian | 2018-08-21 00:00:00 |
| 2 | wang | 2018-08-21 00:00:00 |
| 3 | liu | 2018-08-21 00:00:00 |
| 4 | ma | 2018-08-21 00:00:00 |
| 5 | lilei | 2018-08-21 00:00:00 |
| 6 | hanmeimei | 2018-08-21 00:00:00 |
+------+-----------+---------------------+
6 rows in set (0.00 sec)
-------------------------
开发过程中,尽可能避免使用reduceByKey、join、distinct、repartition等会进行shuffle的算子,尽量使用map类的非shuffle算子,没有shuffle操作或者仅有较少shuffle操作的Spark作业,可以大大减少性能开销。
---------------------------
Spark Shuffle后续优化方向
压缩:对数据进行压缩,减少写读数据量;
内存化:Spark历史版本中是有这样设计的:Map写数据先把数据全部写到内存中,写完之后再把数据刷到磁盘上;考虑内存是紧缺资源,后来修改成把数据直接写到磁盘了;对于具有较大内存的集群来讲,还是尽量地往内存上写吧,内存放不下了再放磁盘。
Spark中的数据倾斜问题
定位数据倾斜,是OOM(out off memory)了,还是任务执行缓慢,看日志,看WebUI
避免不必要的shuffle
改变并行度,并行度太小导致数据分布不均为
分区方式不合理,使用自定义分区函数进行分区
创建RDD的方式
基于程序中的集合,基于外部系统的文件(如HDFS),转换获得,数据库中也可以获得,基于数据流等
Spark并行度的设置
spark并行度,每个core承载2~4个partition,32个core,那么64~128之间的并行度,也就是设置64~128个partion,并行度和数据规模大下无关,只和内存使用量和cpu使用
时间有关
spark数据存储位置由BlockManager 管理
BlockManager 是 spark 中至关重要的一个组件, 在 spark的的运行过程中到处都有 BlockManager 的身影, 只有搞清楚 BlockManager 的原理和机制,你才能更加深入的理解 spark。BlockManager 是一个嵌入在 spark 中的 key-value型分布式存储系统,是为 spark 量身打造的, BlockManager 在一个 spark 应用中作为一个本地缓存运行在所有的节点上, 包括所有 driver 和 executor上。 BlockManager 对本地和远程提供一致的 get 和set 数据块接口, BlockManager 本身使用不同的存储方式来存储这些数据, 包括 memory, disk, off-heap。
spark存储过程分为写数据和读数据两个过程,度数据分为本地读取和远程节点读取两种方式。
spark将不能序列化的对象封装成object
driver通过collect把集群中各个节点的内容收集过来汇总成结果,collect返回结果是Array类型的,collect把各个节点上的数据抓过来,抓过来数据是Array型,collect对Array抓过来的结果进行合并,合并后Array中只有一个元素,是tuple类型(KV类型的)的。
scala> val str="ni hao who are you what is your name"
str: String = ni hao who are you what is your name
scala> str.split(" ").takeWhile(_.length==2)
res21: Array[String] = Array(ni)
scala> str.split(" ").take(5)
res22: Array[String] = Array(ni, hao, who, are, you)
scala> str.split(" ").takeRight(5)
res23: Array[String] = Array(you, what, is, your, name)
spark 修改默认task执行个数
spark中有partition的概念,每个partition都会对应一个task,task越多,在处理大规模数据的时候,就会越有效率。不过task并不是越多越好,如果平时测试,或者数据量没有那么大,则没有必要task数量太多。
参数可以通过spark_home/conf/spark-default.conf配置文件设置:
spark.sql.shuffle.partitions 20 //针对spark sql的task数量
spark.default.parallelism 30//非spark sql程序设置生效
在Spark中实现map-side join和reduce-side join
Map-side Join:如果要join的表中一个是大表,一个是小表(小到可以加载到内存中),就可以采用该算法。该算法可以将join算子执行在Map端,无需经历shuffle和reduce等阶段,因此效率非常高。
scala> val smallrdd=sc.makeRDD(Array((1,"tian"),(2,"wang")))
smallrdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[27] at makeRDD at <console>:25
scala> val bigrdd=sc.makeRDD(Array((1,"tianyongtao"),(2,"wangbajiu"),(1,"hhee"),(2,"hhee")))
bigrdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[28] at makeRDD at <console>:25
scala> var bc=sc.broadcast(smallrdd.collectAsMap)
bc: org.apache.spark.broadcast.Broadcast[scala.collection.Map[Int,String]] = Broadcast(19)
scala> bigrdd.mapPartitions(iter=>{val m=bc.value;for((k,v)<-iter if m.contains(k))yield (k,(v,m.get(k).getOrElse("")))}).collect
res52: Array[(Int, (String, String))] = Array((1,(tianyongtao,tian)), (2,(wangbajiu,wang)), (1,(hhee,tian)), (2,(hhee,wang)))
Reduce-side Join:
当两个文件非常大,难以将其中之一放到内存时,就可以采用Reduce-side Join。该算法需要通过Map和Reduce两个阶段完成,在Map阶段,将key相同的记录划分给同一个Reduce Task(需标记每条记录的来源,便于在Reduce阶段合并),在Reduce阶段,对key相同的进行合并。
Spark提供了Join算子,可以直接通过该算子实现reduce-side join,但要求RDD中的记录必须是key-value pairs
scala> val bigrdd1=sc.makeRDD(Array((1,"tianyongtao"),(2,"wangbajiu"),(1,"hhee"),(3,"hhee")))
bigrdd1: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[33] at makeRDD at <console>:25
scala> val bigrdd2=sc.makeRDD(Array((1,"tianyongtao"),(2,"wangbajiu"),(1,"hhee"),(3,"hhee")))
bigrdd2: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[34] at makeRDD at <console>:25
scala> bigrdd1.join(bigrdd2)
res54: org.apache.spark.rdd.RDD[(Int, (String, String))] = MapPartitionsRDD[37] at join at <console>:30
scala> bigrdd1.join(bigrdd2).collect
res55: Array[(Int, (String, String))] = Array((1,(hhee,tianyongtao)), (1,(hhee,hhee)), (1,(tianyongtao,tianyongtao)), (1,(tianyongtao,hhee)), (2,(wangbajiu,wangbajiu)), (3,(hhee,hhee)))
检查文件的情况,区块,位置
hdfs fsck /tmp/person.txt -files -blocks -locations
Connecting to namenode via http://localhost:50070/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Ftmp%2Fperson.txt
FSCK started by root (auth:SIMPLE) from /127.0.0.1 for path /tmp/person.txt at Tue Aug 21 17:27:37 CST 2018
/tmp/person.txt 98 bytes, 1 block(s): OK
0. BP-1744121868-127.0.0.1-1504694797902:blk_1073751380_10581 len=98 repl=1 [DatanodeInfoWithStorage[127.0.0.1:50010,DS-344f1c41-a710-4e59-8fd0-c4eb3a00a998,DISK]]
Status: HEALTHY
Total size: 98 B
Total dirs: 0
Total files: 1
Total symlinks: 0
Total blocks (validated): 1 (avg. block size 98 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 1
Average block replication: 1.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 1
Number of racks: 1
FSCK ended at Tue Aug 21 17:27:38 CST 2018 in 1549 milliseconds
The filesystem under path '/tmp/person.txt' is HEALTHY