Something about 树链剖分
• 线段树是不能在树上进行维护的,因为线段树是维护线性或者近似线性的数据
• 听见这个名字是在看到许多大神都在学习这个算法,看见题目就说树剖,树剖。。树剖有那么强大?
• 其实它并不难,就是将树上的节点根据某些性质,人为的编号,形成一条条链,再用线段树等数据结构维护。这些链称为树链,这个过程就是剖分
用途
问题:给你一棵树,每条边有边权,请你实现下列一系列操作
• 查询u与v之间的路径上,边权之和
• 查询u到v之间的路径上,最大值
• 给u到v之间的路径上每一条边加上一个值
• ......
我们需要知道的
• hson[]表示当前点的重儿子
• size[]表示以当前点为根的子树大小
• fa[]表示当前点的父亲,根节点的父亲为本身
• top[]表示当前点所处的链,其链头的节点编号,或者说是链中,深度最小的节点。
• dep[]表示当前点的深度;深度为当前点与根节点的距离+1
一些定义(我会让你们非常理解的)
• 重儿子 如果当前点的儿子中,size最大的;如果有多个,就随便选一个
• 轻儿子 非重儿子的其他儿子节点
• 重边 当前点与其重儿子所连起来的边
• 轻边 除了重边外的其他边
• 重链 所有重边一起连起来的一条链;可以将轻儿子自己理解为一条重链上的点,链头为本身
• 轻链 轻边,不是所有轻边连起来的链的意思。
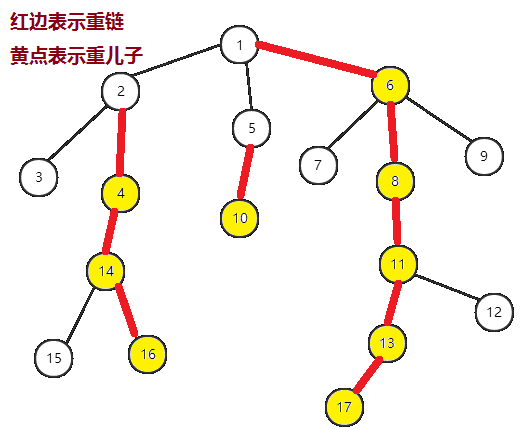
如何编号
就上面的图进行说明
我们先找重儿子,然后再找轻儿子,递归下去
也可以说将先找到的重链上的点放在线段树对应的位置上
如图,我们以此寻找到的顺序为1,6,8,11,13,17,12,7,9,5,10,2,4,14,16,15,3
可以理解为是优先选择重儿子的DFS序。
我们务必要保证同一条重链上的点要按顺序的摆放在线段树(别的数据结构)上,轻儿子后放
就这个图而言,线段树(别的数据结构)上位置1表示树上位置1,位置2表示树上位置6,位置3表示树上位置8,以此类推。。。
一些性质
• 轻边(U,V),size(V)<=size(U)/2。
• 从根到某一点的路径上,不超过O(logN)条轻边,不超过O(logN)条重链。
如何处理
第一次DFS
我们需要求出
• 父亲节点fa,深度dep,子树大小size,重儿子hson
procedure dfs1(x,now,q:longint);//x表示当前节点,now表示深度,q表示当前点父亲节点;这里连的双向边,用前向星存。 var k,maxn:longint;//k为前向星调用所需要的变量,maxn用来记录最大子树大小 begin fa[x]:=q; size[x]:=1; dep[x]:=now; maxn:=-maxlongint; k:=l[x]; while k<>0 do begin if d[k]<>q then begin dfs1(d[k],now+1,x); size[x]:=size[x]+size[d[k]]; if size[d[k]]>maxn then begin hson[x]:=d[k]; maxn:=size[d[k]]; end;//寻找重儿子 end; k:=pre[k]; end; end;
第二次DFS
我们需要求出
• 树上每一个节点的位置,在线段树(别的数据结构)上的位置,以便维护
• 每一条重链的链头,不在重链上的点,其链头为本身
procedure dfs2(x,head,q:longint);//x表示当前点;head表示链头;q表示当前点父亲节点 var k:longint; begin top[x]:=head; inc(tot); p[x]:=tot;//p[]表示树上节点在线段树上的下标 pp[tot]:=x;//线段树上的下标对应的树上节点位置 if hson[x]<>0 then dfs2(hson[x],head,x);//优先选择重儿子 k:=l[x]; while k<>0 do begin if (d[k]<>q) and (d[k]<>hson[x]) then dfs2(d[k],d[k],x); k:=pre[k]; end; end;
一些线段树可行的操作
指的是树上查询,修改等操作
因为u和v之间的路径,其编号必定不是连续的,所以我们要一段段区间的查询;
其实就是两种情况
(1)点u和点v在同一条重链上
这种情况,因为是在同一条重链上,所以在线段树上必定表示为一段区间,所以直接查询(修改)
(2)点u和点v不在同一条重链上
我们尽量往重链上靠,查询(修改)当前点到其链头这段区间的值,然后跳到其链头的父亲。当然,我们优先跳两点的链头深度最大的,类似于LCA
while top[x]<>top[y] do//不在一条链上,情况(1) begin if dep[top[x]]<dep[top[y]] then swap(x,y);//优先跳 find(1,1,n,p[top[x]],p[x]);//查询(修改) x:=fa[top[x]]; end; if dep[x]>dep[y] then//以下都是情况(2) swap(x,y);
find(1,1,n,p[x],p[y]);
时间复杂度
学习每个算法最麻烦的就是算其时间复杂度了。乍一看会超时?可是有上面所写的性质,故效率为n log n级别的
O(mn log² n)(m表示修改查询次数)
推荐题目
学完一个算法,当然要练练手
• [ZJOI2008]树的统计 [ZJOI2008]树的统计
• SPOJ375 Query on a tree
• BZOJ2157 旅游