一. 中间件的简介
Django默认有七个中间件, 但是Django暴露给用户可以自定义中间件并且里面可以写五种方法
ps: 1.请求来的时候会依次执行每一个中间件里面的process_request方法(如果没有直接跳过)
2. 响应走的时候会依次执行每一个中间件里面的process_response方法(如果没有直接跳过)
Django的生命请求周期:
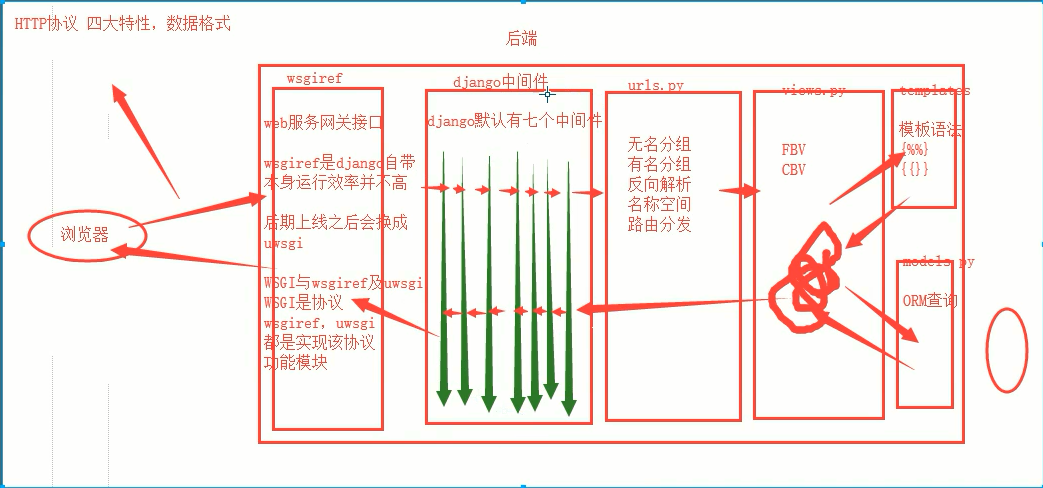
二. 中间件必掌握的知识点
上面我们已经知道可以自定义一个中间件,于是我们就马不停蹄的来创建一个,首先先了解下怎么去创建一个自定义的中间件,先在settings里面这样设置,因为我们不知道创建中间件所需要继承的父类,所以就要看下源码,那怎么看源码呢,就是我上面所说的在settings先这样复制一下
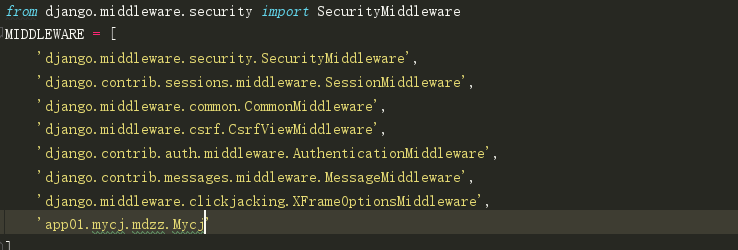
复制以上任意一个中间件,然后按最上面那种方式,前面加一个from, 中间添加一个import,这样就行了,然后用鼠标点击最后面的SecurityMiddleware,点进去就能看见这个是继承的哪个类,多话不说,我先创建一个类,看下图:
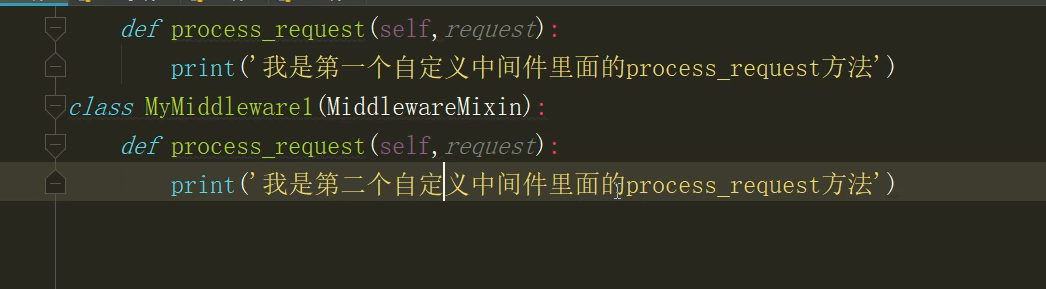
这就是我自定义的一个中间件,我们再视图函数写一个程序,运行结果如下:
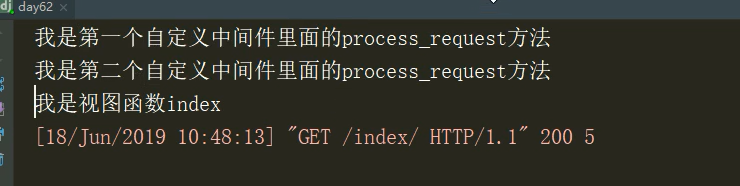
通过运行结果可以看出,不管怎么样,都首先是执行我自定义的中间件函数的,那我们如果在中间件里面返回一个HTTPresponse对象,那结果会如何呢,闲话不说,看下面图

结果又是什么样子的呢?看下图

看到上图你会想到什么?我擦,上面不是我们打印了好多函数么,怎么会只有一种输出结果,什么情况?来,听我给大家解释:还是看下面图
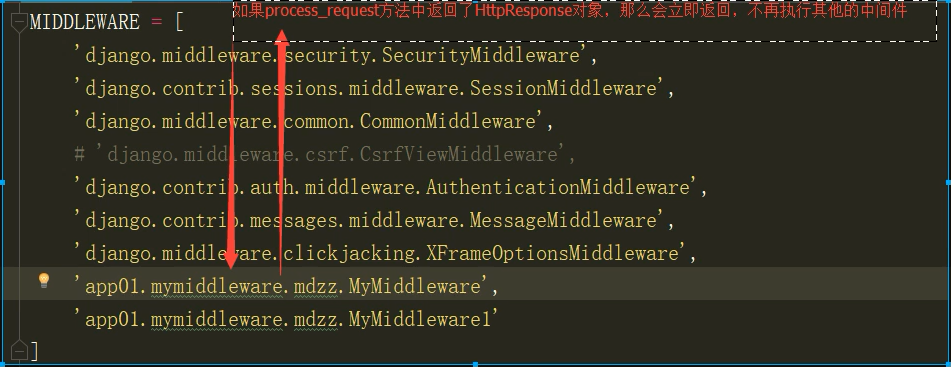
上面我们不是说执行顺序是依次往下执行的么,但是如果在process_request方法中返回了HTTPpresponse对象,那么就会立即返回,不在去执行其他的中间件
从这里可以看出Django中间件能够帮助我们实现网站全局的身份验证,黑名单,白名单, 访问频率限制,反爬相关,总之一句话,Django用来帮我们全局相关的功能校验
三. csrf跨站请求伪造
例子:钓鱼网站, 通过制作一个跟正儿八经的网站一模一样的页面,骗取用户输入信息,转账交易,从而做一些手脚,转账交易的请求确确实实的是发给了银行,账户的钱确实也少了,唯一不一样的地方就是收款人账户不一样.
内部原理:让用户输入对方账户的那个input上面做手脚,给这个input不设置name属性,在内部隐藏一个实现写好的name和value属性的input框,这个value的值就是钓鱼网站受益人账号
看下面例子:
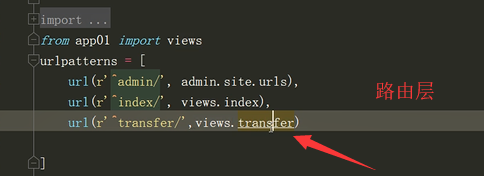
正经网站路由层
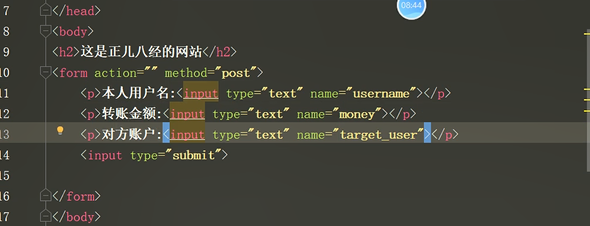
正经网站前端
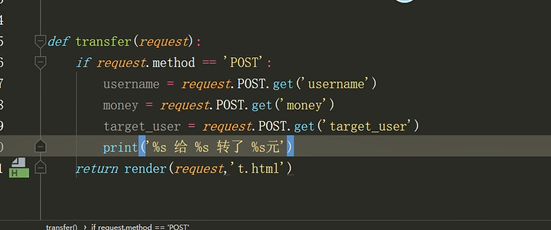
正经网站视图层
钓鱼端网页路由层:
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^transfer/', views.transfer),
钓鱼端网页视图层:
def transfer(request):
return render(request,'ttt.html')
钓鱼端网站前端代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<h2>这是钓鱼网站</h2>
<form action="http://127.0.0.1:8000/transfer/" method="post">
<p>本人用户名:<input type="text" name="username"></p>
<p>转账金额:<input type="text" name="money"></p>
<p>对方账户:<input type="text"></p> # 在这里不写name属性
<input type="text" name="target_user" value="jason" style="display: none"> # 重新在这边写一个input框,value值写成钓鱼网站受益人账号,然后进行隐藏
<input type="submit">
</form>
</body>
</html>

产生的结果
egon本来打算给攀少转钱,钓鱼网站做的样子跟正规网站的样子是一样的,egon粗心大意点进了一个钓鱼网站进行转账,结果egon账户的钱少了,攀少账户没有进钱,结果把钱全部转进制作钓鱼网站的Jason账户里, 那么这时候怎么办呢,没有办法,只能请求银行方面的进行技术支持,银行方面了解以后采取进一步的措施,采取的措施就是在form表单里加一个唯一标识,随机的字符串,下一次如果转账的话,程序就会自动带着这个唯一标识与转账的网站字符串进行对比,正确的话就可以进行转账,字符串不一样就会被拦截
具体解决方式: 在正规网站加一个{% csrf_token %}就可以解决这个 问题,下图是没有加这个标识之前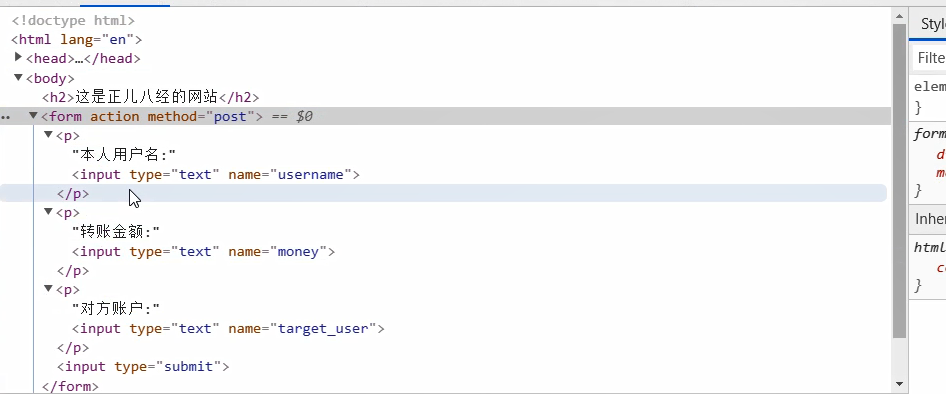
从这个图中可以看出只有三个光秃秃的input标签,其他的什么都么有.然后在看看下面加了标识之后的图片
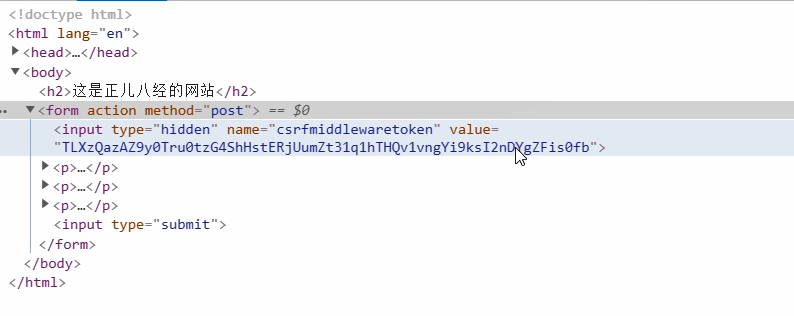
可以很明显的看出在第一个input框里有一个value值,随机的字符串,网页每刷新一次,就会产生有不同的字符串.
另外发送post请求的还有ajax请求,那么如何避免CSRF校验呢?我们这里有三种方法
1. 先在页面上写{% csrf_token %},利用标签查找, 获取到该input键值信息
2. 直接书写''{{ csrf_token}}''
3. 可以将该获取随机键值对的方法写到一个js文件中,之后导入该文件就行
分别是他们三个的书写方式:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<h2>这是正儿八经的网站</h2>
<form action="/lll/" method="post">
{# {% csrf_token %}#}
<p>本人用户名:<input type="text" name="username"></p>
<p>转账金额:<input type="text" name="money"></p>
<p>对方账户:<input type="text" name="target_user"></p>
<input type="submit">
</form>
<button id="b1">发送ajax请求</button>
{% load static %}
<script src="{% static 'setjs.js' %}"></script>
<script>
$('#b1').click(function () {
$.ajax({
url:'',
type:'post',
// 第一种方式
data:{'username':'jason','csrfmiddlewaretoken':$('[name=csrfmiddlewaretoken]').val()},
// 第二种方式#}
data:{'username':'jason','csrfmiddlewaretoken':'{{ csrf_token }}'
// 第三种方式 :直接引入js文件
data:{'username':'jason'},
success:function (data) {
alert(data)
}
})
{})
</script>
</body>
</html>
第三种方式在写的时候要引入js静态文件,我们只需建一个'static'静态文件加,将下面的代码复制在这个文件夹下的js文件里面
function getCookie(name) {
var cookieValue = null;
if (document.cookie && document.cookie !== '') {
var cookies = document.cookie.split(';');
for (var i = 0; i < cookies.length; i++) {
var cookie = jQuery.trim(cookies[i]);
// Does this cookie string begin with the name we want?
if (cookie.substring(0, name.length + 1) === (name + '=')) {
cookieValue = decodeURIComponent(cookie.substring(name.length + 1));
break;
}
}
}
return cookieValue;
}
var csrftoken = getCookie('csrftoken');
跨站请求伪造装饰器:
我们现在把settings里面的csrf配置打开了,意味着什么呢,所有的网站请求都得去校验, 那我现在有这么一个需求, 我想让某一个视图函数不进行校验,该如何处理呢, 还有一个需求就是,当网站全局不校验csrf的时候,有几个需要校验又是该如何处理呢,假如我想让login不进行校验呢,这个时候呢就要用它内部的装饰器,他可以装饰那些不需要校验,那些需要校验,导入模块
from django.views.decorators.csrf import csrf_exempt,csrf_protect
上面导入的是一个保护,一个不保护,假如我们想让login不校验,就给他装饰一个@scrf_exempt,这样的话login就不会再校验csrf了, 这个意思就是说当我的所有网站进行校验的时候我不想让某个视图函数校验就用@csrf_exempt来进行装饰,那么我们刚开始问题上说如果全局都不校验,我想让某个视图函数进行校验时,就用装饰器@csrf_protect来进行装饰,这种情况是针对FBVl来解决的,CBV的话就有点门道了,来,例子进行简单说明一下,,,,,
from django.views.decorators.csrf import csrf_exempt,csrf_protect
from django.utils.decorators import method_decorator # 固定的方法装饰器,来专门帮助我们装饰CBV这种形式的
# 第一种方式
# @method_decorator(csrf_protect,name='post') # 有效的
# @method_decorator(csrf_exempt,name='post') # 无效的
@method_decorator(csrf_exempt,name='dispatch') # 第二种可以不校验的方式
class MyView(View):
# @method_decorator(csrf_exempt) # 第一种可以不校验的方式
@method_decorator(csrf_protect)
def dispatch(self, request, *args, **kwargs):
res = super().dispatch(request, *args, **kwargs)
return res
def get(self,request):
return HttpResponse('get')
# 第二种方式
# @method_decorator(csrf_exempt) # 无效的
# @method_decorator(csrf_protect) # 有效的
def post(self,request):
return HttpResponse('post')
总结: 总结 装饰器中只有csrf_exempt是特例,其他的装饰器在给CBV装饰的时候 都可以有三种方式
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect # 这两个装饰器在给CBV装饰的时候 有一定的区别 如果是csrf_protect 那么有三种方式 # 第一种方式 # @method_decorator(csrf_protect,name='post') # 有效的 class MyView(View): # 第三种方式 # @method_decorator(csrf_protect) def dispatch(self, request, *args, **kwargs): res = super().dispatch(request, *args, **kwargs) return res def get(self,request): return HttpResponse('get') # 第二种方式 # @method_decorator(csrf_protect) # 有效的 def post(self,request): return HttpResponse('post') 如果是csrf_exempt 只有两种(只能给dispatch装) 特例 @method_decorator(csrf_exempt,name='dispatch') # 第二种可以不校验的方式 class MyView(View): # @method_decorator(csrf_exempt) # 第一种可以不校验的方式 def dispatch(self, request, *args, **kwargs): res = super().dispatch(request, *args, **kwargs) return res def get(self,request): return HttpResponse('get') def post(self,request): return HttpResponse('post')
四. auth模块
如果在开发过程中用auth,就要用auth的全套,所有的方法都是一套,用户的都是一套.
跟用户相关的功能模块, 用户的注册, 登录, 验证, 修改密码等等
执行数据库迁移命令之后,会生成很多表,其中的auth_user是一张用户相关的表格
添加数据:
createssuperuser 创建超级用户, 这个超级用户就可以拥有Django admin后台管理的权限
我们先创建一个用户,先进行登录
后端代码:
from django.contrib import auth
def xxx(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
# 取数据库查询当前用户数据
# models.User.objects.filter(username=username,password=password).first() # 不能用这种方式进行查询,因为在这里获取的密码是明文,而数据库中的密码是密文,这样查询的话查到海枯石烂,雷峰塔倒都查询不到,而且现在的这张表不是models里面的,是auth模块里面的
user_obj = auth.authenticate(username=username,password=password) # 必须要用 因为数据库中的密码字段是密文的 而你获取的用户输入的是明文,这句话就相当于上面models.User.objects.filter(username=username,password=password).first()的意思
print(user_obj) # 打印出的是一个对象,内部置有__str__方法
# print(user_obj)
# print(user_obj.username)
# print(user_obj.password) # 打印出的是一个密文
# 保存用户状态
# request.session['user'] = user_obj
auth.login(request,user_obj) # 将用户状态记录到session中
"""只要执行了这一句话 就可以在后端任意位置通过request.user获取到当前用户对象"""
return render(request,'xxx.html')
如果用户没有进行登录,我们用request.user打印出的结果不是一个对象,也不是一个none,而是一个匿名用户AnonymousUser
判断用户是否登录:
后端代码:
def yyy(request):
print(request.user) # 如果没有执行auth.login那么拿到的是匿名用户
print(request.user.is_authenticated) # 判断用户是否登录 如果是匿名用户会返回False,如果是用户对象就会返回一个True
return HttpResponse('yyy')
修改密码:
后端代码:
from django.contrib.auth.decorators import login_required # auth帮我们提供的 # 修改用户密码 @login_required # 自动校验当前用户是否登录 如果没有登录 默认跳转到 一个莫名其妙的登陆页面
# login_required(login_url='')可以跳转到我自己的页面,这样是局部配置,还可以在全局配置,如果不在全局配置的话,再增加一个功能时,我们还得手动添加 def set_password(request): if request.method == 'POST': old_password = request.POST.get('old_password') new_password = request.POST.get('new_password') # 先判断原密码是否正确 is_right = request.user.check_password(old_password) # 将获取的用户密码 自动加密 然后去数据库中对比当前用户的密码是否一致 if is_right: print(is_right) # 打印True或者false # 修改密码 request.user.set_password(new_password) request.user.save() # 修改密码的时候 一定要save保存 否则无法生效 return render(request,'set_password.html')
在settings里面的随意的地方,写LOGIN_URL = 'XXX',这个xxx就是我们自己网站的路由,我们想登陆之后跳到那个页面,就写哪个路由,如果在settings里面配置了以后就不要在视图函数中的@login_requred(login_url='')括号里面的
前端代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
</head>
<body>
<form action="" method="post">
{% csrf_token %}
<p>username:<input type="text" name="username" value="{{ request.user.username }}" disabled></p> //这样操作的话用户就只能改密码了
<p>old_password:<input type="password" name="old_password"></p>
<p>new_password:<input type="password" name="new_password"></p>
<input type="submit">
</form>
</body>
</html>
注销功能:
@login_required
def logout(request):
# request.session.flush() # session的注销方法
auth.logout(request)
return HttpResponse("logout")
注册功能:
from django.contrib.auth.models import User
def register(request):
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
user_obj = User.objects.filter(username=username)
if not user_obj:
# User.objects.create(username =username,password=password) # 针对auth模块,平时用模型层的时候我们还可以用create的,创建用户名的时候 千万不要再使用create 了,这样创建的话密码在数据库里面是个明文
# User.objects.create_user(username =username,password=password) # 创建普通用户
User.objects.create_superuser(username =username,password=password,email='123@qq.com') # 创建超级用户 ,邮箱是必填的
return render(request,'register.html')
五. auth自定义用户表
比如我们想在原来数据库表中另外添加字段,我们可以在models里面创建重新创建一个表,可以使用类的继承的方法,我们不在继承models.Model而是使用AbstractUser
from django.contrib.auth.models import AbstractUser
# 第一种 使用一对一关系 不考虑
# 第二种方式 使用类的继承
class Userinfo(AbstractUser):
# 千万不要跟原来表中的字段重复 只能创新
phone = models.BigIntegerField()
avatar = models.CharField(max_length=32)
在这里,建好表以后,要去settings里面告诉Django orm不再使用auth默认的表,而是自定义的表, AUTH_USER_MODEL='app01.Userinfo' 就是'应用名.模型层中的类名', 在新建的表中不再有原来数据库表中auth_user,而是我们新建的auth_userinfo,在这个userinfo里面,字段名比原来数据库中字段名多了两个字段名,这两个也就是我们新建的phone,avatar两个字段,新增的两个字段拥有原来表中字段的所有功能,和原来表中的字段的功能都是一样的.
额外的思想,基于Django中间件思想实现功能插拔式配置
要求: 开发一个基于微信,短信,qq的通知功能
第一种方式:函数式版本:
def wechat(content):
print('微信通知:%s'%content)
def msg(content):
print('短信通知:%s'%content)
def email(content):
print('邮件通知:%s'%content)
from lowb版本.notify import *
def run(content):
wechat(content)
msg(content)
email(content)
if __name__ == '__main__':
run('国庆八天假 我该去哪玩?')
第二种方式:参照Django中间件的方式,把所有的功能都写成配置文件的形式,一旦这个功能不用了,就将这个功能注释掉就行,不瞎鸡儿动,只动一个地方就行.先建一个文件夹notify,再根据功能的不同建不同的py文件,email.py. msg.py, wechat.py 这三个统一秉承Python的鸭子类型机制,写成类的形式,在每个类中定义一个方法send.
__init__文件
import settings
import importlib
def send_all(content):
for path_str in settings.NOTIFY_LIST: # 1.拿出一个个的字符串 'notify.email.Email'
module_path,class_name = path_str.rsplit('.',maxsplit=1) # 2.从右边开始 按照点切一个 ['notify.email','Email']
module = importlib.import_module(module_path) # from notity import msg,email,wechat
cls = getattr(module,class_name) # 利用反射 一切皆对象的思想 从文件中获取属性或者方法 cls = 一个个的类名
obj = cls() # 类实例化生成对象
obj.send(content) # 对象调方法
importlib.import_module(name, package=None)-
导入一个模块。参数 name 指定了以绝对或相对导入方式导入什么模块 (比如要么像这样
pkg.mod或者这样..mod)。如果参数 name 使用相对导入的方式来指定,那么那个参数 packages 必须设置为那个包名,这个包名作为解析这个包名的锚点 (比如import_module('..mod', 'pkg.subpkg')将会导入pkg.mod)。import_module()函数是一个对importlib.__import__()进行简化的包装器。 这意味着该函数的所有主义都来自于importlib.__import__()。 这两个函数之间最重要的不同点在于import_module()返回指定的包或模块 (例如pkg.mod),而__import__()返回最高层级的包或模块 (例如pkg)。如果动态导入一个自从解释器开始执行以来被创建的模块(即创建了一个 Python 源代码文件),为了让导入系统知道这个新模块,可能需要调用
invalidate_caches()。在 3.3 版更改: 父包会被自动导入。
importlib.find_loader(name, path=None)-
查找一个模块的加载器,可选择地在指定的 path 里面。如果这个模块是在
sys.modules,那么返回sys.modules[name].__loader__(除非这个加载器是None或者是没有被设置, 在这样的情况下,会引起ValueError异常)。 否则使用sys.meta_path的一次搜索就结束。如果未发现加载器,则返回None。点状的名称没有使得它父包或模块隐式地导入,因为它需要加载它们并且可能不需要。为了适当地导入一个子模块,需要导入子模块的所有父包并且使用正确的参数提供给 path。
3.3 新版功能.
在 3.4 版更改: 如果没有设置
__loader__,会引起ValueError异常,就像属性设置为None的时候一样。3.4 版后已移除: 使用
importlib.util.find_spec()来代替。
importlib.invalidate_caches()-
使查找器存储在
sys.meta_path中的内部缓存无效。如果一个查找器实现了invalidate_caches(),那么它会被调用来执行那个无效过程。 如果创建/安装任何模块,同时正在运行的程序是为了保证所有的查找器知道新模块的存在,那么应该调用这个函数
email文件
class Email(object):
def __init__(self):
pass # 发送邮件需要的代码配置
def send(self,content):
print('邮件通知:%s'%content)
msg文件
class Msg(object):
def __init__(self):
pass # 发送短信需要的代码配置
def send(self,content):
print('短信通知:%s' % content)
qq文件:
class QQ(object):
def __init__(self):
pass # 发送qq需要的代码准备
def send(self,content):
print('qq通知:%s'%content)
WeChat文件
class WeChat(object):
def __init__(self):
pass # 发送微信需要的代码配置
def send(self,content):
print('微信通知:%s'%content)
settings的配置
NOTIFY_LIST = [ 'notify.email.Email', 'notify.msg.Msg', 'notify.wechat.WeChat', 'notify.qq.QQ', ]
这里面相当于一个个路径
start文件
import notify
notify.send_all('国庆放假了 记住放八天哦')