创建测试表:
CREATE TABLE `animal` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) COLLATE utf8_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; INSERT INTO `boot`.`animal` (`id`, `name`, `age`) VALUES ('1', 'cat', '12'); INSERT INTO `boot`.`animal` (`id`, `name`, `age`) VALUES ('2', 'dog', '13'); INSERT INTO `boot`.`animal` (`id`, `name`, `age`) VALUES ('3', 'camel', '25'); INSERT INTO `boot`.`animal` (`id`, `name`, `age`) VALUES ('4', 'cat', '32'); INSERT INTO `boot`.`animal` (`id`, `name`, `age`) VALUES ('5', 'dog', '42');
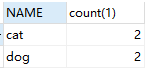
1.查看重复name及条数
SELECT NAME, count(1) FROM animal GROUP BY NAME HAVING count(1) > 1;
直接删除:
DELETE -- select * FROM animal WHERE NAME IN ( SELECT NAME FROM animal GROUP BY NAME HAVING count(1) > 1 )
会报错 [Err] 1093 - You can't specify target table 'animal' for update in FROM clause
不能先select出同一表中的某些值,再update这个表(在同一语句中)
原因是:更新这个表的同时又查询了这个表,查询这个表的同时又去更新了这个表,可以理解为死锁。mysql不支持这种更新查询同一张表的操作
2.解决办法:把要删除的数据查询出来做为一个第三方表,然后再删除。
DELETE -- select * FROM animal WHERE NAME IN ( SELECT t.NAME FROM ( SELECT NAME FROM animal GROUP BY NAME HAVING count(1) > 1 ) t )
3.删除表中删除重复数据,仅保留一条
通过name分组,查出id最小的数据,这些数据就是要留下,那么再查询出id不在这里面的,就是要删除的重复数据。
DELETE -- SELECT * FROM animal WHERE id NOT IN ( SELECT t.id FROM ( SELECT MIN(id) AS id FROM animal GROUP BY `name` ) t )