1:索引(创建或者删除)一个文档
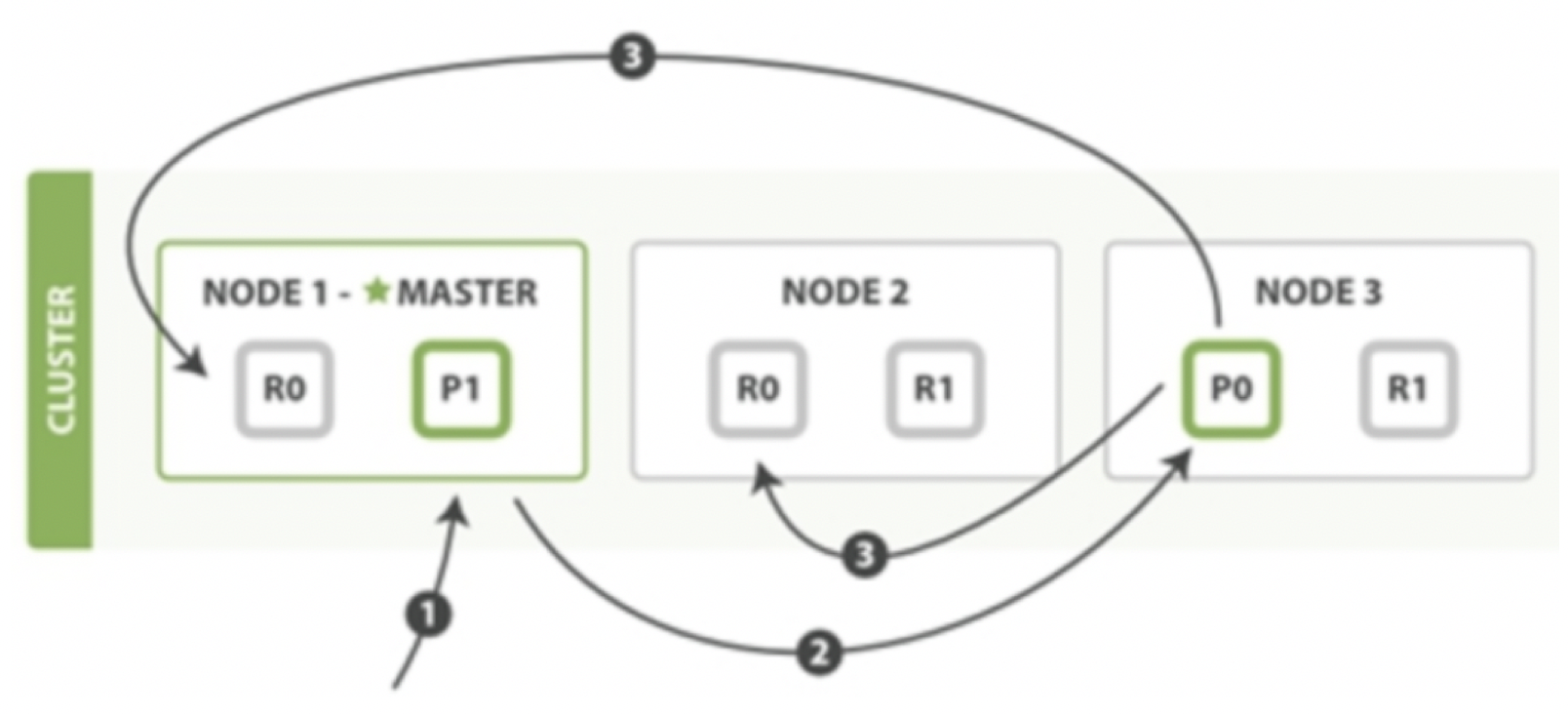
首先:发送一个索引或者删除的请求给node1
其次:node1接收到请求之后,会根据请求中携带的参数“文档id”判断出该文档应该存储在具体哪一个shard中
shard = hash(routing) % number_of_primary_shards
,比如shard0;其次就是node1通过元数据信息可以知道shard0在具体哪一个节点,于是node1会把请求转发给node3
最后:node3接收到请求之后会将请求并行的分发给shard0的所有replica shard之上,也就是存在于node 1和node 2中的replica shard;如果所有的replica shard都成功地执行了请求,那么将会向node 3回复一个成功确认,当node 3收到了所有replica shard的确认信息后,则最后向用户返回一个Success的消息。
2:删除一个文档

该过程可以分为四个阶段来描述: 阶段1:客户端向node 1发送一个文档删除的请求。 阶段2:同样的node 1通过请求中文档的 _id 值判断出该文档应该被存储在shard 0 这个分片中,并且node 1知道shard 0的primary shard位于node 3这个节点上。因此node 1会把这个请求转发到node 3。 阶段3:node 3接收到请求后,在主分片上面执行删除请求 阶段4:如果node 3成功地删除了文档,node 3将会请求并行地发给其余所有的replica shard所在node中。这些node也同样操作删除,执行后则向node 3确认成功,当node 3接收到所有的成功确认之后,再向客户端发送一个删除成功的信息。
3:检索文档

检索文档的时候,我们并不知道文档在集群中的哪个位置,所以一般情况下不得不去询问index中的每一个shard,然后将结果拼接成一个大的已排好序的汇总结果列表;
(1):客户端发送一个检索请求给node3,此时node3会创建一个空的优先级队列并且配置好分页参数from与size。
(2):node3将检所请求发送给index中的每一个shard(primary 和 replica),每一个在本地执行检索,并将结果添加到本地的优先级队列中;
(3):每个shard返回本地优先级序列中所记录的_id与score值,并发送node3。Node3将这些值合并到自己的本地的优先级队列中,并做全局的排序(node 3将它们合并成一条汇总的结果),返回给客户端。
列子:
1):构建测试数据:
PUT website/blog/1
{
"title" : "this is title",
"conteng" : "this is content"
}
PUT website/blog/2
{
"title" : "thi title",
"conteng" : "thi content"
}
PUT website/blog/3
{
"title" : "thitle",
"conteng" : "thontent"
}
PUT website/blog/4
{
"title" : "aaa",
"conteng" : "aaaaa"
}
PUT website/blog/5
{
"title" : "bbbbb",
"conteng" : "cccccc"
}
PUT website/blog/6
{
"title" : "e",
"conteng" : "ssss"
}
PUT website/blog/7
{
"title" : "this title",
"conteng" : "thi content"
}
在最初的查询过程中,查询请求会广播到index中的每一个primary shard和replica shard中,每一个shard会在本地执行检索,并建立一个优先级队列(priority queue)。这个优先级队列是一个根据文档匹配度这个指标所排序列表,列表的长度由分页参数from和size两个参数所决定
GET website/_search
{
"query": {
"match": {
"title": "this"
}
}
}