在部署完了高可用的集群的基础上,开始对目前的集群做一次小开发,练练手。
我的开发环境在Windows 10 64位的机器上,因此需要针对Windows的开发环境进行前期准备。
保证Windows系统上安装了java
将hadoop/share/hadoop目录下的有关jar包全部拷贝至同目录下
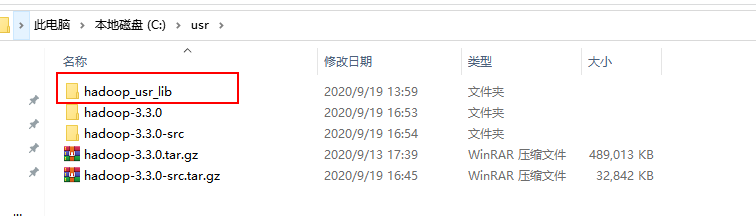
将此目录放置在一个干净的目录【无特殊字符、无中文等】下,为了以后导包使用建议该文件目录命名为:hadoop_usr_lib。
同时将hadoop源码包和二进制包同时解压到同一目录下,方便管理。
我将此目录放置在c:/usr目录下。
3、配置hadoop在windows下的环境
(1)由于Hadoop的二进制包的运行对于Linux系统环境比较友好,对Windows并不太友好,因此为了能够使得Hadoop能够始应Windows环境,我们需要在Github上下载有关Hadoop的第三方工具,名为winutils的一套类库。下载链接:https://github.com/kontext-tech/winutils,找到对应版本并下载。这里,我们使用的是Hadoop-3.3.0版本。
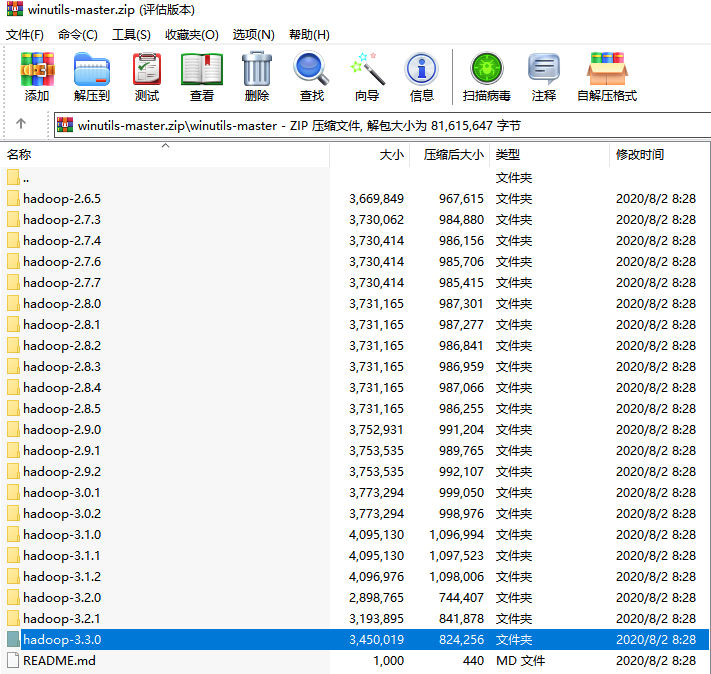
(2)下载好之后,找到对应版本,打开并将bin目录下的文件覆盖原Hadoop的二进制目录下的bin目录中。
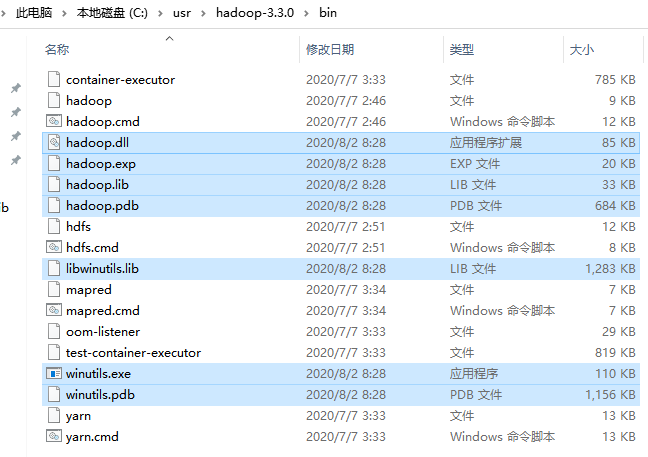
(3)然后将hadoop.dll放到系统的动态链接库的文件中,即:C:WindowsSystem32

重启电脑,保证链接生效
(4)然后设置Hadoop的环境变量
在系统环境变量中添加HADOOP_HOME,具体如下:

然后将其bin目录添加至系统path中,具体如下:

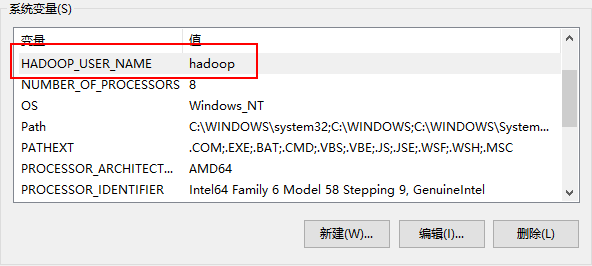
最后添加HADOOP_USER_NAME变量,具体如下:
4、在idea下配置Hadoop开发环境以及连接插件
打开idea,新建一个项目,我创建了一个纯Java项目,仅用于练习Hadoop-HDFS的API的开发小实战以及后续的MR小实战。在实际的开发生产中,绝对不建议使用纯Java项目开发Hadoop,这样做太蠢了。。。好了,我们继续。
(1)导入之前我们创建好的Jar包目录到idea开发路径中。
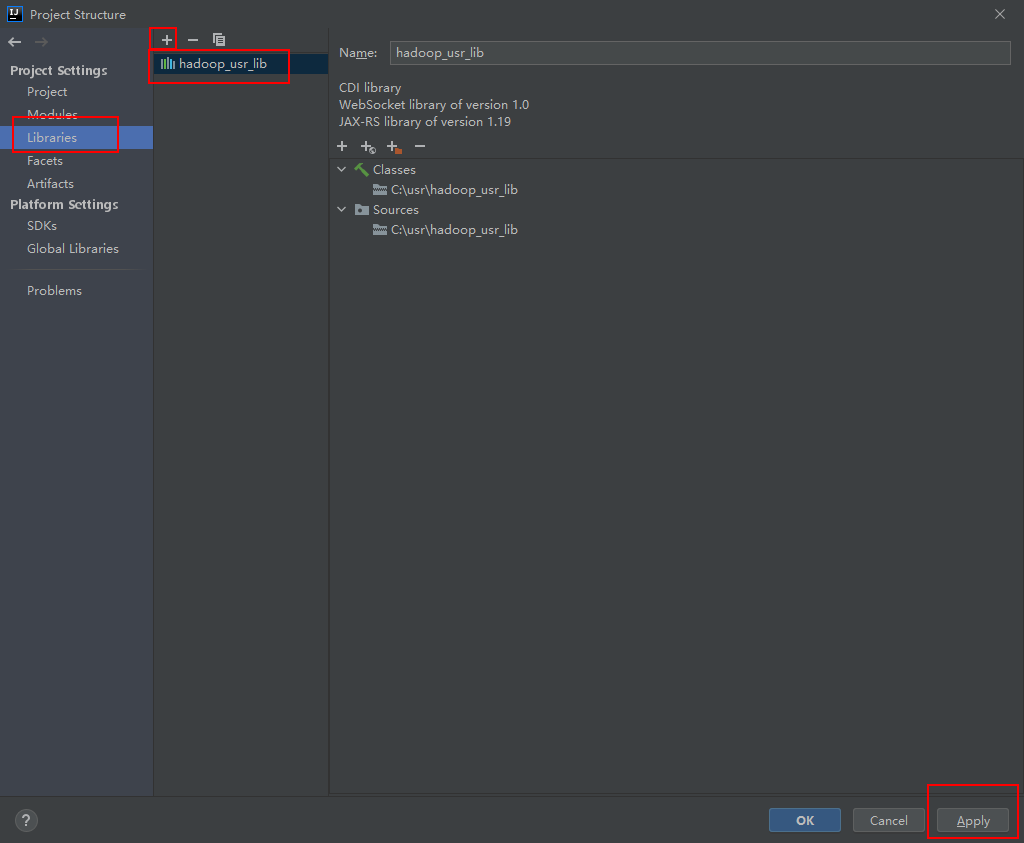
在File下,点击Project Structure,然后选择Libraries,点击“+”添加之前的hadoop_usr_lib
(2)下载针对idea的hadoop插件,有两种插件可以选择,一个是GitHub上的一个开源插件,地址为:https://github.com/fangyuzhong2016/HadoopIntellijPlugin。另一个是idea上的官方插件,叫做big data tools。
当然,我采用第二个插件。
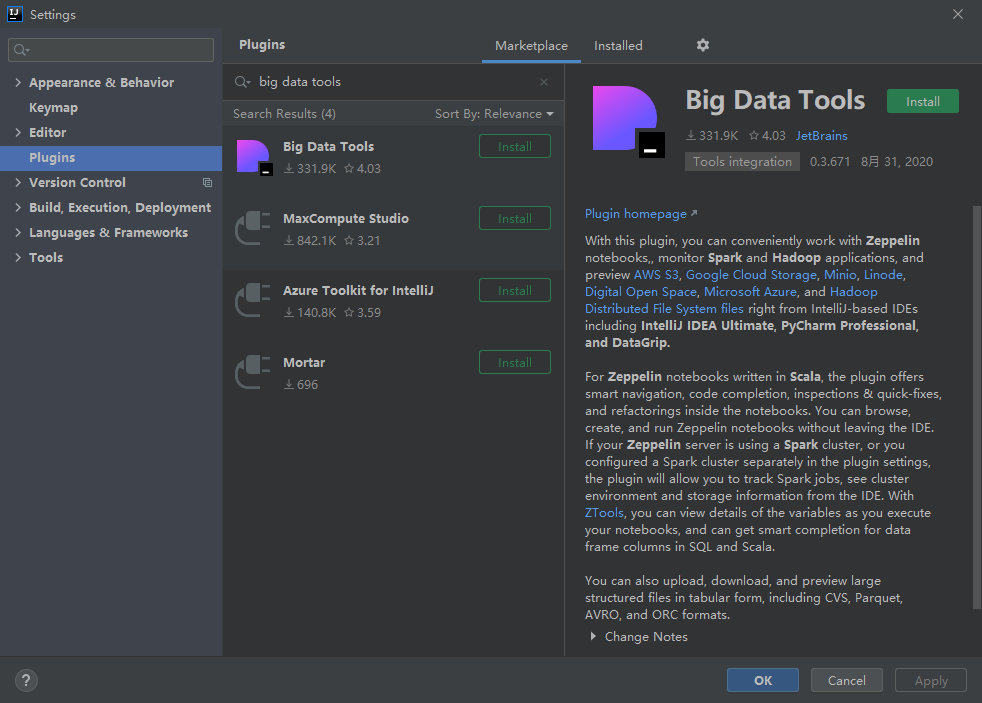
安装即可。当然,认为下载很慢的话,可以进入如下地址自行下载:https://plugins.jetbrains.com/plugin/12494-big-data-tools/versions
下载好之后,根据下图顺序进行操作,安装插件。
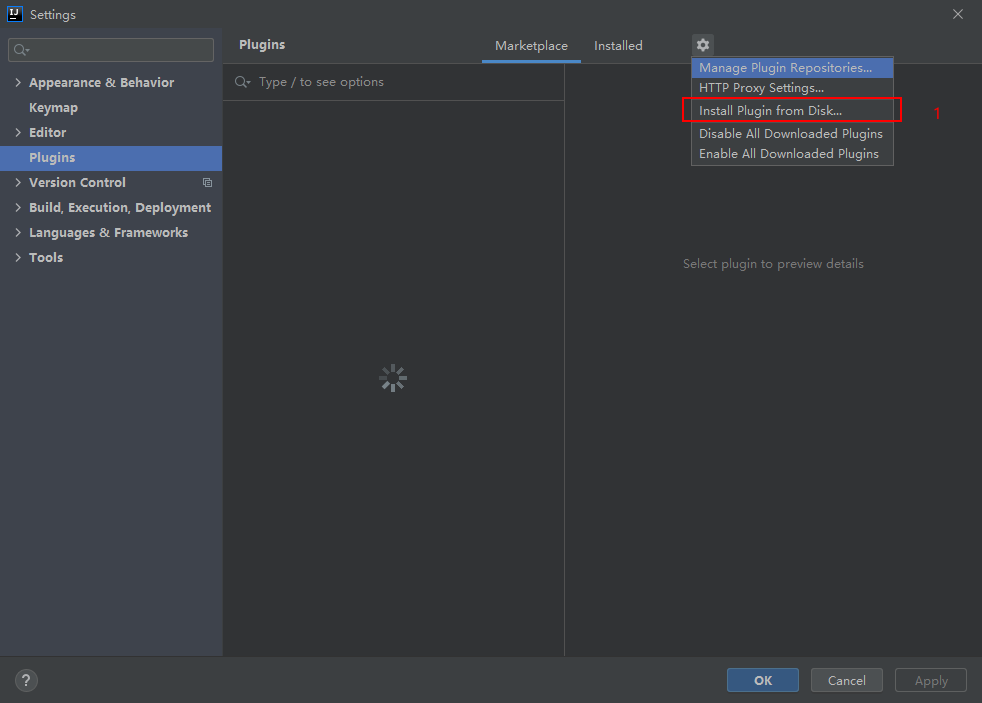
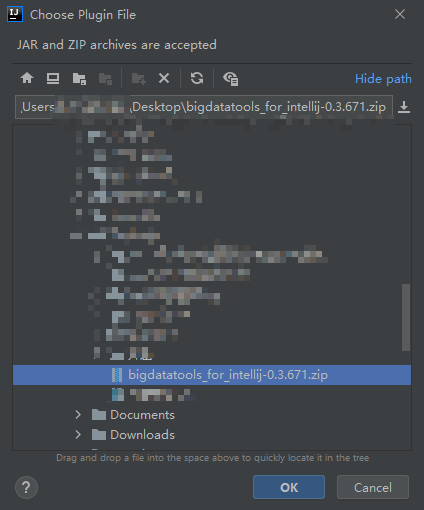
然后点击ok,进行安装,可能需要一点时间,然后有提示重启IDE即可。
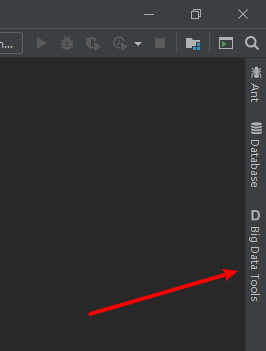
在重启后,能看到IDE的右边侧栏有Big Data Tools的选项。
(3)使用插件,连接hadoop的HDFS服务
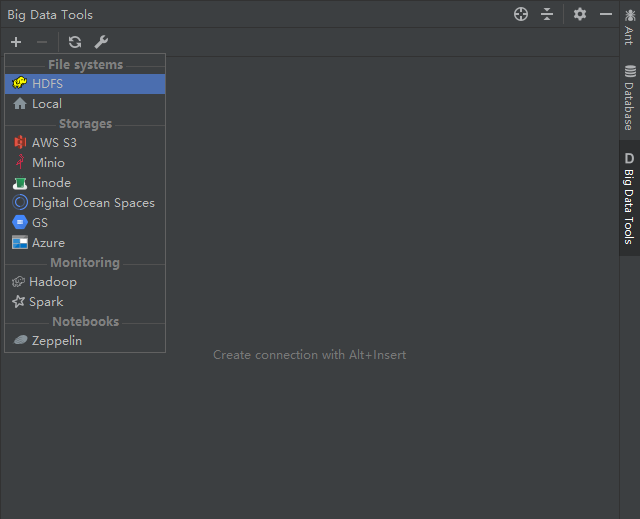
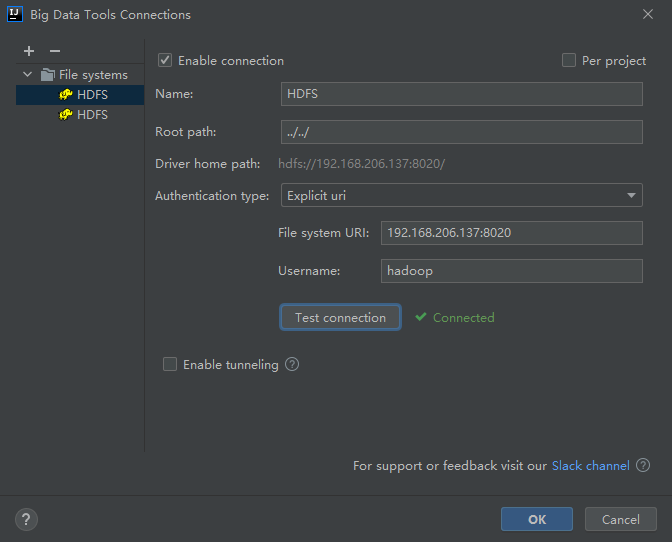
这里选择HDFS,然后配置,测试连接(首先确定哪个namenode是出于active的状态!)
然后就可以使用idea的工具进行文件操作了。当然这一步可以省略,使用hadoop给的可视化界面进行文件操作也是可以的。
5、在idea下开发Hadoop的API
(1)首先,需要在根目录下,创建conf文件目录,用于存储hadoop的配置文件,目的是告知程序namenode的位置。
(2)创建ha子目录,用于存放ha的集群配置。当然,可以创建其他的子目录,用于存放其他的集群配置,便于灵活切换。
(3)在服务器上把core-site.xml和hdfs-site.xml两个文件拉去下来,然后放置在ha目录下
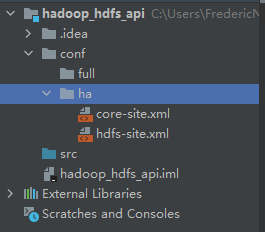
(4)将ha目录作为根目录配置
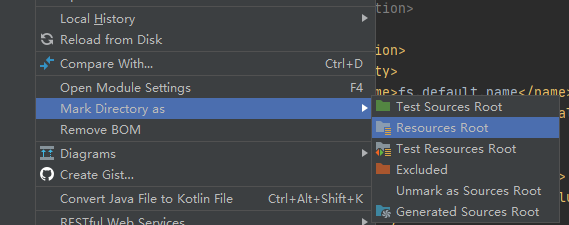
(5)创建包,类,开始编写API。
编写的具体代码如下:
package com.test.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import java.io.*; class HdfsApi { Configuration conf; //hadoop提供的一个配置类,专门用于读取配置 FileSystem fs; public void Conn() throws Exception { /** * 这是连接器函数,针对hdfs的连接 */ conf = new Configuration(true);//为true,会执行读取我们在ha下面的配置文件 fs = FileSystem.get(conf); //根据配置文件,返回对应的实例对象 } public void Close() throws Exception { /** * 这是连接关闭函数,针对hdfs的关闭 */ fs.close(); } public void MakeDir() throws Exception { /** * 这是在hdfs中创建目录的API */ Path iFile = new Path("/testApi"); if (fs.exists(iFile)){ fs.delete(iFile,true);//true,递归删除 } fs.mkdirs(iFile); } public void upload() throws Exception { /** * 这是一个上传接口,用于将文件上传至hdfs */ Path f = new Path("/testApi/testUploadFile.txt"); FSDataOutputStream output = fs.create(f);// 返回对象快捷键:ctrl+alt+v InputStream input = new BufferedInputStream(new FileInputStream(new File("C:\usr/test_for_hadoop_hdfs_api.txt"))); IOUtils.copyBytes(input,output,conf,true); //hadoop的工具类,里面有按字符拷贝的函数,最后自动关闭流,无需人为操作。 } public void download() throws Exception { /** * 这是一个下载接口,用于从hdfs将文件下载至本地 */ Path f = new Path("/testApi/testUploadFile.txt"); OutputStream output = new BufferedOutputStream(new FileOutputStream(new File("C:\usr/test_download.txt"))); FSDataInputStream input = fs.open(f); IOUtils.copyBytes(input,output,conf,true); } public void GetFileBlocks() throws Exception { /** * 获取文件的块的信息 */ Path path = new Path("/testApi/testUploadFile.txt"); FileStatus iFile = fs.getFileStatus(path); BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(iFile, 0, iFile.getLen()); for (BlockLocation b : fileBlockLocations) { System.out.println(b); } } }
对上述代码进行单元测试,生成单元测试代码如下:
package test.com.test.hadoop.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org.apache.hadoop.io.IOUtils; import org.junit.Test; import org.junit.Before; import org.junit.After; import java.io.*; /** * HdfsApi Tester. * * @author <Authors name> * @since <pre>9月 20, 2020</pre> * @version 1.0 */ public class HdfsApiTest { Configuration conf; //hadoop提供的一个配置类,专门用于读取配置 FileSystem fs; @Before public void before() throws Exception { conf = new Configuration(true);//为true,会执行读取我们在ha下面的配置文件 fs = FileSystem.get(conf); //根据配置文件,返回对应的实例对象 } @After public void after() throws Exception { fs.close(); } /** * Method: Conn() */ @Test public void testConn() throws Exception { //TODO: Test goes here... } /** * Method: Close() */ @Test public void testClose() throws Exception { //TODO: Test goes here... } /** * Method: MakeDir() */ @Test public void testMakeDir() throws Exception { //TODO: Test goes here... Path iFile = new Path("/testApi"); if (fs.exists(iFile)){ fs.delete(iFile,true);//true,递归删除 } fs.mkdirs(iFile); } /** * Method: upload() */ @Test public void testUpload() throws Exception { //TODO: Test goes here... Path f = new Path("/testApi/testUploadFile.txt"); FSDataOutputStream output = fs.create(f);// 返回对象快捷键:ctrl+alt+v InputStream input = new BufferedInputStream(new FileInputStream(new File("C:\usr/test_for_hadoop_hdfs_api.txt"))); IOUtils.copyBytes(input,output,conf,true); //hadoop的工具类,里面有按字符拷贝的函数,最后自动关闭流,无需人为操作。 } /** * Method: download() */ @Test public void testDownload() throws Exception { //TODO: Test goes here... Path f = new Path("/testApi/testUploadFile.txt"); OutputStream output = new BufferedOutputStream(new FileOutputStream(new File("C:\usr/test_download.txt"))); FSDataInputStream input = fs.open(f); IOUtils.copyBytes(input,output,conf,true); } /** * Method: GetFileBlocks() */ @Test public void testGetFileBlocks() throws Exception { //TODO: Test goes here... Path path = new Path("/testApi/testUploadFile.txt"); FileStatus iFile = fs.getFileStatus(path); BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(iFile, 0, iFile.getLen()); for (BlockLocation b : fileBlockLocations) { System.out.println(b); } } }
以上函数单元测试均通过,到这里一个简单的HDFS的编码小实战结束。不过需要注意的是,hdfs有很多的接口函数,需要搞清楚其内部逻辑才能更好地使用这个分布式文件系统为生产环境服务!
