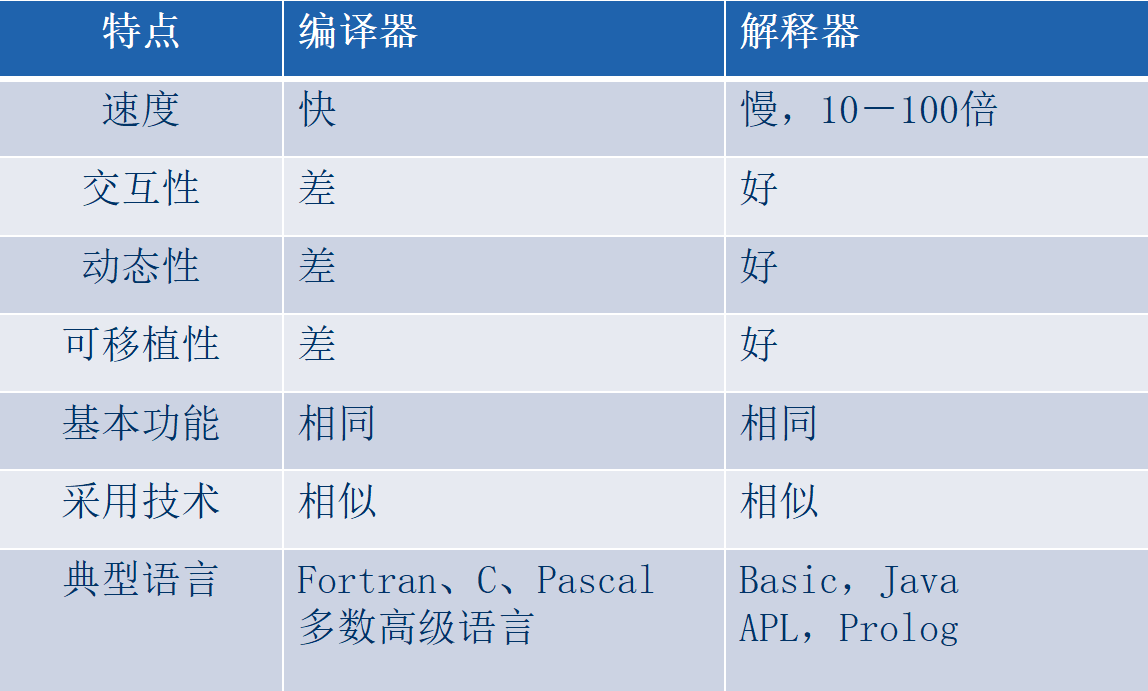
编译器与解释器:
1)编译器的重要任务之一是报告在编译过程中发现的源程序中的错误。倘若目标程序是一个可执行的程序,那么它将可以被调用。(这意味着目标程序很可能不可在机器上直接执行)
2)解释器是另一种常见的语言处理器,它并不通过编译的方式生成目标程序。解释器直接解释源程序,执行相关的操作。
VS:
从运行时间上来讲,从用户输入到处理得到输出结果,执行编译后的目标程序比用解释器解释源程序要快许多。
从交互与动态性上来讲,解释器,由于是一条一条解释执行的,所以它的错误诊断效果比编译的效果要好。
Java 混合编译器,结合了编译器和解释器。Java的源程序首先经编译器被编译为字节码(中间表示形式),然后虚拟机对字节码加以解释执行。
即时编译器:有些Java编译器,会把字节码编译为机器语言,然后在执行程序。
除了编译器外,语言处理系统还有:
预处理器:聚合多个源程序,翻译宏指令;
汇编器:处理编译器生成的汇编语言目标程序,生成可重定位的机器代码。
链接器:连接多个可重定位的目标文件和库文件,处理外部内存地址;
加载器:将所有可执行文件放在内存中执行。
一个源程序可能被分为多个模块,并存于独立的文件中。把源程序聚合在一起的工作有时会由预处理器担任,同时,它还会把被称为宏的缩写形式转换为语言的的语句。
然后传到编译器中,产生一个汇编语言程序作为输出,因为,汇编语言比较容易输出和测试;接着,这个程序传至汇编器中,汇编器进行处理,生成可重定位的机器代码。
大型程序经常被分为几个部分进行编译,因此可重定位的机器代码有必要和其他可重定位的文件以及库文件连接到一起,形成真正在机器上运行的代码;一个文件中的代码可能指向另一个文件的位置,而链接器可以解决外部内存地址问题。
继续介绍编译器~~~
编译器能够把源程序转换为在语义上等价的目标出现。映射过程分为两个部分:分析部分和综合部分。
1)分析部分(前端):把源程序分解为多个组成要素,并在这些要素上加上语法结构,用建立的语法结构创建源程序的中间表示形式,检查并报告语法和语义错误,收集源程序的有关信息,并把他们放在符号表中,把中间表示形式和符号表一起传送给综合部分。
分析部分分为三个阶段/步骤:词法分析、语法分析、语义分析;
2)综合部份(后端):根据符号表和中间表示形式创建用户期待的目标代码。
综合部分分为三个阶段/步骤:中间代码产生、代码优化、生成机器代码;
前端与源语言有关,与机器语言无关;后端与源语言无关,与机器语言有关。
综上:编译过程分为六个/五个阶段/步骤:
每个步骤把源语言的一种表示形式转换为另一种。
如图:
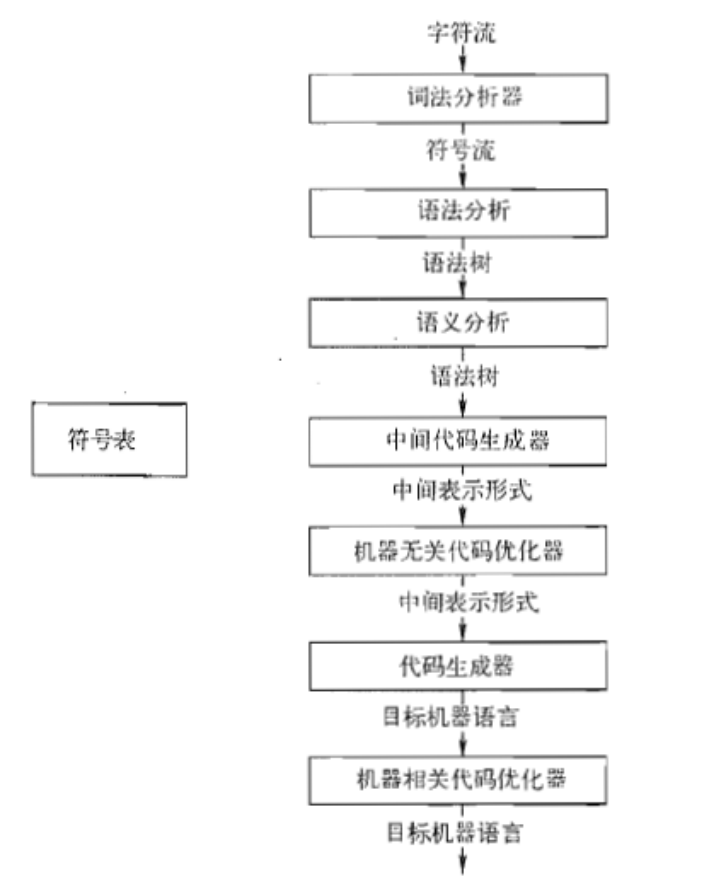
注:语义分析和中间代码生成可以合为一个步骤。原因是中间代码质量不够高,且编译器具有一定的可移植性。
下面是六个部分的详细说明:
1)词法分析(扫描):任务是读入组成源程序的字符流,将它们组织成为有意义的词素序列。输出:对每一个词素,语法分析器输出一个词法单元,形式:(token-name:attribute-value),token-name是在语法分析步骤使用的抽象符号,attribute-value是在语义分析和代码生成步骤使用的这个词法单元对应的条目。
词素:语音和语义的最小单位,词法单元的形式(token-name:attribute-value)可以理解为(单词种别/名字,单词符号的属性值),
嗯,举个例子:
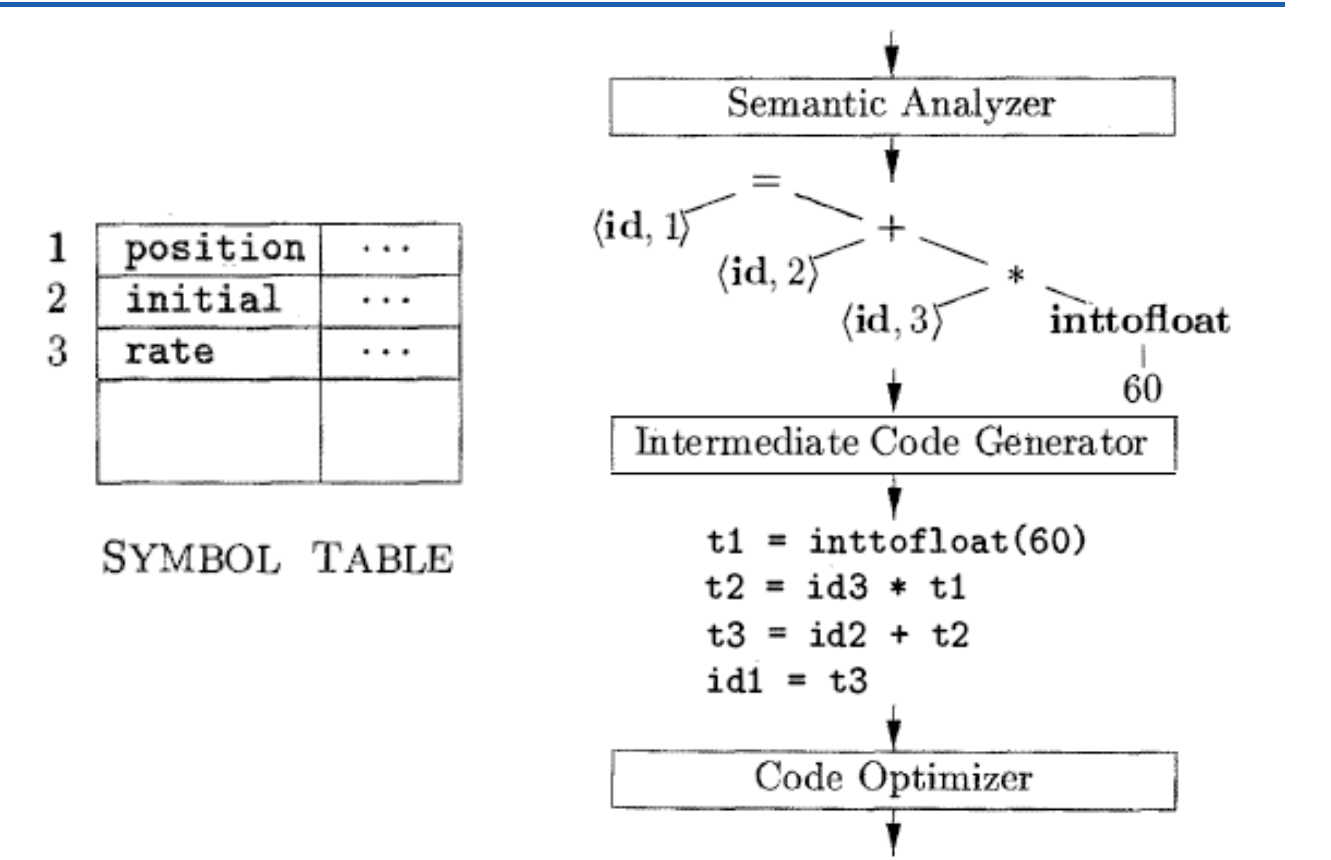
position = inital+rate * 60
position 是一个词素,被映射为<id,1> 其中id 是标识符 position 的抽象符号,而1 指向 position对用的条目。一个标识符对应的符号表条目应该存放和它有关的信息,比如它的名字和类型。
同理,= 是一个词素,被映射为 <=>,因为这个词法单元不需要属性值,所以我们省略了第二个分量;initial被银蛇为 <id,2>,+被映射为<+>,rate被映射为<id,3>,*被映射为<*>,60被映射为<60>;
我们常常把这些词法单元的名字称为终结符号,因为它们在程序设计语言(PDL)中是以终结符号的形式出现的。若词法单元有属性值,那么这个值就是一个指向符号表的指针,符号表中包含了该词法单元的附加信息,虽然这些附加信息与文法并无关系。
2)语法分析(解析/分析):任务是使用词法分析产生的词法单元的第一个分量创建树形的中间表示。该中间表示给出了词法分析产生的词法单元流的语法结构,常用的表示法是语法树,内部结点表示运算,相应的子结点表示运算的分量。后续步骤使用这个语法树分析源程序,产生目标程序。描述语法结构的工具有上下文无关法(CFG).
上下文无关法:描述词法单元的形成,任何一个词法单元与其所处的环境无关。

3)语义分析:任务是使用符号表和语法树的信息来检查源程序是否和语言定义的语法一致。收集类型信息,把这些信息存放在符号表或语法树中,一边在随后的中间代码生成过程中使用。语义分析的重要部分是类型检查,检查每个运算符是否具有匹配的运算分量,自动进行类型转换(下图的 inttofloat)。
4)中间代码生成:中间表示形式应该具有两个重要的性质:易于生成,能被轻易地翻译为目标机器的语言。它与源语言和机器无关。
中间代码生成器的输出是三地址代码序列。形式 X=Y op Z ,每个分量都像一个寄存器。
关于三地址分量,有几点:第一,每个三地址赋值的右部最多有一个运算符,因此这些指令确定了运算顺序。第二,编译器应该生成一个临时名字以存放一个三地址指令计算得到的值。第三,有些三地址指令的运算分量少于三个(下图的 id1=t3啊)。
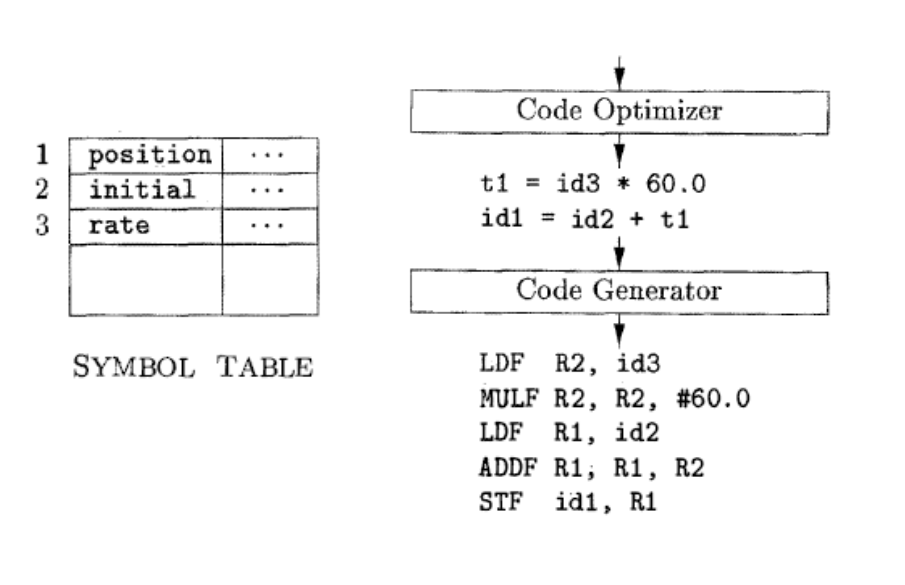
5)代码优化:分为与机器无关和有关的优化。
机器无关的代码优化:试图改进中间代码,以便生成更好的目标代码。
更好更快,更短,空间占用更少,能耗更低;
机器相关的优化。
优化编译器:不同编译器的代码优化工作量差别很大优化工作做得最多的编译器,即“优化编译器”
6)代码生成:任务:以源程序的中间表示形式作为输入,并把它映射到目标语言如果目标语言是机器代码,就必须为程序使用的每个变量选择寄存器或内存位置。
代码生成的一个重要方面是合理分配寄存器以存放变量的值。
编译器在中间代码生成或目标代码生成阶段做出有关存储分配的决定运行时刻的存储组织方法依赖于被编译的语言。
符号表(symbol table)
的作用:记录源程序中使用的变量名字,存储每个名字的各种属性有关的信息,变量的存储分配、类型、作用域,过程的参数个数和类型,参数的传递方法、返回类型等。
符号表是编译器中的重要数据结构
变量名表:为每个变量名创建一个记录条目,记录的字段就是名字的各个属性。
趟(pass)/“遍”:
编译步骤是编译器的逻辑组织方式,在特定实现中,可以将多个步骤的活动组合成一趟,每趟读入一个输入文件并产生一个输出文件。
所谓趟(遍)就是对源程序或源程序的中间结果从头到尾扫描一次,并作有关的加工处理,生成新的中间结果或目标程序。
典型的组织方式
前端作为一趟,优化作为一个可选的趟,后端作为一趟。
未完,提醒一下自己,哈哈哈。