FastDFS深度学习
简单的口述
首先说说分布式文件系统应对的需求吧;
-
有些应用涉及到很多文件的频繁上传和下载,如果我们将上传的文件保存到服务里的本地硬盘中,随着时间的推移,这个系统可能再也容纳不下其他的数据,还有就是文件的共享问题,参与集群的某个服务启用了图片保存在本地,参与集群的其他机器却获取不到该图片数据,单点问题不容置疑的夜存在,并发能力不强,还增加该服务器的web或者Nginx的压力
-
分布式文件系统的好处就是处理上面的诸多窘迫,将文件数据储存在多个机器上,这些机器通过网络连接,有统一的管理,有备份,有负载均衡等等...
-
分布式文件系统按保存数据大小来分,中小容量非FastDFS莫属了,文件大小建议在500m范围内,支持图片,视频等小型文件的大量储存,比如相册网站,或者短小视频网站,如果企业使用的第三方搭建的服务,其实是有一定的安全隐患的,你想假如你是一个短视频娱乐的项目,你把这种文件数据保存第三方的文件保存系统中,万一第三方公司跑路了,你的公司离崩盘也不远了,所以一般还是自己搭建分布式文件保存系统,安全一些;
-
FastDFS的话,是由淘宝"余庆"先生开发出来的一个纯C的分布式文件系统,致力于解决互联网三高 [高并发、高性能、高可用];
理论部分[面试]
大致了解架构
首先从大的方面看的话,FastDFS分为三个重要的部分,分别是客户端(Client),跟踪服务器(Tracker),储存服务器(Strorage),,下面我一一为大家介绍这三个角色
-
储存服务器:Storage Server
-
主要的作用就是提供一个保存文件数据的空间,一般以Group为一个单位,一个Group内包含多个Storage Server,看作是形成集群吧,数据之间通过同步保持一致 [异步操作],作为负载均衡的实现;多个Group之间互不联系,各自保存各自的数据,亦可形成集群,由多个Group组成
-
-
跟踪服务器:Tracker Server
-
看作是一个管理者吧,做一个调度中心,调度Client和Storege Server的通信,在访问上起负载均衡的作用
-
管理所有的Group,和Group中的所有的Storage Server,每一个Storage在启动后都会主动的连接Tracker,告知其所属的Group和自己的运行状态等信息,并保持心跳维持联系;
-
Tracker Server可以形成集群,对外提供服务,处理客户端的请求采用轮询的方式选择Tracker进行处理
-
-
客服端:就是程序员编写的程序
储存策略
-
为了支持大容量,储存节点采用了分组的方式,储存系统由一个或多个组组成,一个组可以由一台或多态储存服务器组成,一个组下的多个Storage,的数据是一样的,多个Storage起到了备份,防止单点故障,起到负载分摊的作用
-
如果我们再想增加新的Storage到组内的时候,同步已有的文件由系统自动完成,同步完成后,系统自动将新增的服务切换到线上对外提供服务,但是这里有个问题就是,当组内的储存服务器的本地容量大小不一致时,该组的可容纳文件数据上限以最小那个服务为准,当组内的空间耗尽时,我们可以动态的添加一个新的组,只需要在组内增加一台读多态Storage,并将其配置为我们一个新的组,这样就实现了了储存容量的线性扩展
Storage的状态收集
Storage会通过配置连接上集群中的所有Tracker,定时向他们报告自己的状态,包括"磁盘剩余空间"、"文件同步状况"、"文件呢上传下载次数"等统计信息
Storage一共有七个状态,但我们熟悉两三个状态就行:
-
FDFS-STORAGE-STATUS_ONLINE :服务在线,但没有提供服务
-
FDFS-STORAGE-STATUS_ACTIVE :服务在线,可以提供服务
-
FDFS-STORAGE-STATUS_OFFLINE:服务离线
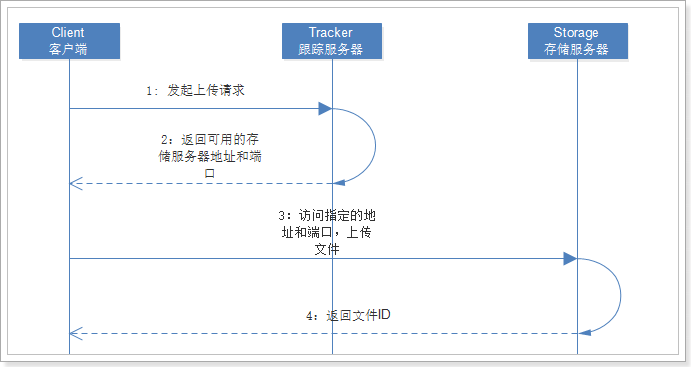
文件上传流程分析
-
0:Tracker Server收集Storage Server的状态信息,Storage回向所有的Tracker汇报自己的状态,[空间情况、文件同步情况、上传下载次数等信息]
-
1:Client想Tracker发起上传请求,Client再上传时可任意选择一个集群中的Tracker
-
2:当Tracker接收到上传请求时,会为该请求分配一个可以储存该文件的Group,一下几种几种选择Group的规则
指定某一个Group
剩余储存空间最多的Group有限
轮询的方式
-
2:当确定了Group后,Storage会选择一个Storage Server的ip和端口返回给客户端,选取Storage支持以下的规则
在Group的范围内轮询
按照ip排序
按照在Storage上配置的优先级排序
-
3:客户端访问发起上传请求,Storage将会为这个上传的文件分配一个数据储存目录,支持以下规则
多个储存目录之间轮询
剩余储存空间最多的有限
-
3:选定了目录之后,Storage会为这个文件生成一个File_id,这个File_id的组成部分是包含了很多信息的,然后以这个File_id问文件名保存到选择好的储存目录下
-
4:当文件已经储存到选择的目录下的时候,即认为该文件已经存在成功,接下来就会为该文件另外生成一个标识文件名【用于定位】,该文件名包有Group、存储目录、子目录、文件名、文件后缀名拼接而成并返回给客户端,如这般模样: group1/M00/00/00/Zad2afb5oaiuAZEMVABfYcN8vzII630.png
之前我们就已经知道,一个Group组内的Storage是集群状态的,也就是当我们将文件数据上传到Storate后,会创建一个后台线程将文件同步至同一个Group中的其他的Storage Server.保持数据的一致性;
同步规则如下:
只在本组内的Storage Server之间同步;
源头数据才需要同步,也就是该文件第一次上传到那个Storage,那文件就成为该Storage的源头数据
当我们新增Storage时,由已有所有数据的Storage将所有数据[源头数据、备份数据]同步给新的新增服务器
-
当每个Storage写文件时,同时会写一份binlog,但是这个binlog里面不包含文件数据,只包含文件名等元信息,这封binlog用于后台数据的同步,Storage会纪录想Group内其他Storage数据同步的进度,以便重启后能够接上次的进度继续同步,进度以时间戳的方式进行纪录,所以最好能保证集群内所有的Server的本地时间一致;[ Linux本地时间一致 ]
-
Storage的同步进度会作为元数据的一部分报给给Tracker,Tracker在选择读取哪一个Storage的时候就会以同步进度作为参考:
文件下载流程分析;
初始化和第一步与文件上传一致,特别要说的就是,之前我们在文件上传完成后,不是返回给客户端一个标识文件名吗,当我们下载请求到达Tracker时候,Tracker会解析这个标识文件名,获得这个文件的Group,路径信息,文件大小,创建时间,源Storage Server IP等消息,然后为该请求响应一个Storage用来响应数据,
但是在选择Storage的时候会有一个比较尴尬的情况出现,那就是我们要访问的数据在我们想获取它的时候,还没有完成全Group内的数据同步,为了避免这种情况的发生,Tracker在选择可用Strage时通过一定的规则来选择可读的Storage,保证资源的可访问性
FastDFS的安装(Tracker&Storage)
三台机器吧,一个作为Tracker Server,两台作为Storage
环境准备
GCC用来对C语言代码进行编译运行,使用yum命令安装:
sudo yum -y install gcc
unzip工具可以帮我们对压缩包进行解压
sudo yum install -y unzip zip
安装libevent
sudo yum -y install libevent
安装Nginx依赖
sudo yum -y install pcre pcre-devel zlib zlib-devel openssl openssl-devel
安装libfastcommon-master
这个没有yum包,只能通过编译安装:
-
解压刚刚上传的
libfastcommon-master.zipunzip libfastcommon-master.zip -
进入解压完成的目录:
cd libfastcommon-master -
编译并且安装:
sudo ./make.sh
sudo ./make.sh install
FastDFS的安装
下载FastDFS的
wget https://github.com/happyfish100/fastdfs/archive/V5.05.tar.gz
解压、编译、安装
tar -zxvf V5.05.tar.gz
cd fastdfs-5.05
./make.sh
./make.sh install
通过上面的操作,我们可以通过 ll /etc/init.d/ | grep fdfs 获取到两个启动脚本

-
-
fdfs_storaged 是storage启动脚本
然后就是配置文件模版的检查: ll /etc/fdfs/

-
-
storage.conf.sample 是storage的配置文件模板
-
client.conf.sample 是客户端的配置文件模板
Tracker的启动
-
通过上面的查询我们可以知道,安装都是一样的安装,不区分Tracker 和 Storage,每个安装下都有Storage和Tracker的启动命令,也有各自的配置文件,我们就可以修改相应的配置文件,运行相应的脚本即可开启Tracker Server 和Storage Server
-
Tracker的话,我们就修改 tracker.conf.sample配置文件,并启动fdfs_trackerd脚本
编辑tracker的配置文件:进入到 /etc/fdfs/
cp tracker.conf.sample tracker.conf #实列配置文件重命名
vim tracker.conf #编辑该配置文件
#修改的内容:重新指定一个tracker的数据和日志存放目录
base_path=/usr/local/FastDFS/fdfsData
# HTTP 服务端口,这个酌情修改,一般无需修改
http.server_port=80
#修改后保存退出,创建出我们的这个文件夹
mkdir -p /usr/local/FastDFS/fdfsData
FastDFS的服务脚本在配置文件中指定的 /usr/local/bin,而实际命令是安装在/usr/bin下的
如果就这样启动是找不到启动脚本的,所以这里有两种解决方式:
-
第一种修改配置文件,重新指定服务脚本的路径(不建议,容易出错)

第二种方式就是建立软连接 (推荐使用这种)
ln -s /usr/bin/fdfs_trackerd /usr/local/bin ln -s /usr/bin/fdfs_storaged /usr/local/bin #这个是tracker,无需配置storage软连接 ln -s /usr/bin/stop.sh /usr/local/bin ln -s /usr/bin/restart.sh /usr/local/bin
然后我们就可以直接启动Tracker Server了,启动可以用
#指定目录下的脚本启动,【不建议】
/etc/init.d/fdfs_trackerd start
#安装过程中fdfs已经是被设置为系统服务,采用服务启动方式【建议】
service fdfs_trackerd start
#可用可不用,设置为开机自启
chkconfig fdfs_trackerd on
# 或者 vim /etc/rc.d/rc.local ,加入配置设置为开启启动:
/etc/init.d/fdfs_trackerd start
查看FastDFS是否已经启动:
netstat -ultp | grep fdfs 查询到22122端口正在被监听,视为启动成功

Storage的启动【两台同步操作】
-
对应的这次我们应该修改storage.conf并启动fdfs_storage脚本即可完成Storage Server的开启
-
首先我们复制并重名配置文件
-
-
编辑storage.conf : 旁边的编号是数据所在行数 : set nu
#配置storage的数据和日志存放目录
41 base_path=/usr/local/FastDFS/fdfsData
#storage上传文件的存放目录
109 store_path0=/usr/local/FastDFS/storage
#tracker的地址,端口默认即可,有多个Tracker,就复制这一排改ip port 即可
118 tracker_server=192.168.159.159:22122
-
然后就是创建配置文件中对应的目录了:
mkdir -p /usr/local/FastDFS/fdfsData /usr/local/FastDFS/storage
再然后就是如法炮制,建立软连接
ln -s /usr/bin/fdfs_trackerd /usr/local/bin #这个是storage,无需配置tracker软连接
ln -s /usr/bin/fdfs_storaged /usr/local/bin
ln -s /usr/bin/stop.sh /usr/local/bin
ln -s /usr/bin/restart.sh /usr/local/bin
然后就可以启动了,在我们启动启动Storage Server之前,必须确保Tracker是在线的
启动方式也是如Tracker那般模样有两种,我们采用系统服务启动的方式
service fdfs_storaged start
然后查看一下监听:netstat -ultp | grep fdfs
发现2300端口已被监控,算作是正常启动

这个时候Storage Server 和Tracker Server算是已经建立里连接了,我们可以去看看Storage Server存放上传文件的目录
可以看到这些就是我们用来存放上传文件数据的目录
基本环境算是搭建完成了,最后我们还可以查看一下整个系统的服务状态:/usr/bin/fdfs_monitor /etc/fdfs/storage.conf
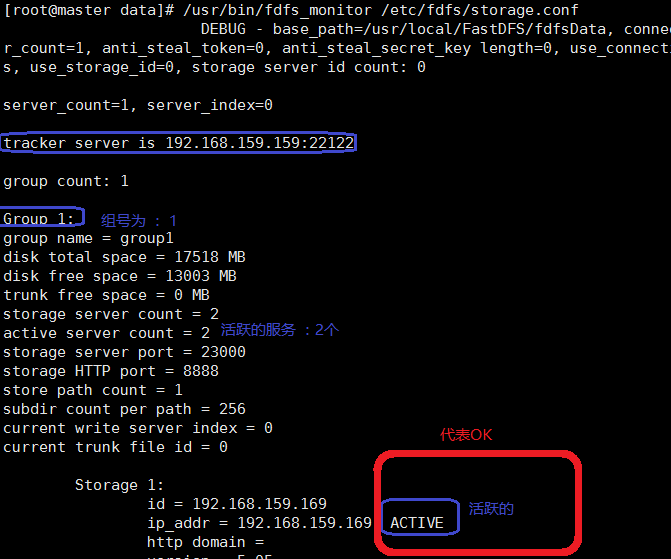

基本的环境就算搭建好了,我们上传的数据该如何才呢个被访问呢?Nginx的静态代理?还是?
FastDFS配置Nginx模块
一笔带过Nginx静态代理
-
接着上面的我们继续,当我们的图片上传后,该如何才能被外部说访问呢,一个方案就是单独的配置一个Nginx拦截对用的请求将其代理到我们的FastDFS储存数据的目录即可,这种方式因为使用,所以不做过多说明,简单带过,留点笔记有个印象即可,注意Nginx是装载Storage机器上的,不是Tracker机器上的,所以用Nginx指向指定的目录文件,即可将本地的文件被外界通过Http请求所访问到
首先大家要知道我们的资源定位路径,为如下所示

这个时候我们的Nginx的配置的话,就如下这样:指向我们存放数据的目录

 这种方式不是我们学习的重点,下面这一种才是我们学习目标,FastDFS知道自己的文件不能被外界所访问,自己集成了Nginx模块到FastDFS中,需要我们手工去发掘才能使用
这种方式不是我们学习的重点,下面这一种才是我们学习目标,FastDFS知道自己的文件不能被外界所访问,自己集成了Nginx模块到FastDFS中,需要我们手工去发掘才能使用
Nginx模块的挖掘
-
首先简单介绍一下FastDFS的Nginx模块:
一、提供向外的http访问服务
二、当Storage集群下文件复制未完成的情况下,请求访问到了没有复制完数据的机器,可以将请求转发到源服务器进行数据的获取,可以预防因为复制延迟导致的文件无法访问的错误【源服务器:就是该文件第一次上传到Storage的那台机器,然后才通过复制机制使得其他Storage也有该文件的数据】
-
下载 fastdfs-nginx-module、解压
# 下载 fastdfs-nginx-module wget https://github.com/happyfish100/fastdfs-nginx-module/archive/5e5f3566bbfa57418b5506aaefbe107a42c9fcb1.zip # 解压 unzip 5e5f3566bbfa57418b5506aaefbe107a42c9fcb1.zip # 重命名 mv fastdfs-nginx-module-5e5f3566bbfa57418b5506aaefbe107a42c9fcb1 fastdfs-nginx-module-master
-
配置Nginx,在Nginx中添加模块:
-
进入到解压包目录,我们添加模块后需要重新编译、安装【就是你下Nginx压缩包解压的那个文件夹】
-
这个过程看看页面的信息有没有什么报错信息error,没有error视为没错,可继续
#进入到Nginx的解压目录 cd /root/nginx-1.10.2/ #添加模块指定模块src文件,我的模块的位置是在 /usr/local/FastDFS/fastdfs-nginx-model-master/src ./configure --add-module=/usr/local/FastDFS/fastdfs-nginx-model-master/src #重新编译并安装 make && make install
-
查看模块是否挖掘正确添加 进入到Nginx的安装目录: cd /usr/local/nginx/sbin
-
动用命令 : ./nginx -V, 如下则说明添加模块成功

-
进入到Nginx模块中,复制配置文件到指定文件:
cd /usr/local/FastDFS/fastdfs-nginx-model-master/src cp ./mod_fastdfs.conf /etc/fdfs/
-
要修改的部分属性为:
#连接超时时间 connect_timeout=10 #Tracker Server的配置 tracker_server=192.168.159.159:22122 #如果文件ID中包含、/group**,就要设为True 52 url_have_group_name = true #Storage配置的Storage_path0的路径,必须和/etc/fdfs/storage.conf中的路径相同 61 store_path0=/usr/local/FastDFS/storage
-
复制部分配置文件到 /etc/fdfs/ 作为系统配置文件
cd /usr/local/FastDFS/fastdfs-5.05/conf/ cp anti-steal.jpg http.conf mime.types /etc/fdfs/
-
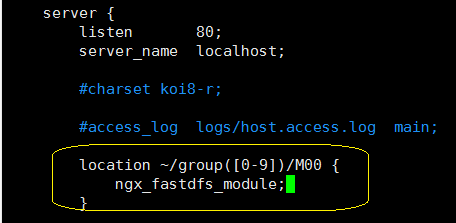
然后就是配置Nginx的配置文件设置响应的location规则,如下:
#进入到Nginx的安装目录下的配置文件目录,编译nginx.conf
vim /usr/local/nginx/conf/nginx.conf

然后就是简单的预检一下配置文件是否完整,有没有错误的地方 :nginx -tq
没报错就直接启动 ./nginx ,然后发现如下页面就算启动成功:

文件的上传下载测试
我们就在创建一个文件夹,存放我们测试的图片 mkdir /usr/local/FastDFS/testJPG
然后我们本地拖一张帅照上去,利用FastDFS的内置上传 演示一下文件上传
在此之前我们得将client.conf.sample重命名client.conf,并做修改:

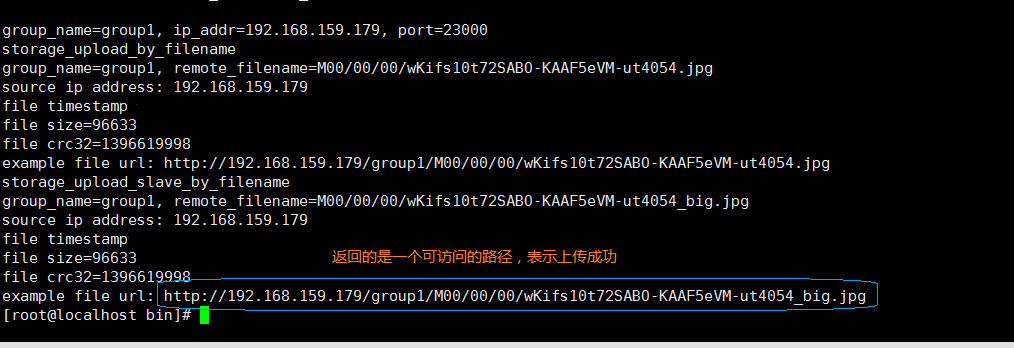
# 调用测试 测试用的配置文件 上传 上传文件的路径
/usr/bin/fdfs_test /etc/fdfs/client.conf upload /usr/local/FastDFS/testJPG/test.jpg
-
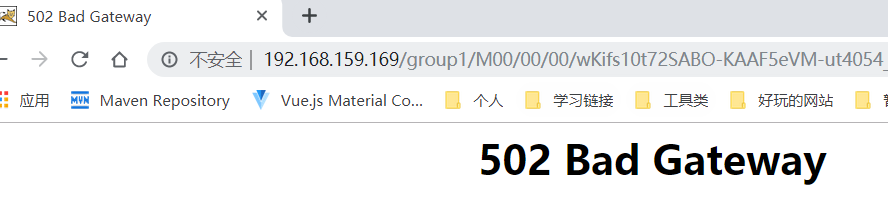
然后我们就走Nginx的那台服务器,通过Nginx去访问这张图片:
不好意思!跑错片场了,由于之前的Nginx我配很多东西,我把无关的都删掉了,留下唯有的一个location和server,效果如下:


到这里基本就完成了FastDFS的基本用法,后面还有点内容,容我慢慢更来
Java客户端
maven中央仓库没有这个依赖,需要我们手动添加到本地Maven仓库中
下载 :https://github.com/happyfish100/fastdfs-client-java
打成jar包,通过maven命令将该jar安装在本地仓库中
-
<dependencies> <!--手动添加到本地库的fdfs客户端依赖--> <dependency> <groupId>org.csource</groupId> <artifactId>fastdfs-client-java</artifactId> <version>5.0.4</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.5</version> </dependency> <dependency> <groupId>commons-fileupload</groupId> <artifactId>commons-fileupload</artifactId> <version>1.3.1</version> </dependency> <!--测试依赖--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies>
编写配置文件:fdfs_client.conf
-
tracker_server = 192.168.159.159:22122
然后就一个启动函数
-
public class test { @Test public void test() throws Exception { // 1、加载配置文件,配置文件中的内容就是 tracker 服务的地址。 ClientGlobal.init("C:\Users\MSI\Desktop\code\cloud-demo\fdfsTest\src\main\resources\fdfs\fdfs_client.conf"); // 2、创建一个 TrackerClient 对象。直接 new 一个。 TrackerClient trackerClient = new TrackerClient(); // 3、使用 TrackerClient 对象创建连接,获得一个 TrackerServer 对象。 TrackerServer trackerServer = trackerClient.getConnection(); // 4、创建一个 StorageServer 的引用,值为 null StorageServer storageServer = null; // 5、创建一个 StorageClient 对象,需要两个参数 TrackerServer 对象、StorageServer 的引用 StorageClient storageClient = new StorageClient(trackerServer, storageServer); // 6、使用 StorageClient 对象上传图片。 //扩展名不带“.” String[] strings = storageClient.upload_file("F:\mySpace\myPhoto\beijing\1.jpg", "jpg", null); // 7、返回数组。包含组名和图片的路径。 for (String string : strings) { System.out.println(string); } } }
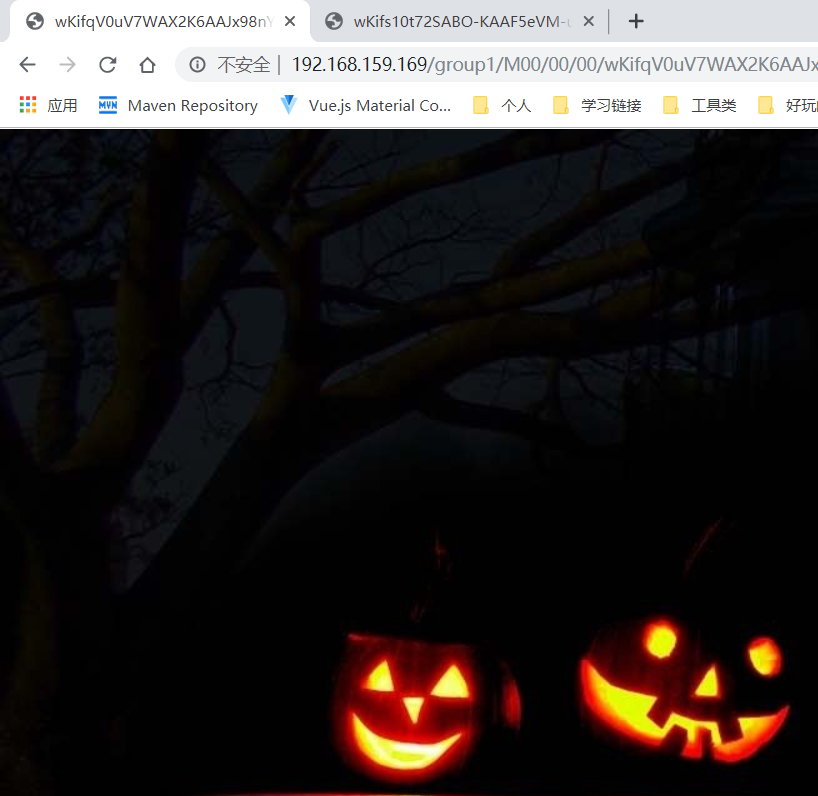
最后我们打印给我们返回的路径:

我们就根据这个路径去两个Storage中查看数据是否存在,并在浏览器中通过Nginx去访问它:
-


-
可见 以811结尾的文件正在两台Storage的数据目录中,已经完成了同步,下面我们去访问它
-
-
OK,Java客户端应该还有还有其他的方式,不止这一种,后面如果遇到有与框架整合的,再做补充
储存缩略图[重要]
简单介绍
妇联网需要同一内容,但是不同尺寸的图片,存储压缩图就能满足这种需求
在学习这个之前没我们得知道什么是"等比压缩"?
-
比如源图是1200*1200的 那么缩略图遵循等比压缩,只能是1:1的缩略,比如300 * 300再或者700 * 700
-
而不能是500 * 600,再或者600 * 200,业务是不会这么玩的
主要的运用环境
使用FastDFS储存一个图片的多个分辨率的备份时,希望只记住源图的fileid,并能将其他分辨率的图片与源图关联,就是用到了储存缩略图这种方式,比如:
-
主从文件是指文件ID有关联的文件,一个主文件可以对应多个从文件
-
主文件ID = 主文件名 + 主文件扩展名
-
从文件ID = 主文件名 + 冲文件后缀名[比如_300*300] + 从文件扩展名
-
Nginx生成缩略图实之image_filter模块
-
实现图片压缩有很多的方式,比如 ImageIO 、MagicImage、Nginx
-
当然Nginx是表现特别突出的,也就是我们我们今天的主要学习的;
image_filter模块
-
Nginx的这个模块针对"JPEG"、"GIF"、"PNG"类型图片进行转换处理[ 压缩、裁剪、旋转 ],这个模块默认不被编译,所以要在编译Nginx源码的时候就要加入相关的配置信息
-
安装gd-devel依赖:
yum -y install gd-devel -
重新编译:之前还添加了部分模块,我也找不到配置了,这里肯恩而过有点误差
-
sudo ./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --with-http_realip_module --with-http_image_filter_module --add-module=/usr/local/FastDFS/fastdfs-nginx-model-master/src
-
-
编译及安装以及平滑重启
-
make && make install /usr/local/nginx/sbin/nginx -s reload
-
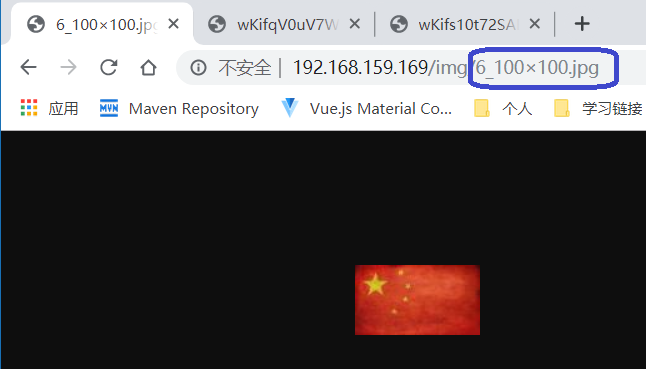
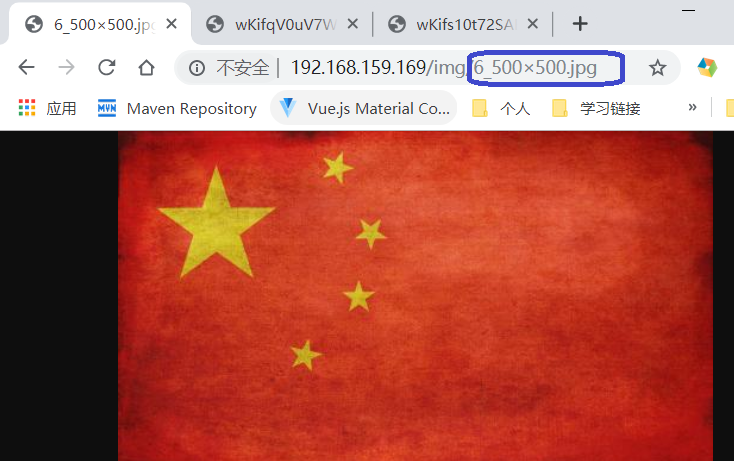
访问普通的图片
假设我们的图片的真是路径是在本地的/usr/local/test/img/xxxx.jpg,下面有很多jgp格式的图片,我们希望通过访问 、image/xxx_100 * 100.jpg这种请求生成长宽均为100的小图,并且请求的宽和高是随着我们的请求动态的改变的,那么我们就需要在Nginx模块中拦截该请求并返回转换后的小图,在对应的server中配置,注意是× 而不是* ,我还绕进去了,
location ~* /img/(.*)_(d+)×(d+).(jpg|gif|png) {
root /;
set $s $1;
set $w $2;
set $h $3;
set $t $4;
image_filter resize $w $h; #重新设定大小,值应用请求url中的数值
image_filter_buffer 10M; #应该是缓存优化,还有很多的命令[百度],这里我就做了最常用的压缩
rewrite ^/img/(.*)$ /usr/local/test/img/$s.$t break;
}
#这里对这个语法做个简单的解释,详细的可以百度查询:
# 拿这个请求做示范 :http://192.168.159.169/img/6_500x500.jpg
# set $s $1; $1是一个占位符,代表请求中的第一个参数为 6
# set $w $2; $2代表请求中的第二个参数 为500
#以此类推,相当于就是通过占位符获取请求的的参数,将其赋值给一个变量。后面代码可以使用这个变量,做到值传递
当我这样配置之后

rewrite命令可百度查询用法,他最终指向的地址却是Nginx安装目录下的 html/img/xx.jpg 这里是x而不是*
一番错误日志查看后,我被动的修改了我的图片位置,随后进行访问,实现了缩略图功能
至于访问FastDFS的图片资源:
-
Nginx配置下面的拦截规则和逻辑处理即可,实现整合FastDFS
-
[ 复制到文本删掉注释复制到配置文件中 ,避免格式错乱]
location ~ /group1/M00/(.*)_([0-9]+)x([0-9]+).(jpg|gif|png){
alias /usr/local/FastDFS/storage/data; #指向资源所在路径
ngx_fastdfs_module; #nginc的fdfs模块
set $w $2;
set $h $3;
if ($h != "0") { #如果宽 = 0 重定向到另一个路径后退出
rewrite group1/M00(.+)_(d+)x(d+).(jpg|gif|png)$ group1/M00$1.$4 break;
}
if ($w != "0") { #与上同理
rewrite /group1/M00/(.+)_(d+)x(d+).(jpg|gif|png)$ /group1/M00/$1.$4 break;
}
image_filter crop $w $h; #根据给定的长度生成缩略图
image_filter_buffer 2M; #源图最大为两兆,要裁剪的图片超过2M返回415错误
}
location ~ group1/M00/(.+).?(.+){
alias /usr/local/FastDFS/storage/data;
ngx_fastdfs_module;
}
Nginx生成缩略图实之Nginx Image模块
-
这个Nginx模块主要功能就是对请求的图片精心压缩/水印处理,支持文字水印和图片水印
-
支持自定义字体,文字大小水印透明度,水印位置;
-
判断源图是否大于制定储存才处理等等共呢个
-
支持jpeg | png | gif 等格式
安装步骤:
-
首先安装相关的依赖
-
yum install -y gd-devel pcre-devel libcurl-devel
-
下载相关模块并解压
wget https://github.com/oupula/ngx_image_thumb/archive/master.tar.gztar -zxvf master.tar.gz
然后就是对Nginx重新编译安装,将这个模块安装进去:
sudo ./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module --with-http_realip_module --with-http_image_filter_module --add-module=/usr/local/FastDFS/fastdfs-nginx-model-master/src --add-module=/usr/local/FastDFS/ngx_image_thumb-master
然后就是修改Ngxin的配置文件,我们把之前的那个模块的拦接规则location删掉,替换成这个模块的:
location /test_image/ { root /usr/local/nginx/; image on; #是否开启缩略图功能,默认关闭off image_output on; #否不生成图片而直接处理后输出 默认off image_jpeg_quality 75; #生成JPEG图片的质量 默认值75 image_water on; #是否开启水印功能 image_water_type 0; #水印类型 0:图片水印 1:文字水印 image_water_pos 9; #水印位置 默认值9 0为随机位置,1为顶端居左,2为顶端居中,3为顶端居右,4为中部居左,5为中部居中,6为中部居右,7为底端居左,8为底端居中,9为底端居右 image_water_file "/usr/local/nginx/test_image/8.jpg"; #指定水印图片的位置 image_water_transparent 80; #水印透明度,默认20 }
创建对应的文件夹和文件并上传响应图片资源到指定目录
很有很多的属性,这里就不做罗列了,可以面向搜索引擎学习,然后就是查看我们的结果:
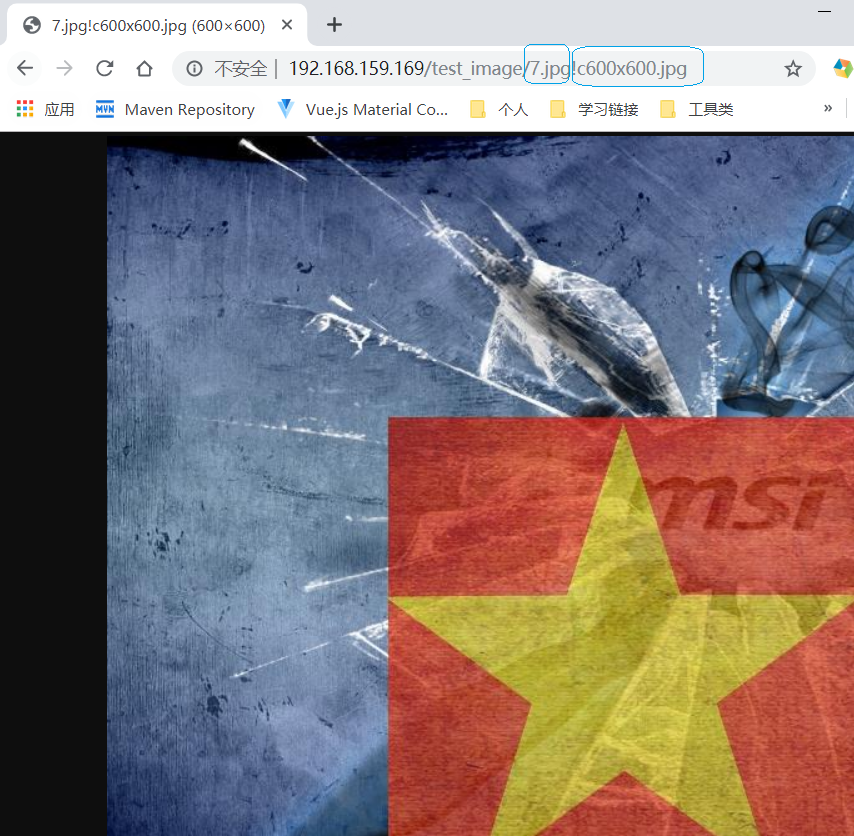
通过这种方式,ip:port/xxx/x.jpg!c100x100.jpg 这种格式完成对图片的加工并响应给客户端
合并储存[重要]
简单介绍
-
当我们FastDFS在处理海量小文件的时候,文件系统的处理性能会受到显著的影响,主要是IO的读写和接受并发的能力会有所下降,解决的方式就是合并储存:将小文件合并储存成大文件,使用seek来定位大文件的指定位置从而实现对小文件的访问
-
FastDFS提供的合并储存功能,默认创建的大文件为64MB,然后再该大文件中储存很多小文件,大文件中容纳一个小文件的空间成为一个Slot,规定Slot的最小值为256KB,最大为16MB,这里需要说明的是,即使你的文件大小小于了256KB,但他还是要占256KB的空间,至于超过16MB的文件不会合并储存而是创建独立的文件
文件配置
想要这个功能生效,我们只需要在Tracker.conf中开启和设置有关属性的值即可


就这两个属性 修改一下即可,一个是开启合并储存,一个暂时我还明白是什么意思,默认是0改为1即可
修改完之后就是杀掉当前Tracker的进程 ps -ef | grep tracker kill -9 XXXX
Tracker Server已经重启完毕,再把两个Storage Server 也重启一下 [ 建议先kill,在运行 ]
然后我们就用Java客户端上传两张比较大的图片测试一下, Java客户端回显:
-
M00/00/00/wKifqV0vRQyIUpxsACpHwg8v4b8AAAAAQAAAAAAKkfa715.jpg
-
M00/00/00/wKifqV0vSIOIIxiNAA_EXLIVQwwAAAAAQAqR9oAD8R0240.jpg
然后我们去Storage中查看一下我们上传的文件:
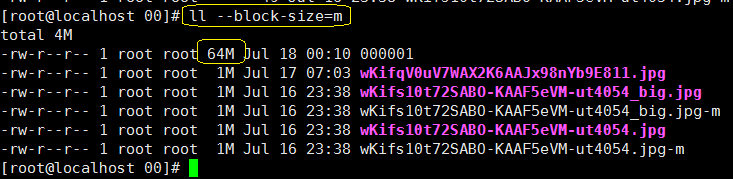
-
我们上传的文件去哪了?我不知道,我也不敢问!
-
但是两台Storage Server 都多了一个0000001 而且大小还为64M
合并储存文件命令和文件结构
-
当我们对FastDFS上传文件成功的时候,服务器会返回一个该文件的存取ID叫做fileid,当我们没有开启合并储存的时候,fileid和磁盘上实际储存的文件一一对应,当我们开启了合并储存之后,发现没有对应的fileid了而是多个fileid被储存成一个大文件
-
三个概念
-
Trunk文件:Storage服务器磁盘上储存的实际文件,大小为64M
-
00000001这种格式,文件名从1开始递增,类型为in
-
-
合并文件的fileid:服务器启用合并储存后,每次上传返回给客户端的fileid,但是已经没有一一对应关系存在
-
没有合并储存的fileid:表示服务器未启用合并储存时,Upload返回的fileid
-
合并储存后fileid的变化:
-
合并储存:M00/00/00/wKifqV0vRQyIUpxsACpHwg8v4b8AAAAAQAAAAAAKkfa715.jpg
-
没有合并:wKifqV0uV7WAX2K6AAJx98nYb9E811.jpg
有没有发现什么问题,长度?合并储存之后返回的fileid明显的比之前的要长很多,因为这个id中包含了很多的数据,重要的比如定位大文件的大文件id 和定位小文件的偏移量等
Trunk文件的内部结构
-
Trunk文件内部是由多个小文件组成,每个小文件都会有一个trunkHeader,以及紧跟其后的真实上传数据:
-

-
alloc_size : 文件大小与size等
-
filesize:该小文件占用大文件的空间,最小256KB 最大16M
-
crc32:文件内容的crc32码
-
mtime:文件的修改时间
-
formatted_ext_name:文件扩展名
Trunk文件的大小是64M,这个刚刚我们已经看到了,这里就涉及到一个空闲空间的问题,你想?当我们储存一个1M大小的文件时,我们开启了合并储存,Trunk文件的大小是固定的64M,而我们上传所占用的空间仅为1M ,也就是说还有63M是空闲状态的,当我们下次再次上传小于16M的文件时,空间的的获取又是个什么情况呢?见图知意:
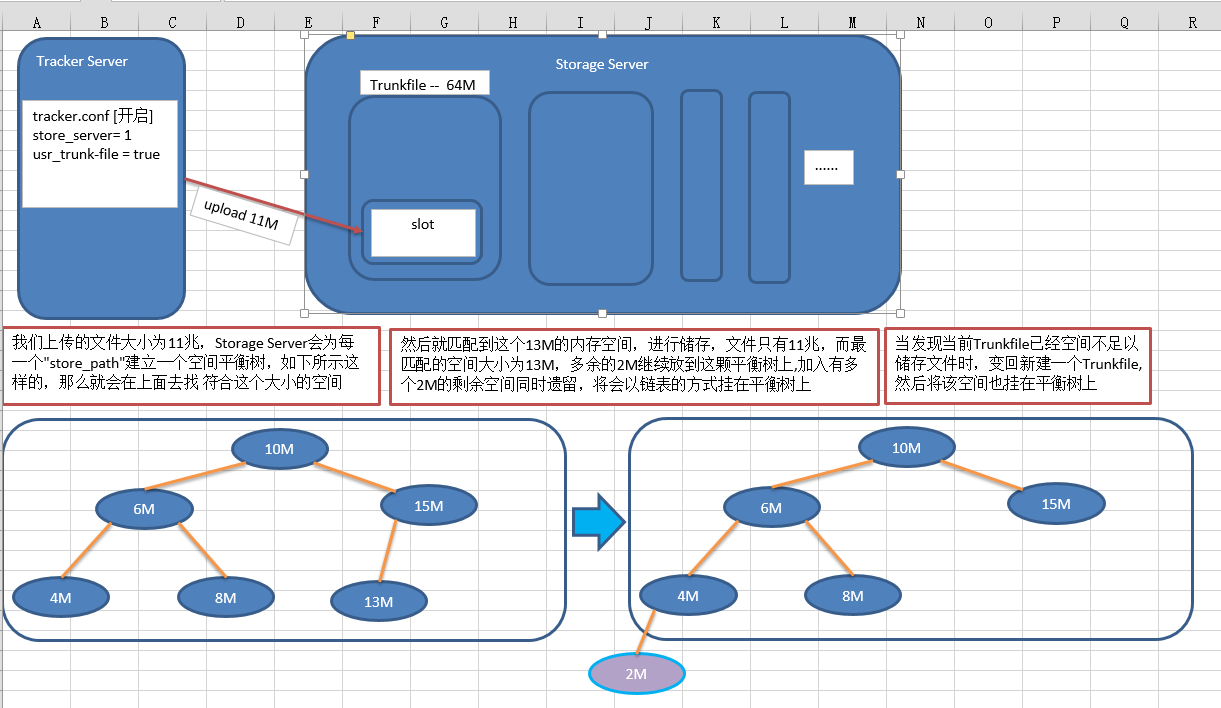
我再做一个文字性的说明:
-
再Storage内部会为每一个store_path [ 配置文件中指定储存数据的目录 ]构造一棵一空闲空间块大小作为关键字的空闲平衡树,大小相同的话,以链表形式存在,当我没得上传需要一个空间来储存数据时,就会根据文件大小来匹配这棵树,至于被匹配的那块空间多余的部分会被切割作为一个新的空闲块重新被挂在空闲平衡树中
然后就会有一个问题发生:
一个组内的所有的Storage Server都具有分配空闲空间的能力,而我们的请求是经过Tracker Server负载均衡分散请求,用一个Group内的Storage Server之间的一致性需要同步机制来完成,坏就坏在同步需要时间,而在这个同步的时间内,源数据所占用的空间说不定已经被Tracker Server 分来的其他储存请求占据,就会造成数据冲突,于是便引入了"TrunkServer" 的概念。
"Trunk Server ":是该Group中的一个Storage Server,Trunk Server由Tracker指定,只有Truncker Server才有权限分配空闲的空间,决定文件应该保存在Trunkfile的哪个位置,并且在通过trunk file(合并文件同步) + binlog日志(空间分配同步)完成同步