为了实现我们相对来说是纯净音频的噪声添加,我们分三步走:
-
第一步,读取原始音频,并输出相关图像
-
第二步,加入指定信噪比的高斯白噪声,并输出相关图像
-
第三步,加入其他的噪声类,并输出相关图像
一、读取原始音频
读取原始音频的方法一般可以分成四类:scipy、pysoundfile、wave和librosa。
注:代码里标粗部分就是读取方式
1).scipy读取原始音频
from scipy.io import wavfile
import numpy as np
import matplotlib.pyplot as plt
sample_rate, sig = wavfile.read('C:/Users/Lenovo/Desktop/test_0_desc_30_100.wav')
print("采样率: %d" % sample_rate)
print(sig)
if sig.dtype == np.int16:
print("PCM16位整形")
if sig.dtype == np.float32:
print("PCM32位浮点")
plt.figure(1)
plt.subplot(4,1,1)
plt.plot(sig[:,0])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,2)
plt.plot(sig[:,1])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,3)
plt.plot(sig[:,2])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,4)
plt.plot(sig[:,3])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.show()
#结果显示
采样率: 44100
[[ 7 -9 3 -35]
[ 25 1 8 2]
[-32 -3 6 -6]
...
[ 5 7 5 20]
[ 3 -11 16 20]
[-21 9 -8 2]]
PCM16位整形
因为音频是4通道的,所以图片分布为[1,2;3,4]
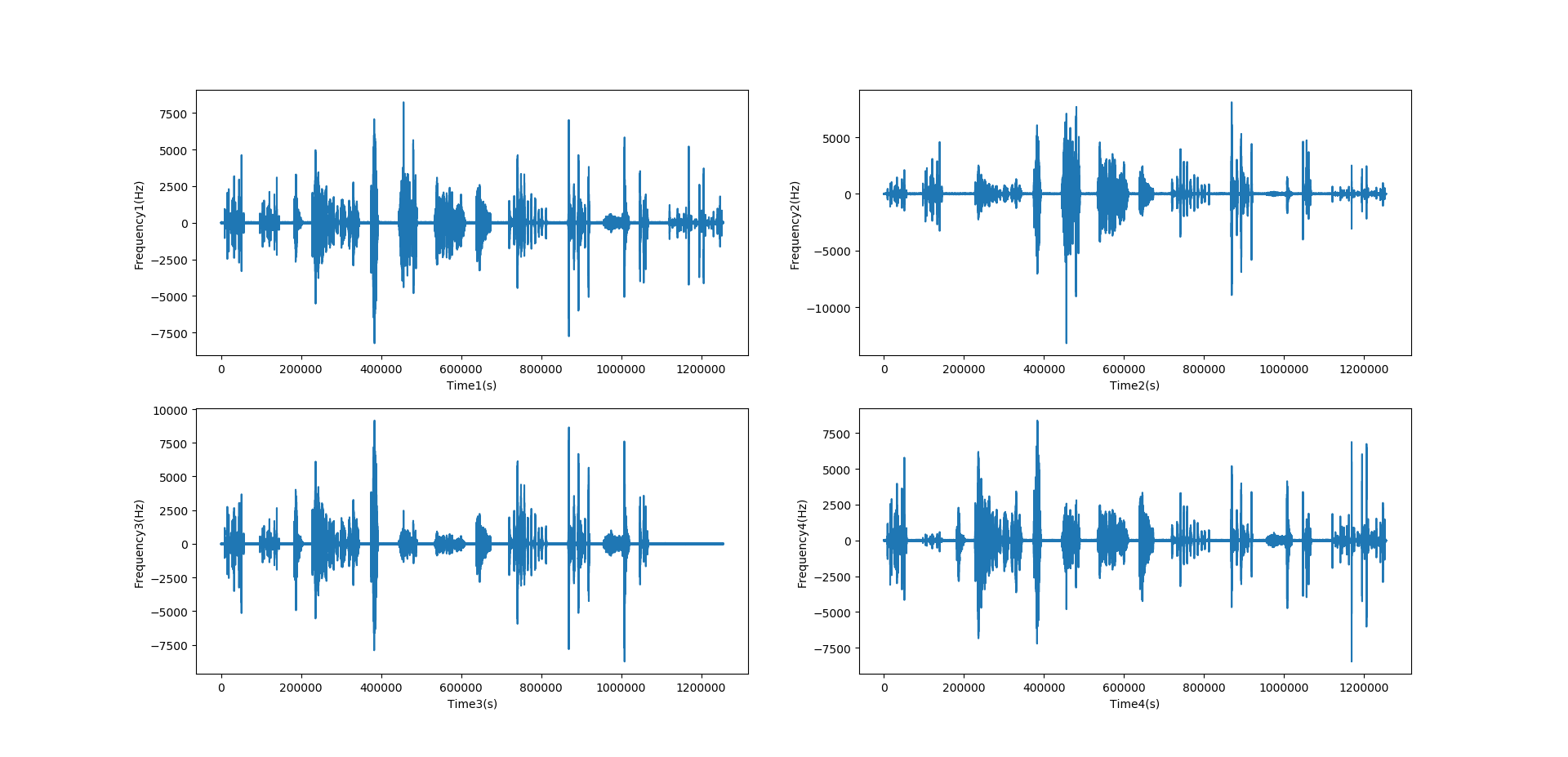
2).pysoundfile读取音频
import soundfile as sf
import matplotlib.pyplot as plt
sig, sample_rate = sf.read('C:/Users/Lenovo/Desktop/test_0_desc_30_100.wav')
print("采样率:%d" % sample_rate)
print(sig)
plt.figure(1)
plt.subplot(2,2,1)
plt.plot(sig[:,0])
plt.ylabel('Frequency1(Hz)')
plt.xlabel('Time1(s)')
plt.subplot(2,2,2)
plt.plot(sig[:,1])
plt.ylabel('Frequency2(Hz)')
plt.xlabel('Time2(s)')
plt.subplot(2,2,3)
plt.plot(sig[:,2])
plt.ylabel('Frequency3(Hz)')
plt.xlabel('Time3(s)')
plt.subplot(2,2,4)
plt.plot(sig[:,3])
plt.ylabel('Frequency4(Hz)')
plt.xlabel('Time4(s)')
plt.show()
#结果显示
采样率:44100
[[ 2.13623047e-04 -2.74658203e-04 9.15527344e-05 -1.06811523e-03]
[ 7.62939453e-04 3.05175781e-05 2.44140625e-04 6.10351562e-05]
[-9.76562500e-04 -9.15527344e-05 1.83105469e-04 -1.83105469e-04]
...
[ 1.52587891e-04 2.13623047e-04 1.52587891e-04 6.10351562e-04]
[ 9.15527344e-05 -3.35693359e-04 4.88281250e-04 6.10351562e-04]
[-6.40869141e-04 2.74658203e-04 -2.44140625e-04 6.10351562e-05]]
图片分布位置同上
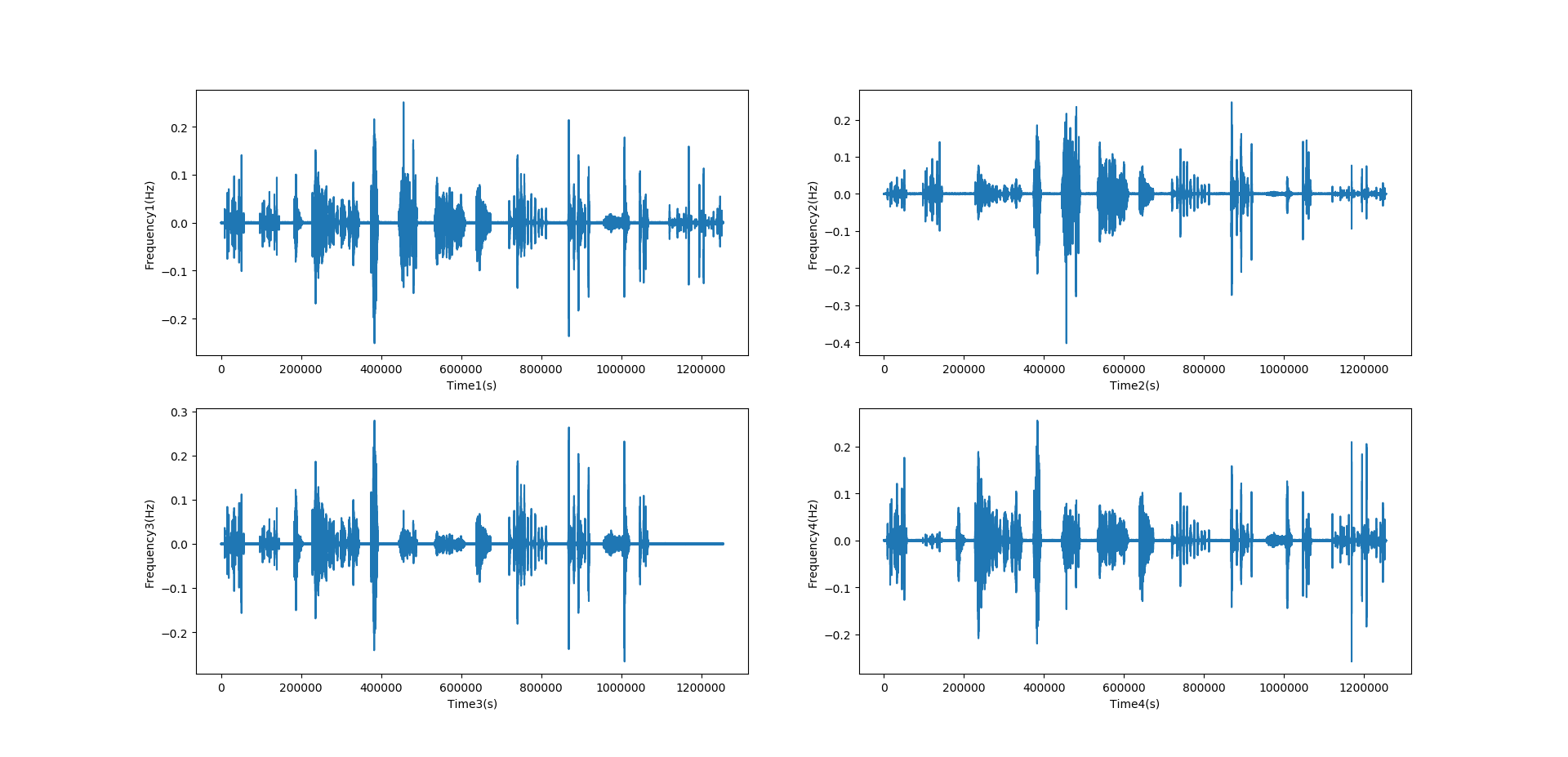
3).wave读取音频
import wave
import numpy as np
import matplotlib.pyplot as plt
f = wave.open(r"D:/奇怪的东西/杂/ov1_split1/doa_data/wav_ov1_split1_30db/test_0_desc_30_100.wav", "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
strData = f.readframes(nframes)#读取音频,字符串格式
waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int
waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化
waveData = np.reshape(waveData,[nframes,nchannels])
f.close()
print('采样率:',framerate)
plt.figure(1)
plt.subplot(2,2,1)
plt.plot(waveData[:,0])
plt.ylabel('Frequency1(Hz)')
plt.xlabel('Time1(s)')
plt.subplot(2,2,2)
plt.plot(waveData[:,1])
plt.ylabel('Frequency2(Hz)')
plt.xlabel('Time2(s)')
plt.subplot(2,2,3)
plt.plot(waveData[:,2])
plt.ylabel('Frequency3(Hz)')
plt.xlabel('Time3(s)')
plt.subplot(2,2,4)
plt.plot(waveData[:,3])
plt.ylabel('Frequency4(Hz)')
plt.xlabel('Time4(s)')
plt.show()
#结果显示
采样率: 44100
图片分布顺序同上:
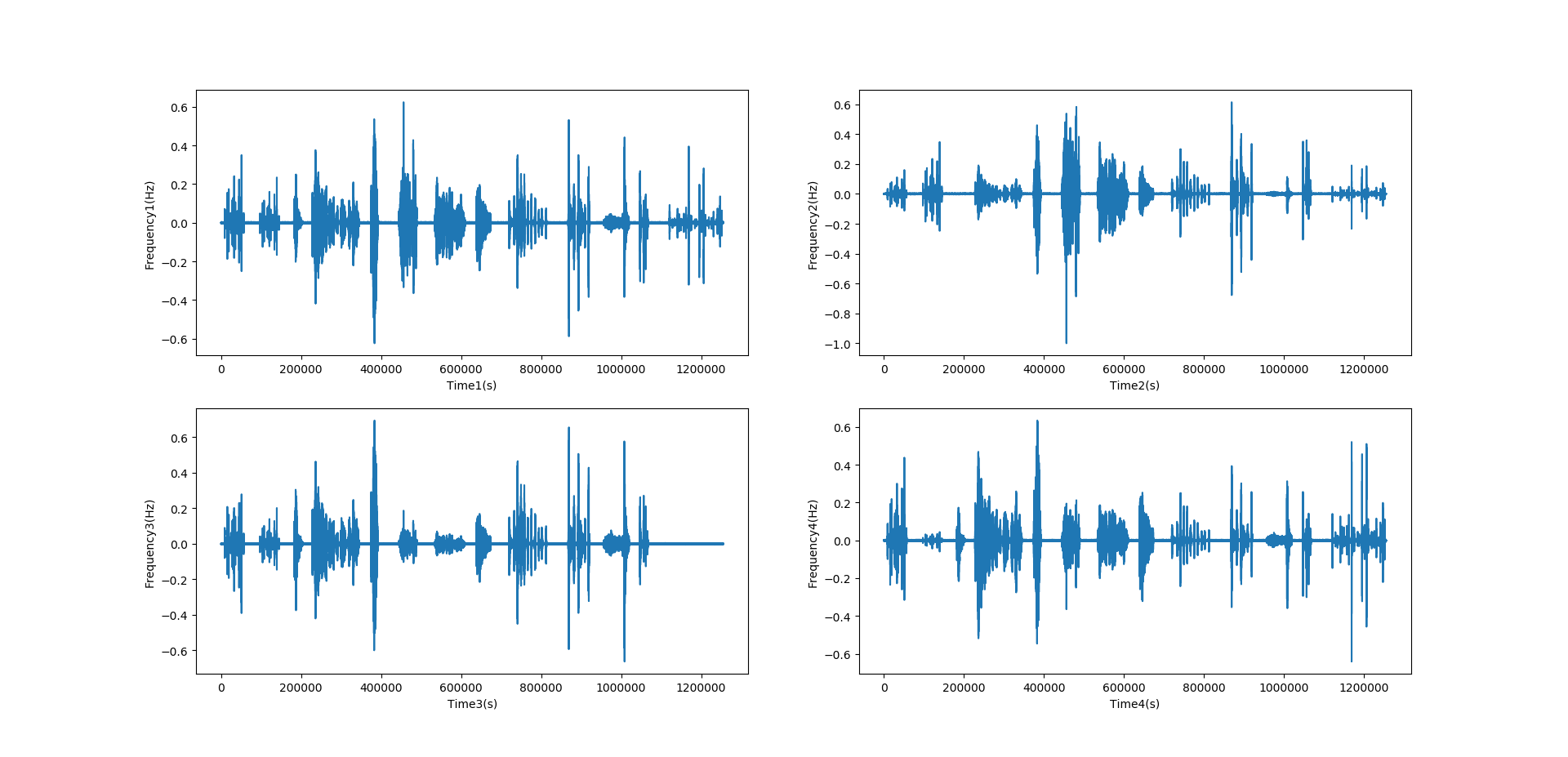
4).librosa读取音频
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
path = "D:/奇怪的东西/杂/ov1_split1/doa_data/wav_ov1_split1_30db/test_0_desc_30_100.wav"
fs = 44100 # 按多少采样率来加载音频,如果为none,则默认为22050
sig1,sr1 = librosa.load(path, sr=fs, mono=True, offset=0.0, duration=None)
sig2,sr2 = librosa.load(path, sr=fs, mono=False, offset=0.0, duration=None)
print(sig1.shape)
print(type(sig1))
print(sig2.shape)
print(type(sig2))
original_fs = librosa.get_samplerate(path) # 读取原始音频的采样率
print('原始音频采样率:',original_fs)
plt.figure(1)
plt.subplot(2,1,1)
librosa.display.waveplot(sig1, sr=fs, x_axis='time', offset=0.0, ax=None)
plt.subplot(2,1,2)
librosa.display.waveplot(sig2, sr=fs, x_axis='time', offset=0.0, ax=None)
plt.show()
#结果显示
(1255275,)
<class 'numpy.ndarray'>
(4, 1255275)
<class 'numpy.ndarray'>
原始音频采样率: 44100
由于librosa.display.waveplot只有打印单音频和立体声的形式,所以多通道的音频只能是一个合成立体声,如图,第一个为单音频,第二幅图为立体声
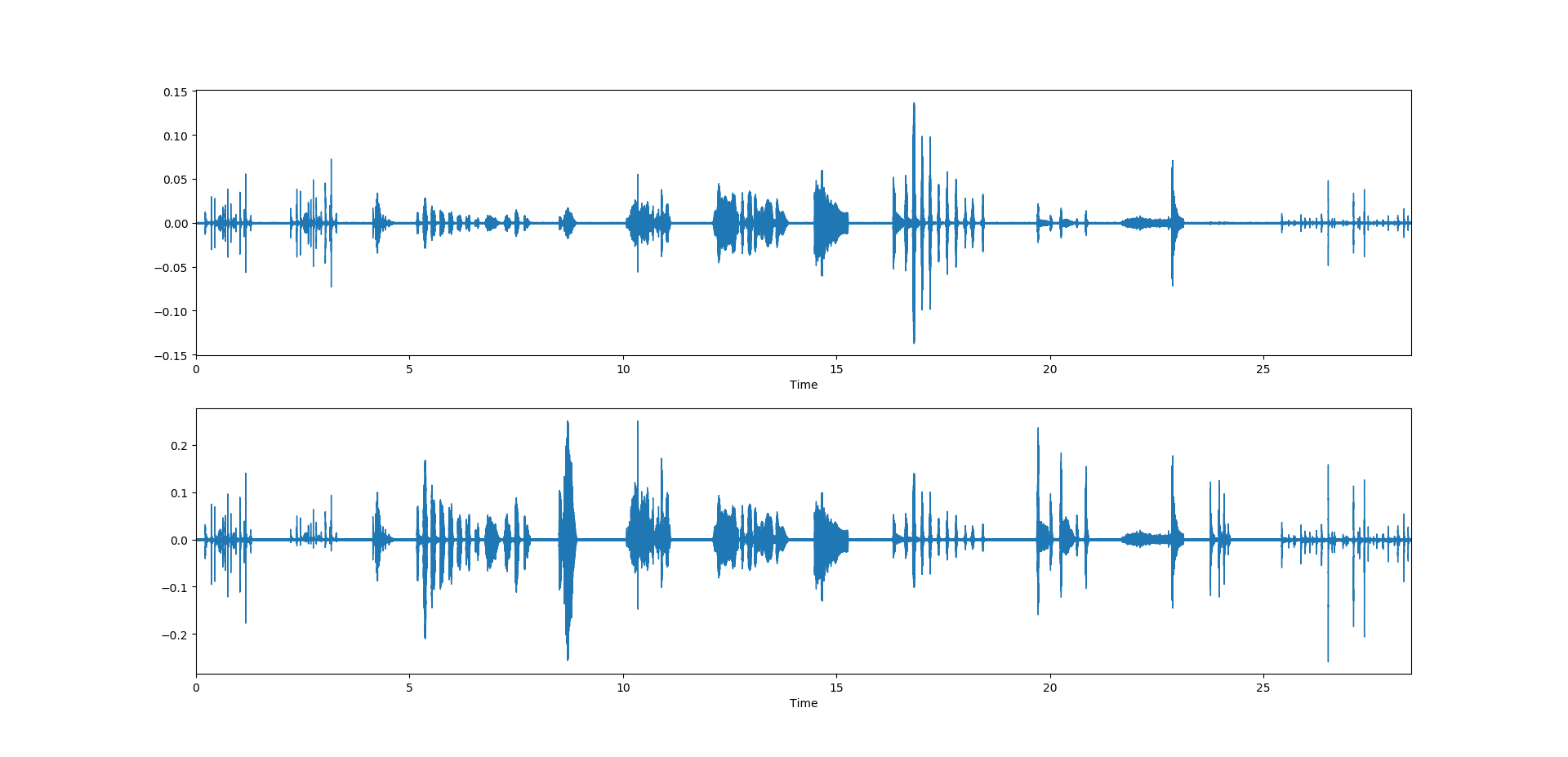
如果想看多个通道的图,可以将librosa.display.waveplot都替换为plt.plot,可以生成如下图例(上图中的第二幅展开图):

二、加入指定信噪比的高斯白噪声
加入指定信噪比的高斯白噪声,我们首先可以定义一个高斯白噪声加入的文件,此处我命名为awgn.py文件,这个文件是由matlab中awgn函数改编过来的,可以直接复制粘贴使用,效果已经反复验证,是正确的。
import numpy as np
def awgn(x, snr, out='signal', method='vectorized', axis=0):
# Signal power
if method == 'vectorized':
N = x.size
Ps = np.sum(x ** 2 / N)
elif method == 'max_en':
N = x.shape[axis]
Ps = np.max(np.sum(x ** 2 / N, axis=axis))
elif method == 'axial':
N = x.shape[axis]
Ps = np.sum(x ** 2 / N, axis=axis)
else:
raise ValueError('method "' + str(method) + '" not recognized.')
# Signal power, in dB
Psdb = 10 * np.log10(Ps)
# Noise level necessary
Pn = Psdb - snr
# Noise vector (or matrix)
n = np.sqrt(10 ** (Pn / 10)) * np.random.normal(0, 1, x.shape)
if out == 'signal':
return x + n
elif out == 'noise':
return n
elif out == 'both':
return x + n, n
else:
return x + n
然后,开始在原始音频加入高斯白噪声,这里就以第三种读取音频方式wave为例,添加指定信噪比为20dB和0dB的高斯白噪声,其他读取音频的添加方式一样。
import wave
import numpy as np
import matplotlib.pyplot as plt
from awgn import awgn
f = wave.open(r"D:/奇怪的东西/杂/ov1_split1/doa_data/wav_ov1_split1_30db/test_0_desc_30_100.wav", "rb")
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
strData = f.readframes(nframes)#读取音频,字符串格式
waveData = np.fromstring(strData,dtype=np.int16)#将字符串转化为int
waveData = waveData*1.0/(max(abs(waveData)))#wave幅值归一化
waveData = np.reshape(waveData,[nframes,nchannels]).T
snr = 0 #可以改成自己想要的
waveData2 = awgn(waveData, snr, out='signal', method='vectorized', axis=0)
f.close()
plt.figure(1)
plt.subplot(4,1,1)
plt.plot(waveData[0])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,2)
plt.plot(waveData[1])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,3)
plt.plot(waveData[2])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,4)
plt.plot(waveData[3])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.figure(2)
plt.subplot(4,1,1)
plt.plot(waveData2[0])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,2)
plt.plot(waveData2[1])
plt.ylabel('Frequency(Hz)')
plt.xlabel('Time(s)')
plt.subplot(4,1,3)
plt.plot(waveData2[2])
plt.ylabel('Frequency(Hz)')
plt.