我们有了字节流,为什么还需要字符流?
字符的底层是 字节 + 编码表 = 字符,字符是人能看懂的信息。

字符流在使用的时候,会以字节流为基础,把字节写入缓冲区,在缓冲区内根据编码类型(UTF-8,GBK等)编码成对应的字符。
如果程序运行中需要向硬盘里读入字符或者保存字符,使用字节流的话会由于没有缓冲区进行编码翻译,
程序运行环境与外界环境的编码方式不统一导致乱码。
但是如果使用字符流复制粘贴文件,那么在缓冲区内的编码解码过程会极大的拖慢复制时间。
字符流的使用:
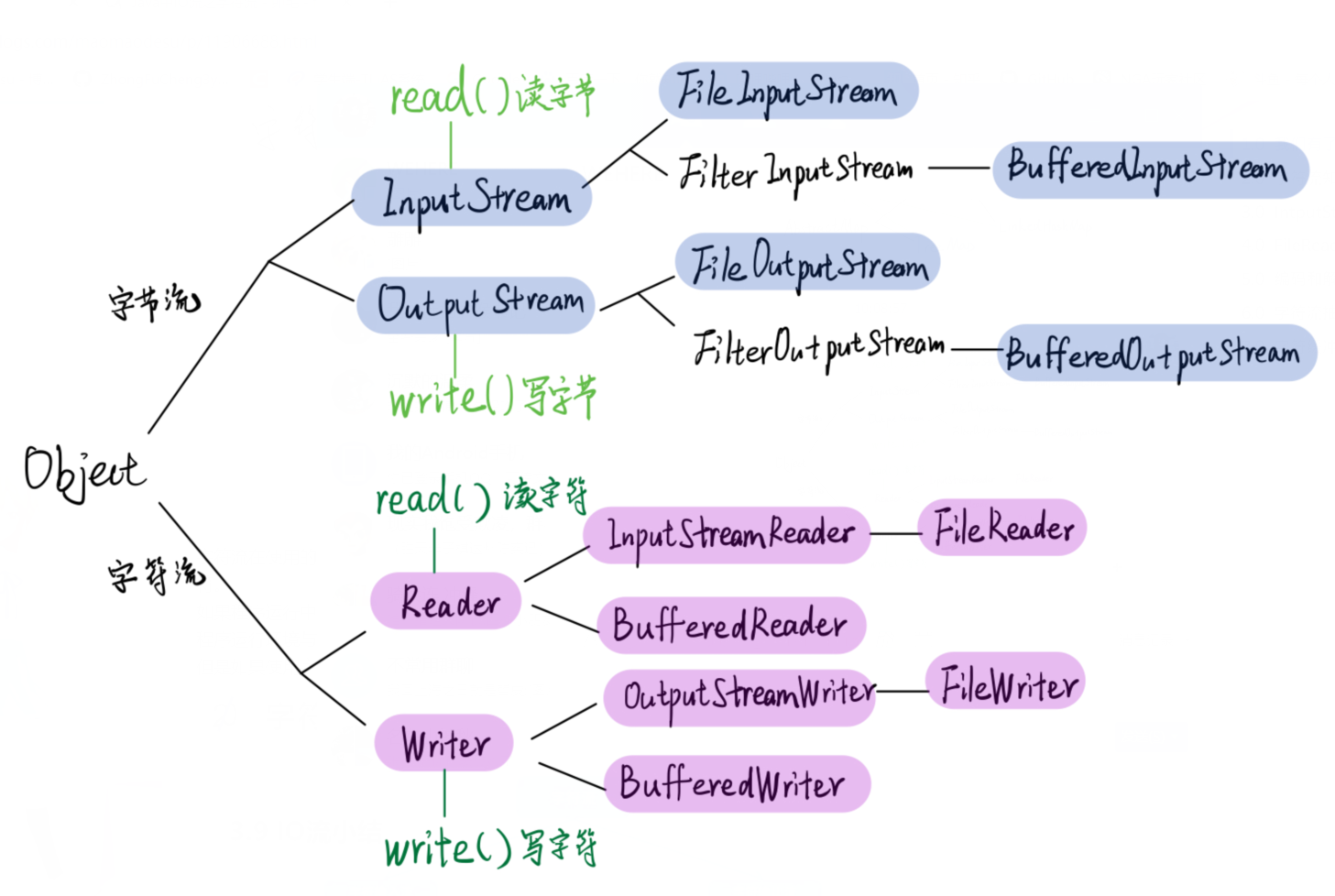
字符流抽象基类Reader和Writer分别实现了read和wirte方法,之后的
IntputStreamReader/OutputStreamWriter
FileReader/FileWriter
都使用read()和write()方法。
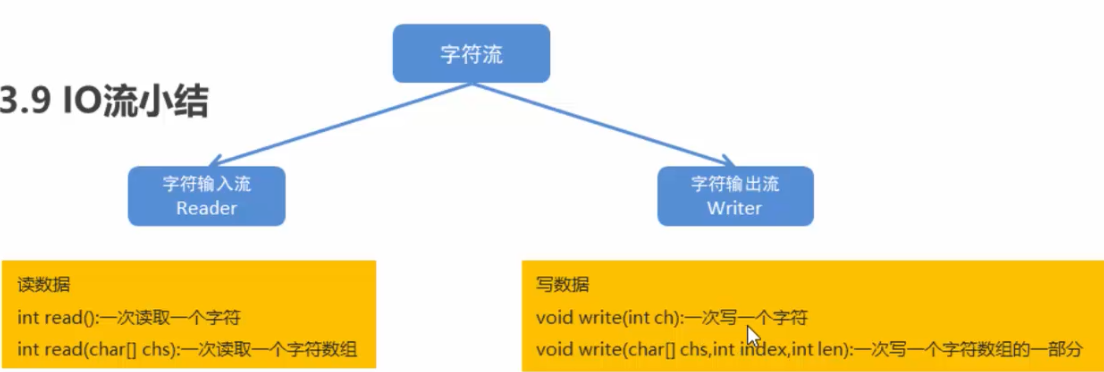
字符流的Writer()方法:
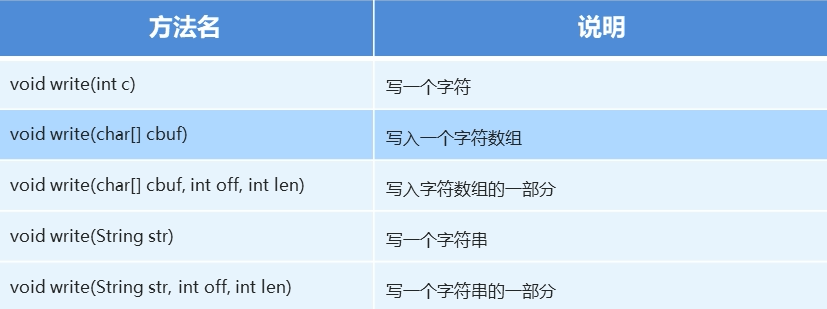
字符流的read()方法:

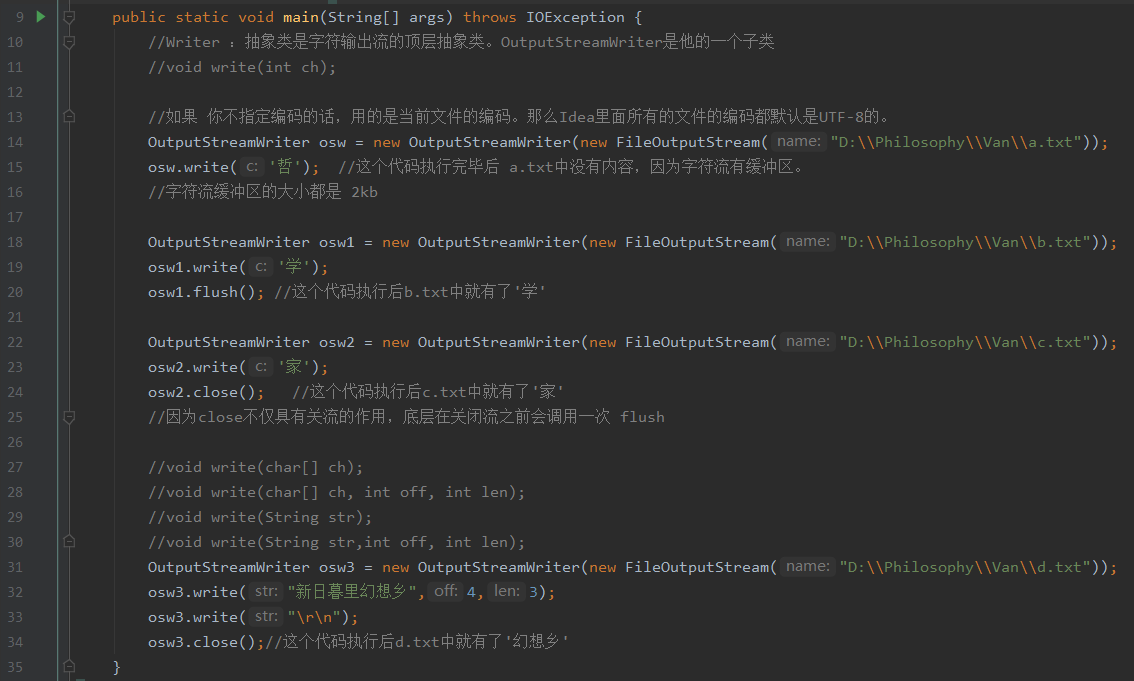
字符:

字符数组:
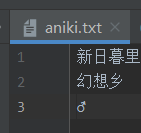
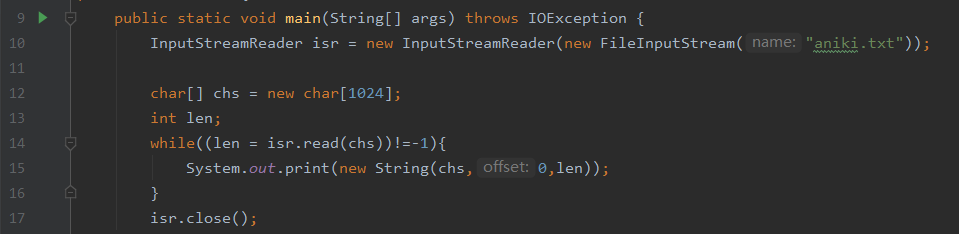
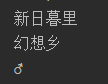
InputStreamReader/OutputStreamReader:
用法与字节流FileInputStream和FileOutputStream类似,但是它有缓冲区(不同于缓冲流)构造方法可以添加编码格式。
InputStreamReader/OutputStreamReader的底层原理:
以OutputStreamReader为例:

程序划分char[] chr = new char[1024];为字符流缓冲区,在缓冲区内部,把我们write("中国")中的"中国"
按照构造函数里的"utf-8"解码成字节,然后存在缓冲区内部。
我们调用osw.flush();方法才能把缓冲区刷入osw.txt。进入的方法是调用字节流,这也是为什么字符流的构造方法里
必须传入一个字节流。在osw.txt那边接收到了传入的字节,由记事本等编辑器把字节转码成字符。
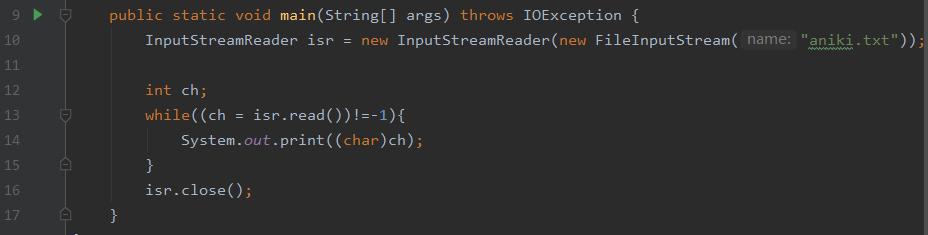
同理IntputStreamReader:

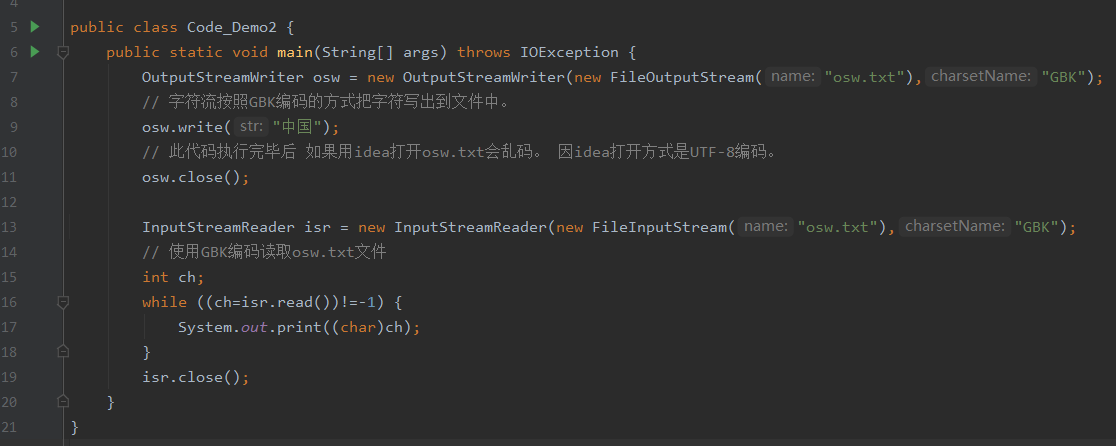
如果编码格式不正确,比如utf-8写成了GBK:
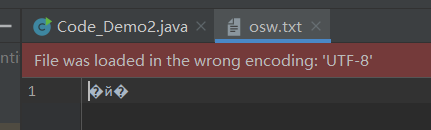
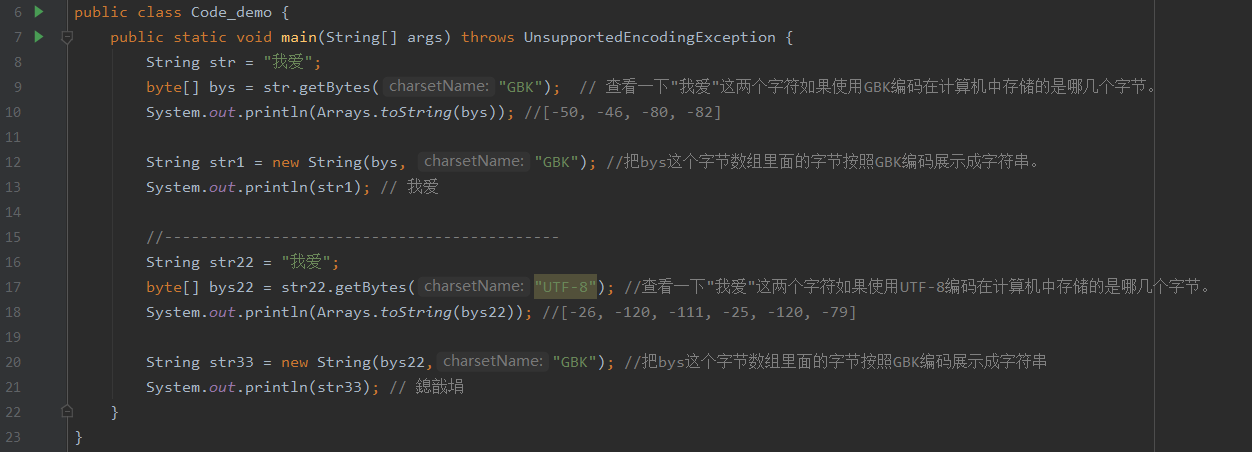
String类提供的编码解码方法:

FileReader/FileWriter:
用于读写字符文件的便捷类,用法与字节流FileInputStream和FileOutputStream相同,构造中不可以修改编码格式。


FileReader:

FileWriter:

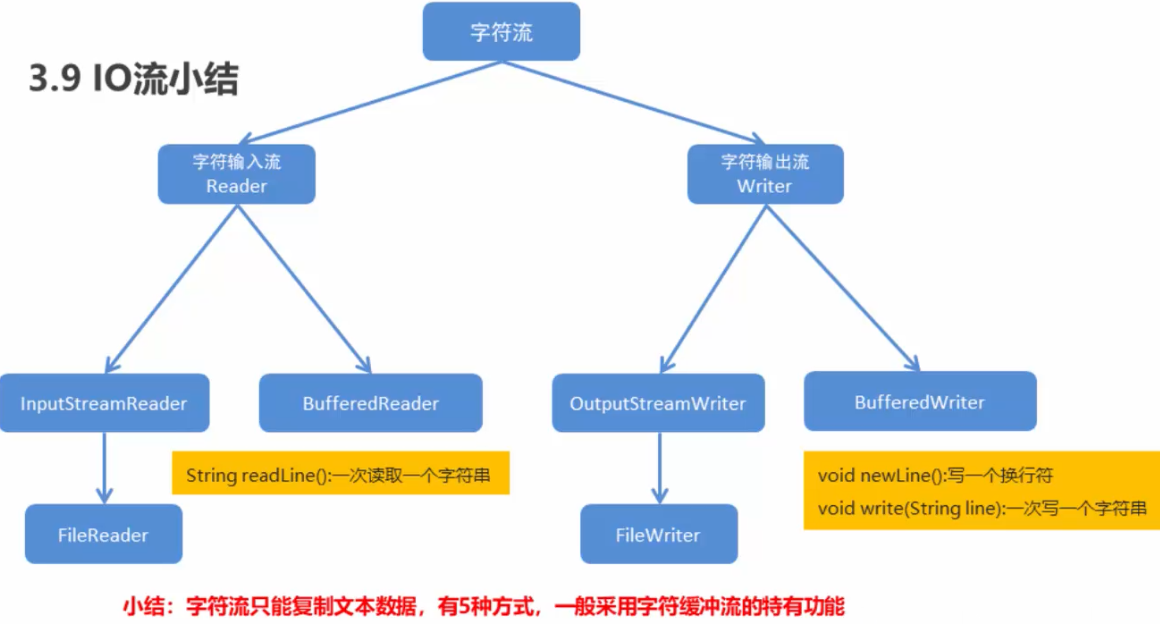
字符缓冲流:

特有方法:
readLine();读入一行
newLine();写入换行
例题:
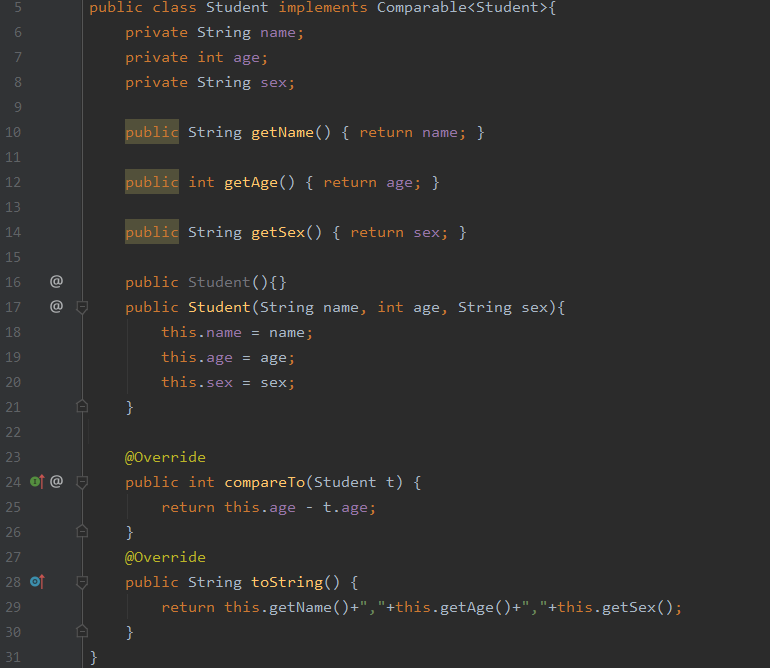
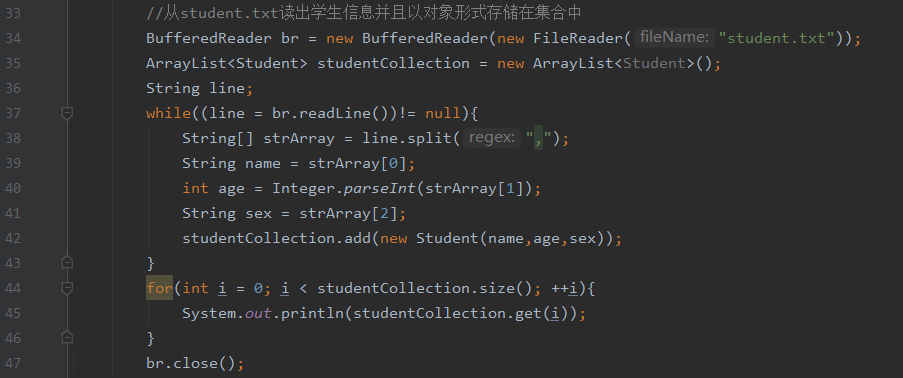
要求把5个学生对象存入到集合中,对象的信息写出到当前项目下的student.txt文件中,要求每个学生信息独占一行,
按照年龄大小排序。
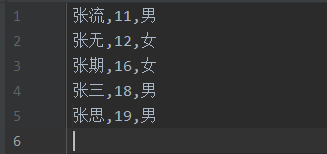

再从student.txt读出学生信息并且以对象形式存储在集合中,并且输出。