能打能扛有颜值,爬一波对奥运健儿的评论。
""" 爬一下B站“杀疯了,这就是国家队的美貌吗?”,视频地址: https://www.xx.com/video/BV1uU4y1H7wL?from=search&seid=14179860062243648577&spm_id_from=333.337.0.0 """ import pprint import random import requests import csv import time import json # 创建csv文档 f = open('杀疯了.csv', mode='a', encoding='utf-8-sig', newline='') csvWriter = csv.DictWriter(f, fieldnames=[ '评论者姓名', '评论者性别', '评论时间', '获赞数', '评论内容', ]) # 写入头 csvWriter.writeheader() # 开始时间戳 startTimeStamp = int(time.time() * 1000) # 毫秒级 # 请求头 headers = { "cookie": "_uuid=BE35640F-EB4E-F87D-53F2-7A8FD5D50E3330964infoc; buvid3=D0213B95-F001-4A46-BE4F-E921AE18EB67167647infoc; CURRENT_BLACKGAP=1; CURRENT_QUALITY=0; rpdid=|(u))ku~m)kJ0J'uYJuRRRYmk; CURRENT_FNVAL=976; video_page_version=v_old_home_17; blackside_state=1; LIVE_BUVID=AUTO1516364619569495; PVID=1; bsource=search_baidu; innersign=1; sid=78290ki3", "referer": "https://www.xx.com/video/BV1uU4y1H7wL?from=search&seid=14179860062243648577&spm_id_from=333.337.0.0", "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36", } data = { "callback": f"jQuery172028036378029383635_{startTimeStamp}", # 这里的时间戳要换成我们请求的时候当时的时间戳 "jsonp": "jsonp", "next": "0", # 翻页 "type": "1", "oid": "674425220", # "mode": "3", "plat": "1", "_": f"{startTimeStamp}", } # 多页爬取 for page in range(1, 100 + 1): # 爬100页 print(f'======开始爬取第{page}页的数据======') time.sleep(random.randint(2, 5)) # 休眠 nextTimeStamp = int(time.time() * 1000) url = f'https://api.xx.com/x/v2/reply/main?callback=jQuery172028036378029383635_{startTimeStamp}&jsonp=jsonp&next={page}&type=1&oid=674425220&mode=3&plat=1&_={nextTimeStamp}' # 开始请求网页 response = requests.get(url=url, headers=headers) # print(response.text) # 返回的格式像json但是不是json,得处理 json_data = json.loads(response.text[42:-1]) # 取字符串的第42位到最后一位 # pprint.pprint(json_data) # 现在得到的就是json数据 # 提取需要的部分 data = json_data['data']['replies'] # 这是个列表,现在从列表里去提取评论者姓名,性别,评论时间,点赞数,评论内容 print(f"====第{page}页总共有{len(data)}条数据====") time.sleep(2) # 休眠两秒以便查看 # pprint.pprint(data) for item in data: name = item['member']['uname'] # 评论者姓名 sex = item['member']['sex'] # 评论者性别 ctime = item.get('ctime') # 评论时间 content_time = time.strftime("%Y-%m-%d %H:%M", time.localtime(ctime)) # 还原时间戳成本地时间 like = item['like'] # 点赞数 content = item['content']['message'] print(name, sex, content_time, like, content, sep=" | ") # 写入到csv文档 dit = { '评论者姓名':name, '评论者性别':sex, '评论时间':content_time, '获赞数':like, '评论内容':content, } csvWriter.writerow(dit) # 按行写入到csv文档 print(f'======取第{page}页的数据爬取完成======') time.sleep(2) # 休眠两秒以便查看
程序运行结果:

数据保存结果:
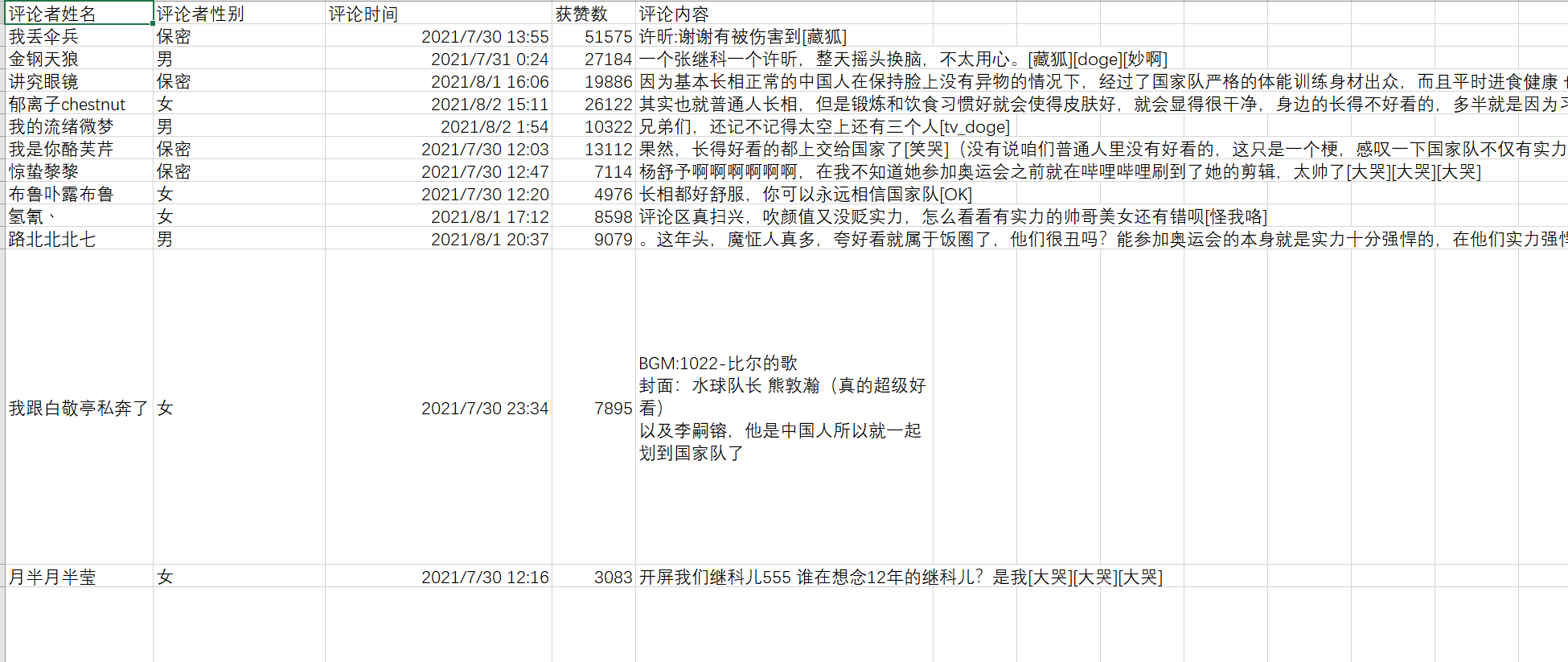
本文仅用于学习交流,不具有任何商业用途。如有问题,请与我联系,我会即时处理。
据说网址里的callback参数会影响数据的完整性,具体没测试过,下次测试下。
逐梦很累,坚持加油。