实验目标:
对数据包负载文件进行分割,可以让分割块近似1000字节。
背景:
PACK是一种基于接收端的字节缓存算法。核心思想是利用当前的数据预测下一步需要接收的数据。
但是数据块不应该被分割的太小,这样的话会耗费过多的内存和磁盘; 当然也不能分割的太大,
数据块过大会导致预测的命中率降低。具体的PACK算法中,我们需要找到前后两个分割点,来确定
一个数据块,然后根据此数据块来预测下一次需要接收的数据。当分割点只受其内容影响的时候,
发送数据的修改对数据的预测影响有限。
预备知识:
rabin指纹通过数据内容计算,因此可以用于计算分割点。原理可以参考维基百科条目:https://en.wikipedia.org/wiki/Rabin%E2%80%93Karp_algorithm。
在统计学中,中位数(median)被定义为一系列数据的中点。在这一数据点所有数据的一半在其
之上而另一半在其之下。百分位点用于定义数据集或数据分布中等于或者小于一个特定数据值的个体
百分数。对数据集排序后,我们可以将数据分成4等份,分别为:最小值,25百分位点,中位数,
75百分位点,最大值。标准差表示一个数据集中变异性的平均值,实际含义是与均值的平均距离。
标准差越大,每一个数据点与数据分布的均值的平均距离越大。
实验步骤:
- 从pacp文件读取TCP的数据负载部分。
- 针对TCP的数据负载部分计算rabin指纹并记录采样点,采样点将作为数据的分割点。
- 通过数据的分割点来计算分割区间的大小
- 使用R语言来分析分割区间的数据分布
实验结果:
1.验证pic.pcap图片数据
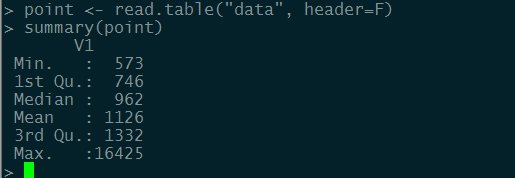
上图为R语言分析的结果,通过上图我们可以观察出两点:
中位数为962,均值为1126,中位数和均值接近说明数据集中的极大值或极小值的影响有限
75百分位点为1332说明整个数据集的四分之三的数据都是小于1332
在针对data数据集计算其标准差,那么得出的标准差为:540.267410224。说明数据集中
所有数据到均值的平均距离就是大约540。
2.验证wzhvod.pcap数据
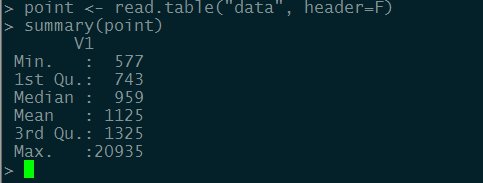
通过上图可以观察数据大部分分布在1325以内。其标准差为:562.128433851。
3.对比实验
使用python的random模块在【570, 2000】之间随机生成样本空间,观察其数据特征。
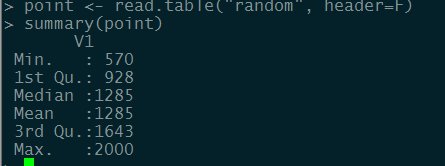
此数据集的标准差为:413.00726093
通过实验1,2和3的标准差的对比,我觉得差距为100多应该可以接受。实验1,2和实验3的75百分位点
的差距也不是太大。
实验结论:
1.采用rabin指纹的方法可以将数据按内容切分。
2.切分出的数据块可能出现极大值,出现此问题的原因是:计算出的指纹没有被取样。