郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IJCNN, pp.2243-2250, (2017)
Abstract
移动机器人在未知环境中的自主导航是移动机器人技术的一个重要课题。本文讨论了一种在未知环境中导航到已知目标位置的新策略,结合使用"go-to-goal"方法和强化学习与生物学合理的脉冲神经网络。虽然"go-to-goal"方法本身可能会为大多数环境提供解决方案,但这项工作中增加的神经强化学习产生了一种策略,可以在尽可能短的时间内将机器人从起始位置带到目标位置。为了实现这一目标,我们提出了一种基于脉冲神经网络的强化学习方法。所提出的使用资格迹的生物动机延迟奖励机制产生的贪婪方法,导致机器人在接近尽可能短的时间内到达目标。

I. INTRODUCTION
由于自动驾驶汽车、外星探索、救援任务和类似领域的出现,关于无人驾驶汽车在已知和未知环境中自主导航的研究正在迅速发展。在本文中,考虑了移动机器人在包含障碍物的环境中朝向给定目标位置的自主导航问题。该问题的一个示例如图1所示。
在图1中,移动机器人是圆形物体"Robot"。从机器人中心发出的线条是超声波传感器光束,用于检测任何障碍物。超声波传感器的检测范围有限。矩形物体是可以被超声波传感器感应到的壁状障碍物。标记为"Start"的点是机器人的初始位置。图中标有"Goal"的方形物体是机器人必须导航到的全局目标。假设机器人有办法检测目标相对于自身的位置。机器人不知道障碍物的形状和位置,这使得这成为一个具有挑战性的问题。
A. Previous Work
B. Overview of the Proposed Solution
我们首先讨论[11]中提出的导航策略,然后讨论改进该策略的强化学习算法。
在"go-to-goal"方法[11]中,移动机器人在没有障碍物的情况下朝着目标导航。当遇到障碍物时,它会原地转动(向左或向右)并使用墙壁跟随控制器跟随障碍物。机器人在满足后续部分中讨论的特定条件后离开墙壁跟随模式。然后朝着目标前进。图2说明了这个简单环境的解决方案。
II. BACKGROUND
在强化学习中,智能体通过发现最大化其收到的总期望奖励的动作来学习。在强化学习算法Q学习中,智能体的状态-动作价值函数,即Q值在每次状态转换后更新。因此,在达到某个状态时,只会更新前一个状态的Q值。然而,由于它发生在包括导航问题在内的许多问题中,智能体经常采取奖励延迟的动作。这个问题被称为"信度分配问题"或"延迟奖励问题"[4]。
为了解决"延迟奖励问题",Izhikevich [13]提出了一种称为带资格迹的多巴胺调节的Hebbian脉冲时序依赖可塑性(STDP)的机制。这将在以下小节中简要说明。
A. Hebbian STDP
B. Dopamine Modulated STDP
III. REINFORCEMENT LEARNING USING SPIKING NEURAL NETWORK
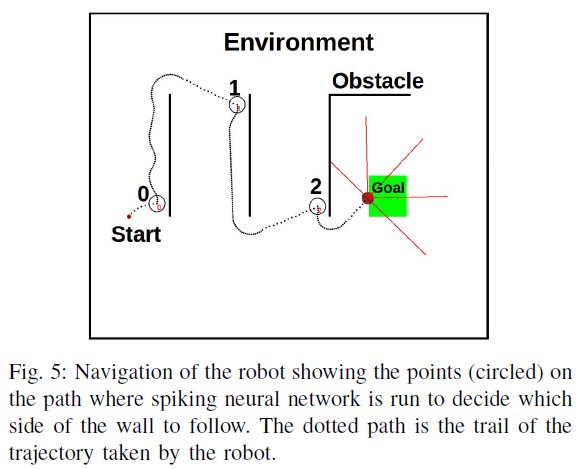
这项工作中提出的导航问题的解决方案涉及一个学习部分,其中机器人做出以下决定:当直接面对障碍物时,1)通过右转跟随左侧有障碍物的障碍物或 2)通过左转跟随右侧有障碍物的障碍物。该决策场景如图5所示。机器人在标有圆圈的区域(图5中标记为"0"、"1"和"2")处做出跟随墙的决策。
设计的脉冲神经网络如图6所示。它是一个两层网络:一个输入层有88个兴奋性泊松脉冲神经元,一个输出层有2个兴奋性脉冲神经元。输入层以全连接方式连接到输出层。输入神经元编号为0到87,输出神经元标记为LEFT和RIGHT。强化学习问题的状态由输入层表示。这是通过以这样一种方式计算输入发放率来实现的,即对于每个状态,不同的输入神经元群体都会发放。这种状态的编码已经在[18]中完成。对于每个输入神经元 i,使用频率fi来生成泊松脉冲序列。fi计算如下:

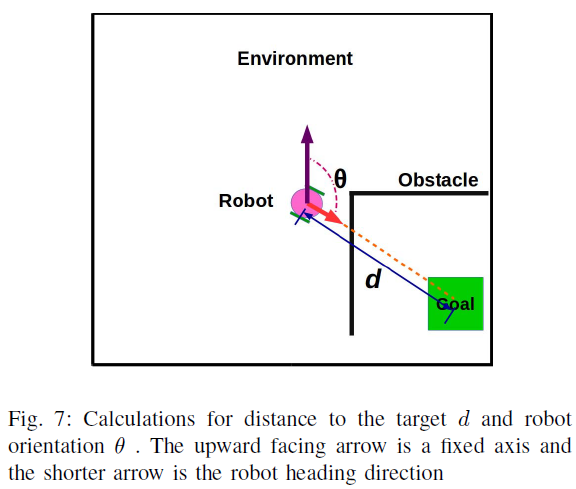
其中θ是机器人航向方向相对于固定轴的方向,以度为单位,d是机器人中心到目标位置(方形目标的中心)的距离,以像素为单位。这两个参数的计算如图7所示。对于θ,以模拟环境平面中指向上方的固定轴为参考,沿顺时针方向测量。θ可以从0°到360°取值。
参数di和θi使得(di, θi) ∈ D × Θ,其中:
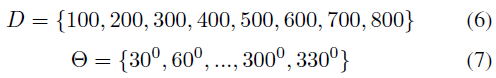
换句话说,D是机器人智能体到目标的离散距离集合,Θ是机器人航向方向的离散方向集合。因此,可能对(di, θi)的总数为n(D)n(θ) = (8)(11) = 88,这决定了图6中网络输入层的神经元数量。这里n(S)表示集合S的基数。σ1和σ2是确定曲线fi v/s (d, θ)的扩展的设计参数。
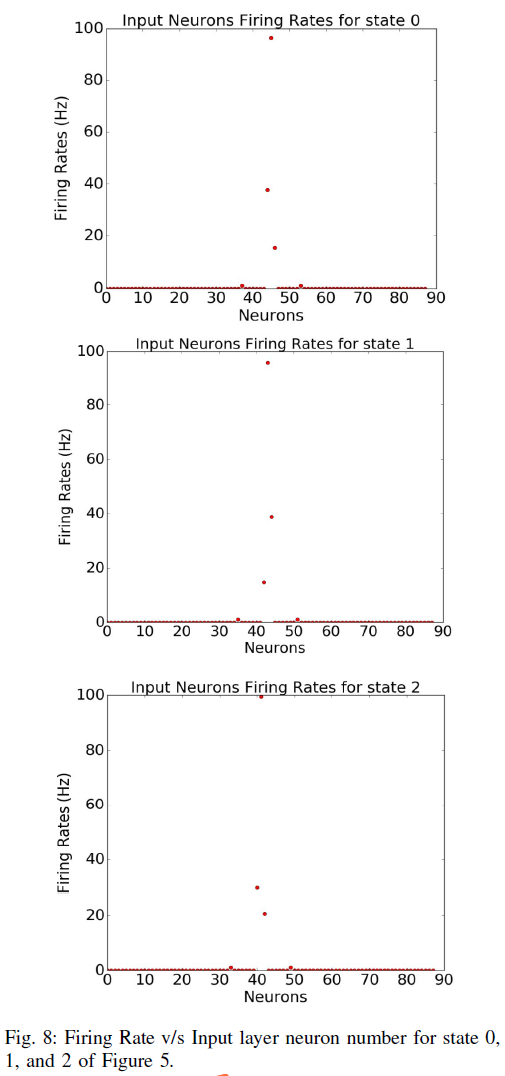
因此,强化学习问题中的每个状态都由有序对(d, θ)表示,并且计算出的输入发放率fi使得不同的输入神经元组被不同的有序对(d, θ)激发。例如,在图5中,标记为"0"、"1"和"2"的圆圈是测量d和θ并为88个输入神经元中的每一个计算fi的位置。 对于点"0"、"1"和"2",激发的神经元数量是不同的。为了可视化这种发放行为,图8中显示了图5中每个状态"0"、"1"和"2"的发放率与输入神经元数量的关系图。
当神经网络运行时,其输出层会产生两个输出发放率:fleft和fright,对应于图6中标记为"LEFT"和"RIGHT"的输出神经元。在做墙壁跟随决策时,如果fleft大于fright,则机器人决定通过右转来跟随其左侧的障碍物。否则,机器人决定通过左转来跟随其右侧的障碍物。

IV. THE COMPLETE PROPOSED SOLUTION
A. Detailed Algorithm
V. SIMULATION SETUP, RESULTS AND DISCUSSION
VI. CONCLUSION