最近一段时间由于业务需要,对因果推断进行研究,针对精准营销、用户增长、广告、模型可解释性等领域都有比较广泛的应用。本文主要从原理+实践角度去讲解一下相关的因果推断的工具或方法。以下是主要内容:
一、双重差分法
二、Uplift Model
三、Causal ML
四、EconML
五、Dowhy
六、模型可解释性
1、ShapleyValue
2、Lime
----------------------------------------------------------------------------------------------------------------------------------------
一、双重差分法(DID):DID(difference-in-differences model)也叫双重差分模型。
1、主要原理:
(1)通过将样本数据分成实验组和对照组,实验组是施加干预的一组,对照组是未施加干预的一组。
(2)通过对上述两组样本进行观察指标(也称目标指标)分析其变化,一般是转化率等KPI指标
(3)分别计算干预前后实验组和对照组对应的目标指标的差分结果
(4)计算两组最终的差分结果。
如下图所示:

双重差分的结果:ATE=(A2-A1)-(B2-B1)
2、工业实践:
根据公示的推导,双差分模型方程式可以写成下面表达式:
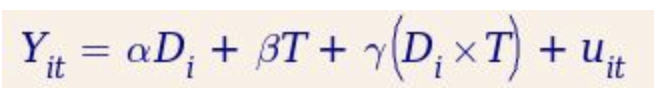
如果按照时间差分,则得到如下结果
![]()
再次按照干预前后进行差分,得到结果如下:
![]()
由此可见,交叉项的系数就是我们需要求解的因果效应ATE的值。
工业中一般实现的方式如下:


import statsmodels.formula.api as smf import pandas as pd v1 =[0.367730,0.377147,0.352539,0.341864,0.29276,0.393443,0.374697,0.346989,0.385783,0.307801] t1 = [0,0,0,0,1,0,0,0,0,1] g1 =[1,1,1,1,1,0,0,0,0,0] tg1 = [0,0,0,0,1,0,0,0,0,0] aa = pd.DataFrame({'t1':t1,'g1':g1,'tg1':tg1,'v1':v1}) X = aa[['t1', 'g1','tg1']] y = aa['v1'] est = smf.ols(formula='v1 ~ t1 + g1 + tg1', data=aa).fit() y_pred = est.predict(X) aa['v1_pred'] = y_pred print(est.summary()) print(est.params)
输出结果如下所示:
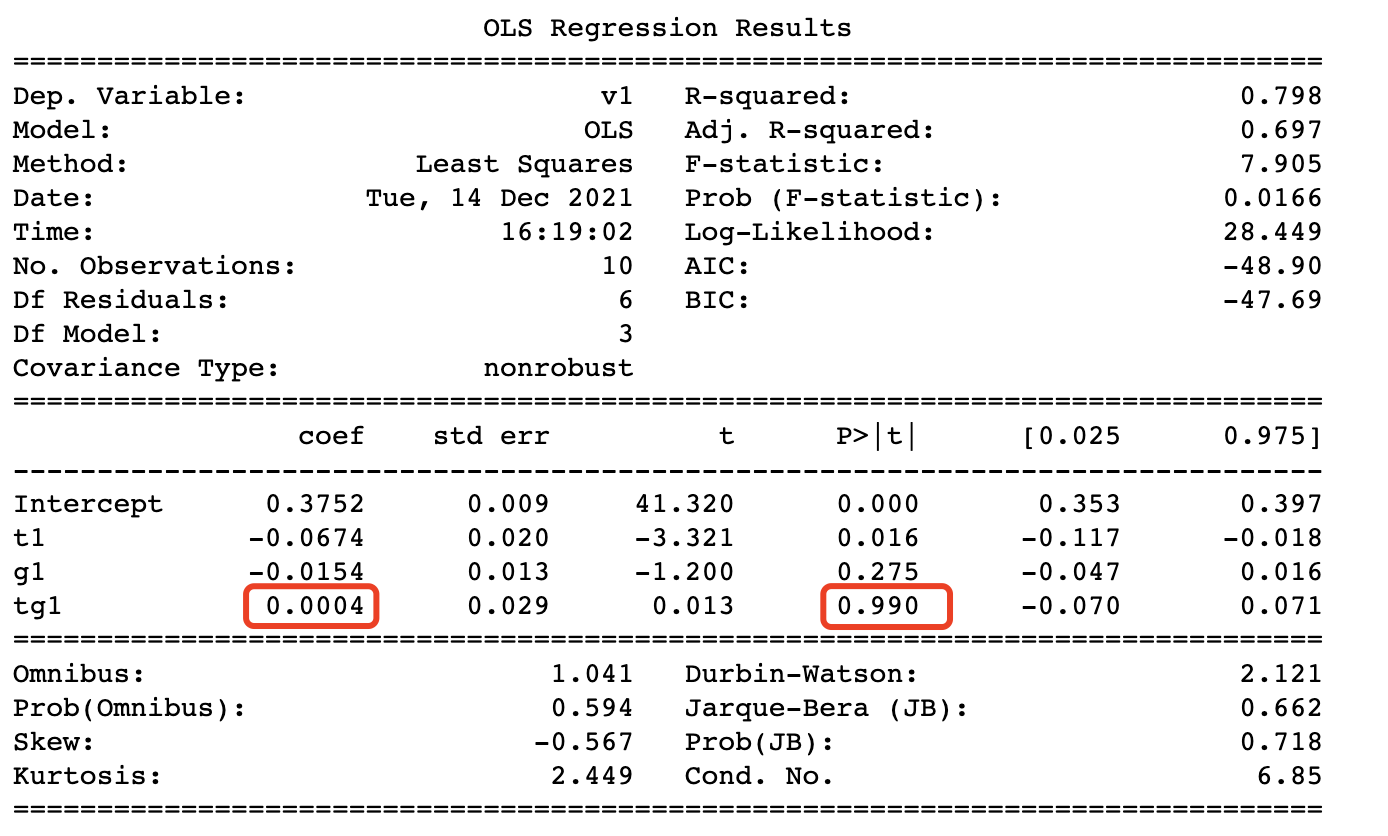
交叉项的系数就是DID结果,处理效应。P>| t |为其P值,小于0.05表示差异显著。
二、Uplift Model (增益模型)
1、基本原理:Uplift models预测增量值,也就是Lift的部分:
在营销领域中,我们经常会将人群划分成四个象限,横坐标表示无干预下用户购买情况,纵坐标是用户在有干预下的购买状况。如下图所示:
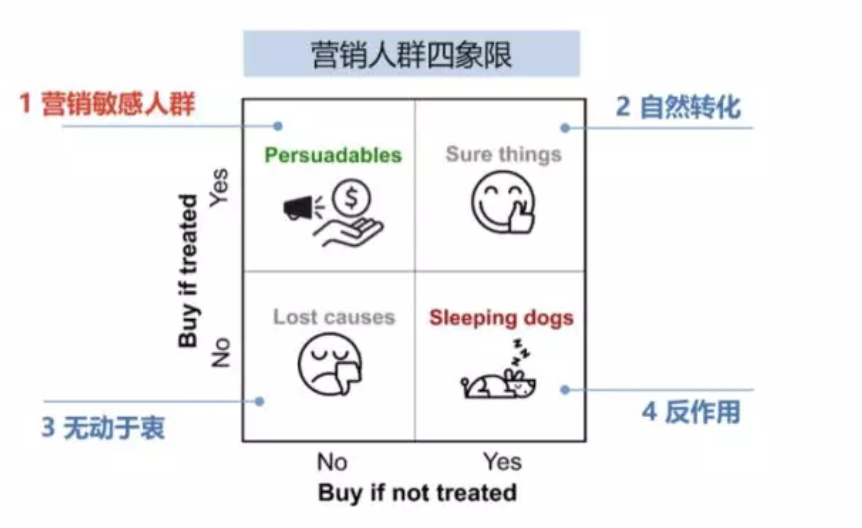
(1)第1类人群的购买状况在干预后发生了正向变化,如果我们不对这类人群进行干预,那他有可能是不购买的,但是干预之后的购买概率有极大提升,所以这类人群是我们真正想要触达的用户,即营销敏感人群。
(2)第 2 类和第 3 类,在干预前后的购买状况没有变化,所以预算花费可能是浪费。
(3)第4类比较特殊的人群,虽然其在干预前后的状态有跳变,但这种跳变不是我们希望看到的,因为确实有一些人群对营销是反感的,所以对这类人群我们应该极力避免触达。
Uplift Model 正是为了识别我们想要的营销敏感人群。其主要方法有:
(1)Two-Model Approach:分别通过模型对实验组和对照组的目标指标进行拟合,最后两个模型的差值则为Lift。
![]()
(2)One-Model Approach:模型直接以实验组与对照组的差值作为目标进行拟合
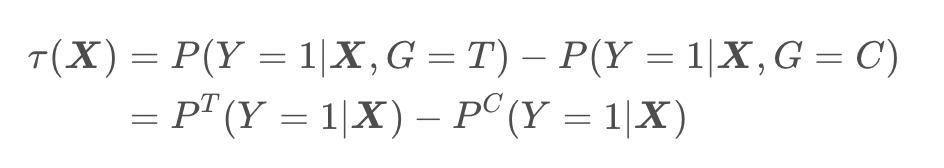
(3)树模型
问题1:Uplift Model 与 Response Model之间的区别:
(1)Response Model 的目标是估计用户看过广告之后转化的概率,这本身是一个相关性,但这个相关性会导致我们没有办法区分出自然转化人群;
(2)Uplift Model 是估计用户因为广告而购买的概率,这是一个因果推断的问题,帮助我们锁定对营销敏感的人群。所以 Uplift Model 是整个智能营销中非常关键的技术,预知每个用户的营销敏感程度,从而帮助我们制定营销策略,促成整个营销的效用最大化。
(4)模型的评价指标:AUUC
AUUC实际上跟AUC有点类似,也是对应曲线下面的面积,如下图所示:
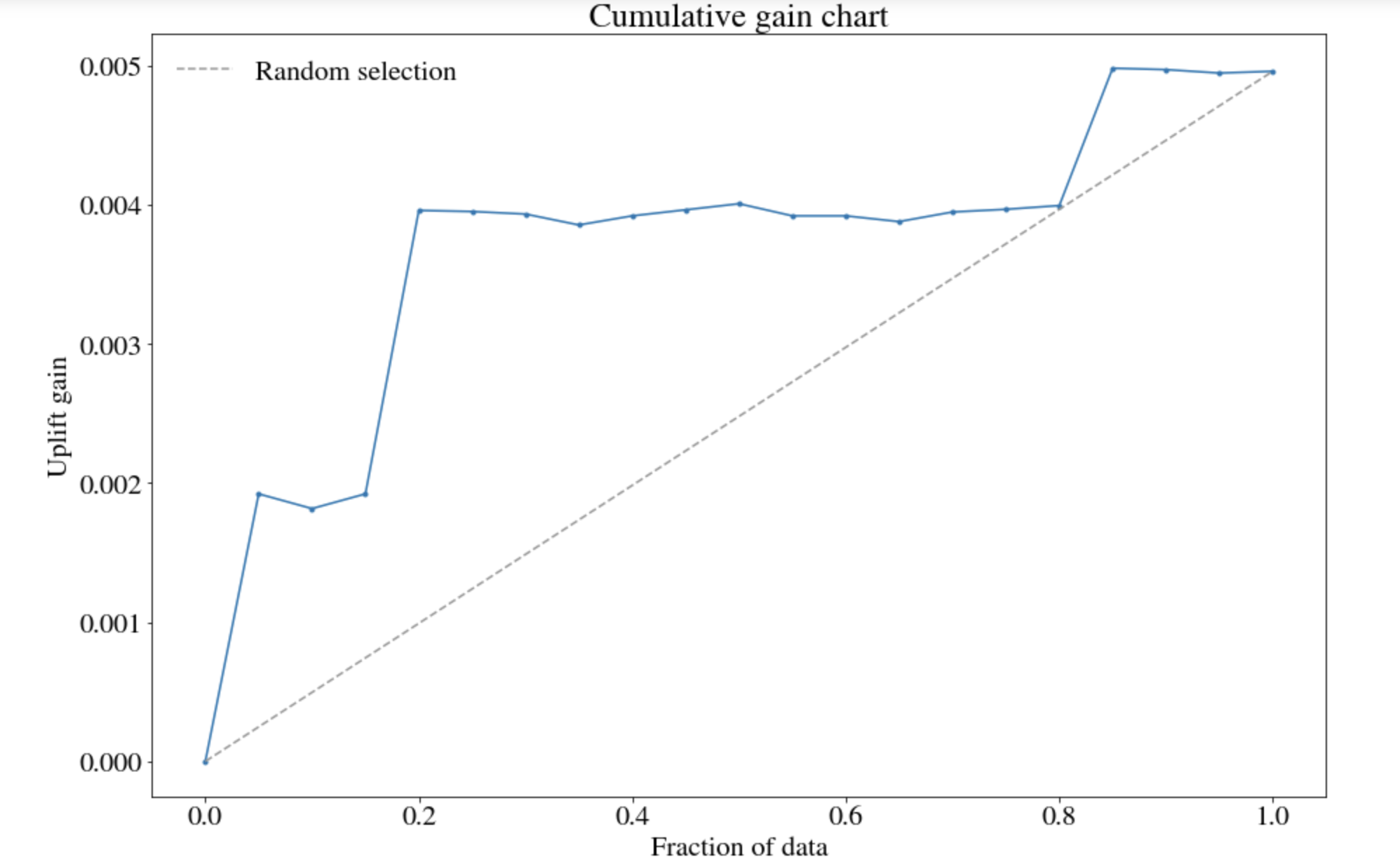
其中,虚线表示随机试验的结果,曲线则是按照模型的方式打分分成10等分,计算对应的增益的值(uplift gain)。两条曲线中间的面积就是AUUC,该指标越大表明模型表现越好。
2、代码实践
import numpy as np, matplotlib as mpl, matplotlib.pyplot as plt, pandas as pd from pylift import TransformedOutcome from pylift.generate_data import dgp # Generate some data. df = dgp(N=10000, discrete_outcome=True) up = TransformedOutcome(df, col_treatment='Treatment', col_outcome='Outcome', stratify=df['Treatment']) from pylift import TransformedOutcome up.randomized_search(n_iter=100,n_jobs=10,random_state=100) # 对所有参数grid search,十分耗时,使用时注意限制参数searching的数量 up.fit(**up.rand_search_.best_params_) up.plot(plot_type='aqini', show_theoretical_max=True) # 绘制aqini曲线 print(up.test_results_.Q_aqini) #AUUC
三、Causal ML
其实casual ml是一个实现uplift model的python开源工具包,项目地址:https://github.com/uber/causalml;相关的资料可以详细参考对应的文档说明即可。
四、EconML
econml同样是一个实现uplift model的开源工具包,文档地址:https://econml.azurewebsites.net/;项目地址:https://github.com/Microsoft/EconML;
五、Dowhy
Dowhy是集成causal graph 和potential outcome 两个框架。项目地址:https://github.com/microsoft/dowhy;主要包含四步:
- I. Model a causal problem
- II. Identify a target estimand under the model
- III. Estimate causal effect based on the identified estimand
- IV. Refute the obtained estimate
六、模型可解释性
1、ShapleyValue:项目地址:https://github.com/slundberg/shap;
shapleyvalue主要是计算每个特征对应的边际贡献度的方法来对模型进行解释。
2、Lime
Lime主要是通过假设局部是线性的方法来局部拟合原模型。