一、什么是模块?
模块:一个模块就是一个包含了python定义和声明的文件,文件名就是加上.py的后缀,但其实import加载的模块分为四个通用类别 :
1.使用python编写的代码(.py文件)
2.已被编译为共享库二和DLL的C或C++扩展
3.包好一组模块的包
4.使用C编写并连接到python解释器的内置模块
二、常用模块
time和datetime模块
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
print(time.time()) # 时间戳
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串
print(time.localtime()) #本地时区的struct_time
print(time.gmtime()) #UTC时区的struct_time
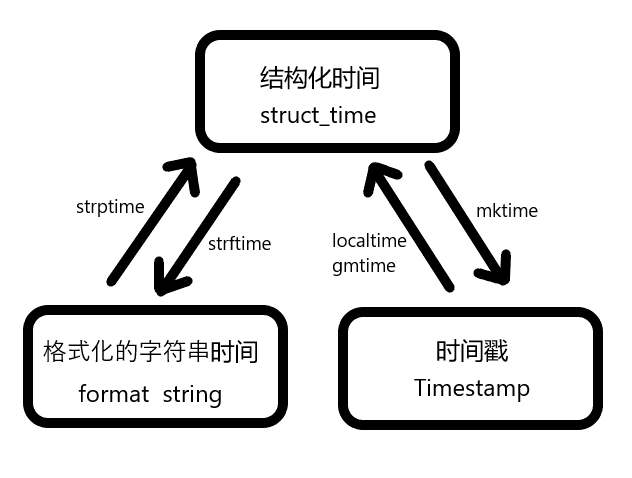
时间戳--------格式化的字符串时间----------结构化时间 三者关系如下图:
1 import time 2 3 #时间戳转换为结构化时间 4 print(time.localtime(time.time())) 5 6 #格式化转换为格式化的字符串时间 7 print(time.strftime("%Y-%m-%d %X", time.localtime()))
#时间加减-------datetime import datetime,time print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925 print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19 print(datetime.datetime.now() ) print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天 print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天 print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时 print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 c_time = datetime.datetime.now() print(c_time.replace(minute=3,hour=2)) #时间替换
random模块
import random print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数 print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数 print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5] print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合 print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716 item=[1,3,5,7,9] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
随机生成验证码


def v_code(): ret = '' for i in range(5): num = random.randint(0, 9) alf = chr(random.randint(65, 90)) s = str(random.choice([num, alf])) ret += s return ret print(v_code())
OS模块
import os # print(os.getcwd()) 获取当前目录 # os.chdir("") 改变当前脚本的工作目录,类似于cd #os.makedirs('one/oe') #递归生成目录 #os.removedirs('one/oe') 删除空文件 #print(os.listdir()) # #查文件信息 # #st_size 大小 st_atime 上一次访问时间 st_mtime 上一次修改时间 st_ctime 创建时间 # print(os.stat('time的使用.py')) # # #输出系统指定特定的路径分隔符 win'\' liunx'/' # os.sep() # # #输出当前平台的行终止符 win' ' liunx '/n' # os.linesep() # # #输出用于分割文件路径分隔符 win';' liunx':' # os.pathsep() # # # print(os.system('dir')) # #返回path的目录 # os.path.dirname() # # #返回path最后的文件名 # os.path.basename() # # #如果path存在True 不存在未False # os.path.exists() # #拼接路径 # os.path.join() #获取文件最后的修改时间 #print(os.path.getmtime('time的使用.py'))
sys模块
import sys,time #退出程序 # sys.exit('程序名') # # 显示当前操作平台 # sys.platform() for i in range(20): #简易进度条 sys.stdout.write('#') time.sleep(0.5) sys.stdout.flush()
json&pcikle模块
首先我们得了解序列化,所谓序列化就是把对象(变量)从内存中变成可存储或传输的过程。在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等。
那么为什么要进行数据化呢?
1.软件/程序的执行就是处理一系列状态的变化,状态会以各种各样的数据类型保存在内存中,我们都知道内存中的内容断电就会消失。如果我们在断电之前将这些状态都保存下来,那么我们下次在运行的时候我们得程序就只能直接在加载上次的内容,继续执行,这个叫做序列化。
2.序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
import json # dic = {"name": "Liu"} # data = json.dumps(dic) #字符串一定要双引 json将Python中的数据类型变成双引号的字符 # print(data) # print(type(data)) # dic_str = json.dumps(dic) # f = open('new_hello', 'w') # f.write(dic_str) ---->josn.dump(dic,f) # f_read = open('new_hello', 'r') # data = json.loads(f_read.read()) ---->data = json.load(f) # print(data) # print(type(data)) # import json # with open("Json_test", "r") as f: # data = f.read() # data = json.loads(data) # print(data["name"])
import pickle #转换为字节 # dic = {'name': 'alvin', 'age': 23, 'sex':'male'} # print(type(dic)) # # j = pickle.dumps(dic) # print(type(j)) # f = open('序列化对象——pickle', 'wb') # f.write(j) #--->pickle.dump(dic,f) f = open('序列化对象——pickle', 'rb') data = pickle.loads(f.read()) #--->data = pickle.load(f) print(data["age"])
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回的时类似字典的对象,可读可写,key必须为字符串
import shelve # f = shelve.open(r'shelve1.txt') #讲字典放入文本 # # f['stu1_info'] = {'name': 'alex', 'age': '18'} # f['stu2_info'] = {'name': 'king', 'age': '28'} # # f.close() f = shelve.open(r'shelve1.txt') print(f.get('stu1_info')['age'])
xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单。
import xml.etree.ElementTree as ET #ET在这里代替了xml.etree.ElementTree tree = ET.parse("xml_lesson") root = tree.getroot() print(root.tag) # 遍历xml文档 # for i in root: # # print(i.tag, i.attrib) # for j in i: # print(j.tag, j.attrib, j.text) # 只遍历year节点 # for node in root.iter('year'): # print(node.tag, node.text) # 修改xml文档 # for node in root.iter('year'): # new_year = int(node.text) + 1 # node.text = str(new_year) # node.set("updated", "yes") # tree.write("xml_lesson") # 删除node # for country in root.findall("country"): # rank = int(country.find('rank').text) # if rank >50: # root.remove(country) # tree.write("output.xml") new_xml = ET.Element("namelist") name = ET.SubElement(new_xml, "name", attrib={"enrolled": "yes"}) age = ET.SubElement(name, "age", attrib={"checked": "no"}) sex = ET.SubElement(name, "sex") sex.text = '33' et = ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml", encoding="utf-8", xml_declaration=True)
<data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year updated="yes">2011</year> <gdppc>141100</gdppc> <neighbor direction="E" name="Austria" /> <neighbor direction="W" name="Switzerland" /> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year updated="yes">2014</year> <gdppc>59900</gdppc> <neighbor direction="N" name="Malaysia" /> </country> <country name="Panama"> <rank updated="yes">69</rank> <year updated="yes">2014</year> <gdppc>13600</gdppc> <neighbor direction="W" name="Costa Rica" /> <neighbor direction="E" name="Colombia" /> </country> </data>
hashlib模块
hash是一种算法(3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法),该算法接受传入的内容,经过运算得到一串hash值 hash值的特点是: 1.只要传入的内容一样,得到的hash值必然一样=====>要用明文传输密码文件完整性校验 2.不能由hash值返解成内容=======》把密码做成hash值,不应该在网络传输明文密码 3.只要使用的hash算法不变,无论校验的内容有多大,得到的hash值长度是固定的
import hashlib obj=hashlib.md5() obj.update("admin".encode("utf8")) print(obj.hexdigest()) #21232f297a57a5a743894a0e4a801fc3 obj.update("adminroot".encode("utf8")) print(obj.hexdigest())# 4b3626865dc6d5cfe1c60b855e68634a # 4b3626865dc6d5cfe1c60b855e68634a