Spark专题的第二篇,本来想写Spark的Shuffle是如何实现的,查了一些资料,还是不太明白的。所以,从定义和缘由开始缕一缕:
- 什么是大数据处理的Shuffle?
- 为什么大数据集群处理需要进行Shuffle?
- Hadoop和Spark的Shuffle分别是如何实现的?
- 相对与Hadoop的Shuffle,Spark的Shuffle有什么优点?
第一个问题,什么是大数据处理的Shuffle?无论是Hadoop还是Spark,都要实现Shuffle。Shuffle描述数据从map tasks的输出到reduce tasks输入的这段过程。
第二个问题,为什么需要进行Shuffle呢?map tasks的output向着reduce tasks的输入input映射的时候,并非节点一一对应的,在节点A上做map任务的输出结果,可能要分散跑到reduce节点A、B、C、D ,就好像shuffle的字面意思“洗牌”一样,这些map的输出数据要打散然后根据新的路由算法(比如对key进行某种hash算法),发送到不同的reduce节点上去。【摘自:Spark性能优化——和shuffle搏斗】
第三个问题,Hadoop是如何实现Shuffle的?主要参考了《hadoop中shuffle过程详解》和《MapReduce之Shuffle过程详述》两篇文章,在map端,一个task经历了:输入(input)过程、切分(partition)过程、溢写spill过程、merge过程;其中spill和merge都要排序,而combiner【备注:combiner相当于map端的reduce】是可选的。在reduce端,当有一个map task完成后,yarn会告知reducer拉取(fetch)任务,在所有的map任务完成之前,reducer都是在重复的拉取(copy)数据、merge这两个步骤。需要注意的是,这两个步骤是来源与不同的map task结果生成的文件,并且,reducer只merge属于自己分区的文件。
那么,Spark是如何实现的Shuffle的呢?看张图【图片来自:https://www.slideshare.net/SparkSummit/accelerating-shuffle-a-tailormade-rdma-solution-for-apache-spark-with-yuval-degani】:
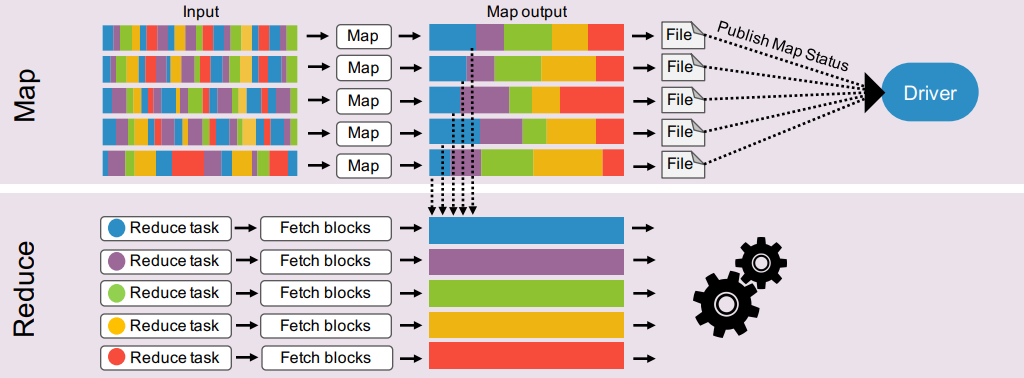
图1
Spark的map阶段完成之后直接输出文件到磁盘,reduce从多个file读取map的结果,然后汇总计算。【参考阅读:Shuffle过程】
第四个问题,关于Spark的Shuffle优点,通过知乎的一张图做个对比:
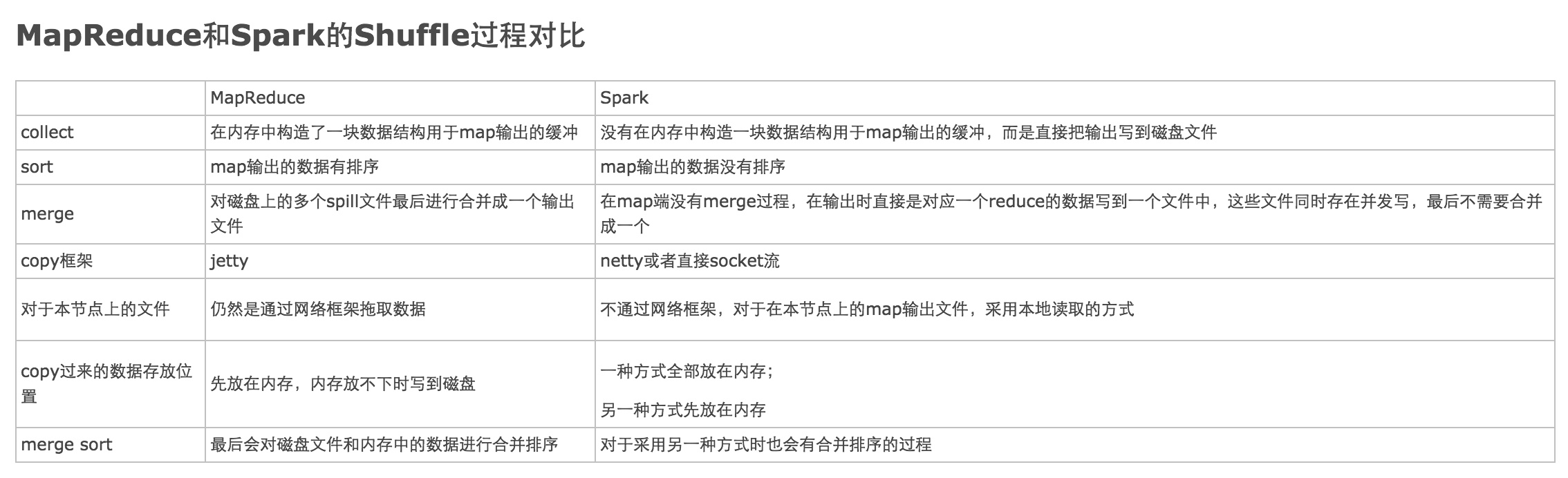
图2
关于Spark的merge解释,根据图1的上半部分展示,我理解为,每个task map对应一个输出文件file,这些输出文件的内容是经过partition分区的,一个reduce对应一个partition分区,reduce数据来源于所有输出文件具有相同partion的数据。