hadoop的安装分为三种方式,第一种单机安装,一般用于调试(其实一般都不用)。第二种,伪分布式安装,一般程序员开发会使用这种方式。第三种,分布式安装,在实际环境中应用。今天在这里记下的是第二种,即伪分布式安装。
相比于伪分布式安装,分布式安装的区别主要是复制因子dfs.replication以及slavers和masters文件的内容不一样。分布式安装中,slavers文件中保存的是DataNode节点的主机名,masters保存的是NameNode节点的主机名,一行一个。但都有一个前提条件,那就是能够SSH无密码连通集群中的机器,如果是伪分布式安装就是ssh本机。
第一步,选择要安装的hadoop版本的tar.gz的压缩文件,并解压到指定目录。


第二步、创建一个存放数据的文件夹,这个文件夹的名字可以自行命令,但是要包括三个子文件夹(这三个子文件夹,可以分开,不过一般我们将它们放到同一个文件夹中)

这三个文件夹中,其中data(datanode节点使用,保存数据内容)的权限为755,其他为777。
第三步、设置参数
设置hadoop-env.sh内容

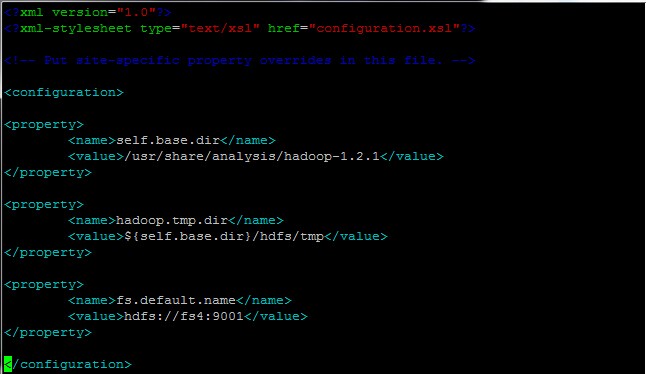
设置core-site.xml内容
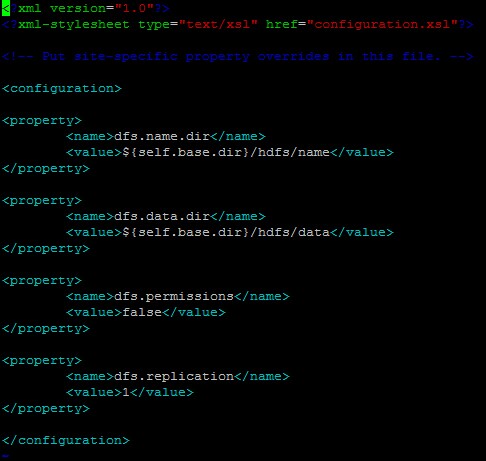
设置hdfs-site.xml文件内容
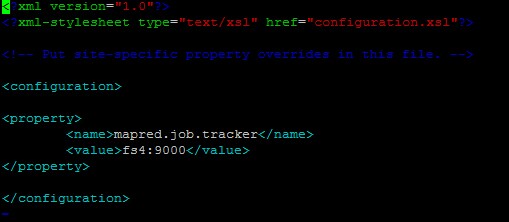
设置mapred-site.xml内容
设置masters文件内容

设置slaves文件内容
第四步、格式化hadoop namenode
执行./bin/hadoop namenode -format,执行过程中输入Y即可,看到success就表示成功。
第五步、启动hadoop集群
./bin/start-all.sh
启动后通过jps可以查看到,
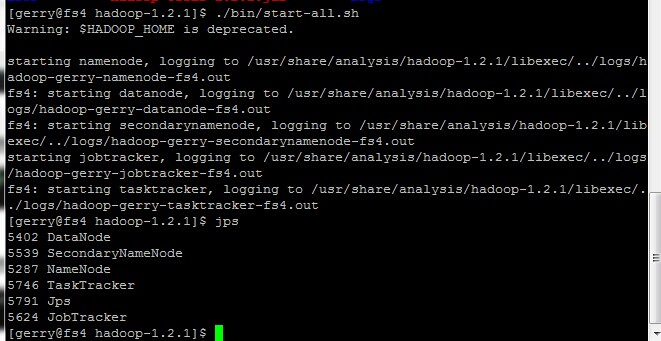
其中看到DataNode、SecondaryNameNode、NameNode、TaskTracker、JobTracker五个。
还可以通过web页面来查看启动情况:
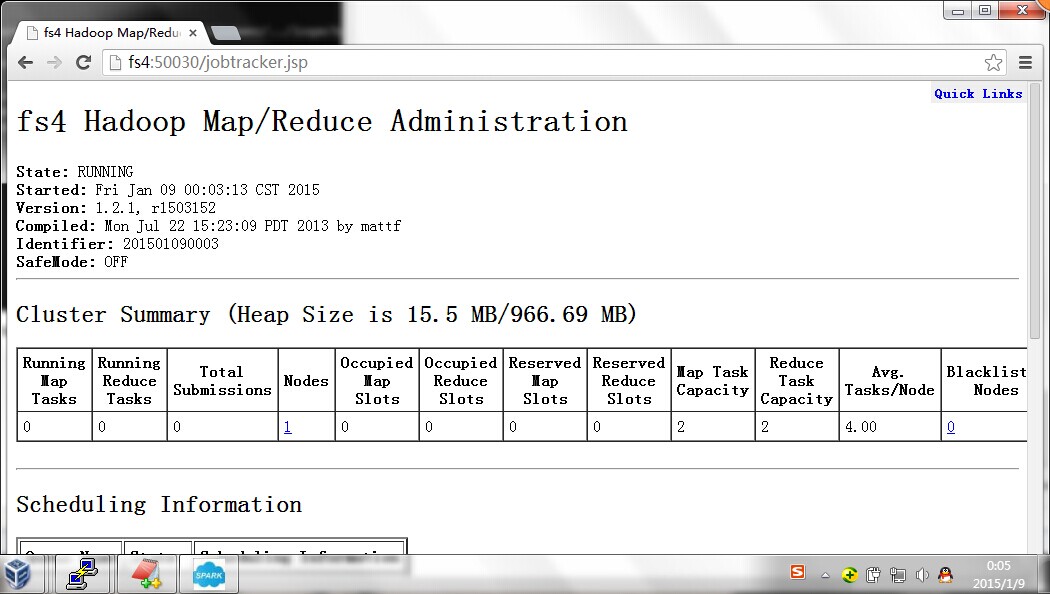
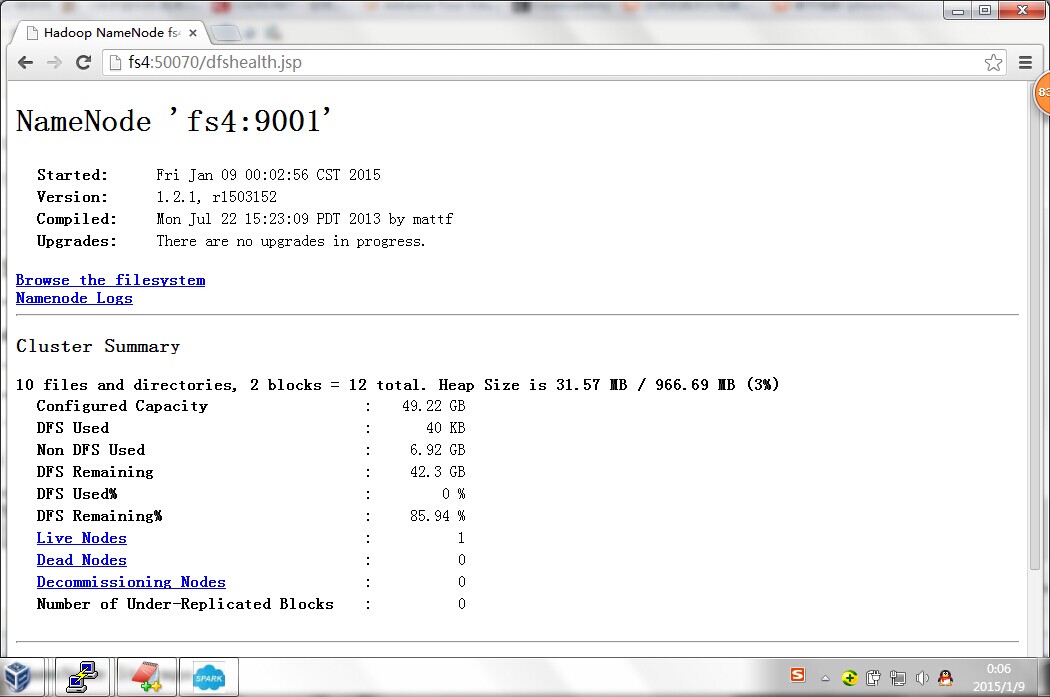
最后、关闭集群
stop-all.sh