You are given a string, s, and a list of words, words, that are all of the same length. Find all starting indices of substring(s) in s that is a concatenation of each word in words exactly once and without any intervening characters.
For example, given:
s: "barfoothefoobarman"
words: ["foo", "bar"]
You should return the indices: [0,9].
(order does not matter).
简单的翻译:给定一个字符串s和一个字列表words,所有的字是相同长度的。找出所有s的字串中包含有words中所有元素的下标,并且顺序无所谓。
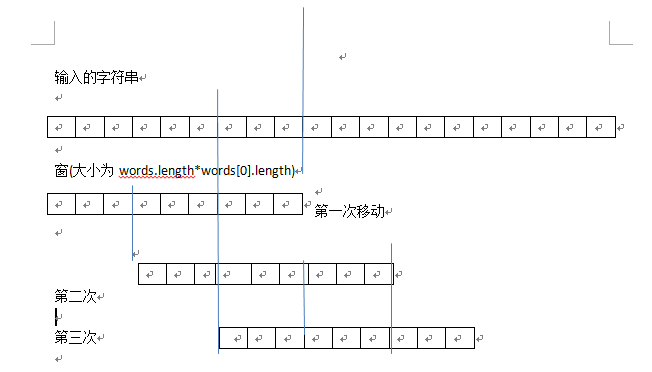
对于每一次的移动判断,判断窗体内的字符串是否是有给定的字符串数组中的元素组成,这个是用map或者其他的数据结构来判断的。因为是不用计较顺序的,所以有可以简化为判断存在与否的问题。判断存在与否则是通过累计判断的,即每次从输入串提取出wordsp[0].length长度的字串判断其是否存在于words中,并且数目一定要相同,即words中有一个“abaad”,则窗口对应的串中也只能有一个”abaad”。
使用一个map保存words中的数据用来对比,一个新的map用来保存窗对应的数据,这样通过比较两个map中的数据就可以判断是否匹配了。并且使用map结构可以减少取值的操作过程,当每次窗移动时,只需要从map中除去原窗口位置对应的第一个word即可,这样新的串口对应的数据只需要添加一个word即可,可以减少words.length-1次的提取数据的操作。(代码来自网上分享)


public class Solution { /* A time & space O(n) solution Run a moving window for wordLen times. Each time we keep a window of size windowLen (= wordLen * numWord), each step length is wordLen. So each scan takes O(sLen / wordLen), totally takes O(sLen / wordLen * wordLen) = O(sLen) time. One trick here is use count to record the number of exceeded occurrences of word in current window */ public static List<Integer> findSubstring(String s, String[] words) { List<Integer> res = new ArrayList<>(); if(words == null || words.length == 0 || s.length() == 0) return res; int wordLen = words[0].length(); int numWord = words.length; int windowLen = wordLen * numWord; int sLen = s.length(); HashMap<String, Integer> map = new HashMap<>(); for(String word : words) map.put(word, map.getOrDefault(word, 0) + 1); for(int i = 0; i < wordLen; i++) { // Run wordLen scans HashMap<String, Integer> curMap = new HashMap<>(); for(int j = i, count = 0, start = i; j + wordLen <= sLen; j += wordLen) { // Move window in step of wordLen // count: number of exceeded occurences in current window // start: start index of current window of size windowLen if(start + windowLen > sLen) break; String word = s.substring(j, j + wordLen); if(!map.containsKey(word)) { curMap.clear(); count = 0; start = j + wordLen; } else { if(j == start + windowLen) { // Remove previous word of current window String preWord = s.substring(start, start + wordLen); start += wordLen; int val = curMap.get(preWord); if(val == 1) curMap.remove(preWord); else curMap.put(preWord, val - 1); if(val - 1 >= map.get(preWord)) count--; // Reduce count of exceeded word } // Add new word curMap.put(word, curMap.getOrDefault(word, 0) + 1); if(curMap.get(word) > map.get(word)) count++; // More than expected, increase count // Check if current window valid if(count == 0 && start + windowLen == j + wordLen) { res.add(start); } } } } return res; } }
关于外层循环的存在,从我们的绘图可以看到窗的出发点是0,但是有可能从1开始的窗对应的才是我们想要的,所以要加入外层循环遍历所有的可能,之所以到words[0].length就结束是因为,当窗的开始为值为words[0].length的时候,可以发现它是第一次移动窗的结果,也就是重复了,所以就不用继续执行了。想象一下即可。