正常我们大家使用缓存都是这个原理,即:
- 如果我们的数据在缓存里边有,那么就直接取缓存的。
- 如果缓存里没有我们想要的数据,我们会先去查询数据库,然后 将数据库查出来的数据写到缓存中。
- 最后将数据返回给请求。
如果仅仅查询的话,缓存的数据和数据库的数据是没问题的。但是,当我们要 更新 时候呢?各种情况很可能就 造成数据库 和 缓存的数据不一致了。
从理论上说,只要我们设置了 键的过期时间,我们就能保证缓存 和 数据库的数据 最终是一致 的。因为只要缓存数据过期了,就会被删除。随后读的时候,因为缓存里没有,就可以查数据库的数据,然后将数据库查出来的数据写入到缓存中。
除了设置过期时间,我们还需要做更多的措施来 尽量避免 数据库 与 缓存处于不一致的情况发生。
1、更新操作
一般来说,执行更新操作时,我们会有两种选择:
- 先操作数据库,再操作缓存
- 先操作缓存,再操作数据库
首先,要明确的是,无论我们选择哪个,我们都希望这 两个操作要么同时成功,要么同时失败。所以,这会演变成一个 分布式事务 的问题。
所有,如果原子性被破坏,可能会有以下的情况:
-
- 操作数据库成功了,操作缓存失败
- 操作缓存成功了,操作数据库失败
1.1、操作缓存
操作缓存也有两种方案:
1、更新缓存
2、删除缓存
一般我们都是采取 删除缓存 策略的,原因如下:
1、高并发环境下,无论是先操作数据库还是后操作数据库而言,如果加上更新缓存,那就 更加容易 导致数据库与缓存数据不一致问题。(删除缓存直接且简单很多)
2、如果每次更新了数据库,都要更新缓存【这里指的是频繁更新的场景,这会耗费一定的性能】,倒不如直接删除掉。等再次读取时,缓存里没有,那我到数据库找,在数据库找到再写到缓存里边(体现懒加载)
基于这两点,对于缓存在更新时而言,都是建议执行删除操作!
1.2、先更新数据库,再删除缓存
正常的情况是这样的:
1. 先操作数据库,成功;
2. 再删除缓存,也成功;
如果原子性被破坏了:
1. 第一步成功(操作数据库),第二步失败(删除缓存),会导致 数据库里是新数据,而缓存里是旧数据。
2. 如果第一步(操作数据库)就失败了,我们可以直接返回错误(Exception),不会出现数据不一致。
如果在高并发的场景下,出现数据库与缓存数据不一致的 概率特别低,也不是没有:
1. 缓存 刚好 失效
2. 线程A查询数据库,得一个旧值
3. 线程B将新值写入数据库
4. 线程B删除缓存
5. 线程A将查到的旧值写入缓存
要达成上述情况,还是说一句 概率特别低:
因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
删除缓存失败的解决思路:
1. 将需要删除的key发送到消息队列中
2. 自己消费消息,获得需要删除的key
3. 不断重试删除操作,直到成功
1.3、先删除缓存,再更新数据库
正常情况是这样的:
1. 先删除缓存,成功;
2. 再更新数据库,也成功;
如果原子性被破坏了:
1. 第一步成功(删除缓存),第二步失败(更新数据库),数据库和缓存的数据还是一致的。
2. 如果第一步(删除缓存)就失败了,我们可以直接返回错误(Exception),数据库和缓存的数据还是一致的。
看起来是很美好,但是我们在并发场景下分析一下,就知道还是有问题的了:
1. 线程A删除了缓存
2. 线程B查询,发现缓存已不存在
3. 线程B去数据库查询得到旧值
4. 线程B将旧值写入缓存
5. 线程A将新值写入数据库
所以也会导致数据库和缓存不一致的问题。
并发下解决数据库与缓存不一致的思路:
将删除缓存、修改数据库、读取缓存等的操作积压到 队列 里边,实现 串行化。
2、总结解决方案
方案一:
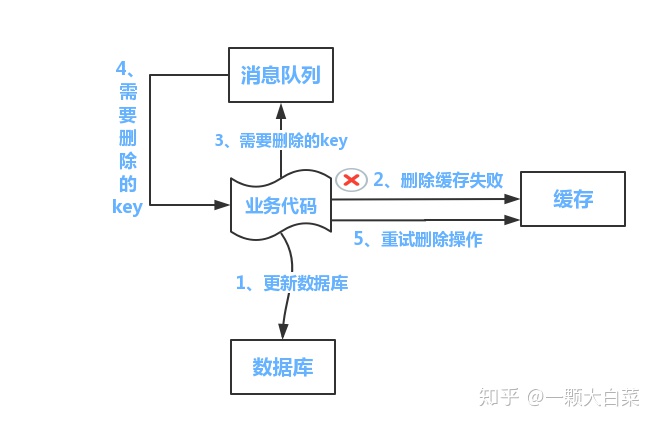
流程如下所示:
(1)更新数据库数据;
(2)缓存因为种种问题删除失败
(3)将需要删除的key发送至消息队列
(4)自己消费消息,获得需要删除的key
(5)继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案二:
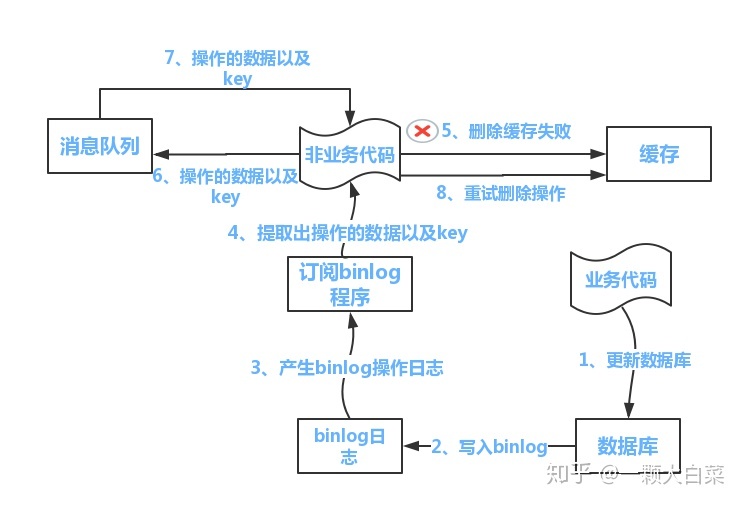
流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
备注说明:
上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。另外,重试机制,采用的是消息队列的方式。如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试即可,这些大家可以灵活自由发挥,只是提供一个思路。
3、总结
本文其实是对目前互联网中已有的一致性方案,进行了一个总结。
对于先删缓存,再更新数据库的更新策略,还有方案提出维护一个内存队列的方式,看了一下,觉得实现异常复杂,没有必要,因此没有必要在文中给出。
4、面试体验
面试官:你在实际项目中使用缓存有遇到什么问题或者会遇到什么问题你知道吗?
我:缓存和数据库数据一致性问题:分布式环境下非常容易出现缓存和数据库间数据一致性问题,针对这一点,如果项目对缓存的要求是强一致性的,那么就不要使用缓存。我们只能采取合适的策略来降低缓存和数据库间数据不一致的概率,而无法保证两者间的强一致性。合适的策略包括合适的缓存更新策略,更新数据库后及时更新缓存、缓存失败时增加重试机制。具体方案策略可以参考上面第二种方案。