一、个人编程作业链接:
github(点击可查看完整代码)
二、计算模块接口的设计与实现过程
1.基本思路流程图

2.空间向量模型+余弦算法解决论文查重问题
句子A:我喜欢看动漫,不喜欢综艺
句子B:我不喜欢走路,不喜欢骑车
-
tokenization:对文本集中的文本进行分词并去掉停用词,这部分我采用的是结巴分词,之前使用过gsep.cup(),虽然比结巴分词分得好,但其时间代价也高

word_set:{我,喜欢,看,动漫,综艺,不,走路,汽车}
-
dict:基于文本集建立词典。这部分的功能是为word_set中的每一个单词附上一个特征数

word_dict:{'我’:0,‘喜欢’:1,‘看’:2,‘动漫’:3,‘综艺’:4,‘不’:5,‘走路’:6,‘汽车’:7}
-
生成词频并根据词频生成位置向量。
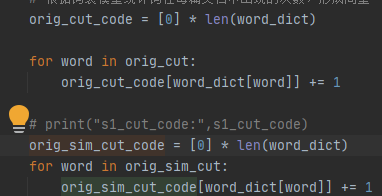
A:{1,2,1,1,1,1,0,0}
B:{1,2,0,0,0,2,1,1}
-
用余弦相似算法求解文本相似度
1)什么是余弦相似算法呢?

2)代码如下:

-
main函数执行结果

三、命令行参数(sys argv[1]、argv[2]、argv[3]...)
执行语句:python main.py [原文文件名][抄袭文件名][答案文件名]

四、性能分析以及性能改进
- 起初分词采用简单的结巴分词,每篇抄袭文档的重复率都在0.99以上,所以仅有结巴分词是不行的,还必须加入停用词表(仅采用结巴分词,结果会大量存在标点符号)
- 停用词表的使用也很有讲究,一个好的停用词表可以使两篇论文的相似度降低
- 性能分析我采用了pycharm自带的profile性能分析器,得到如下图
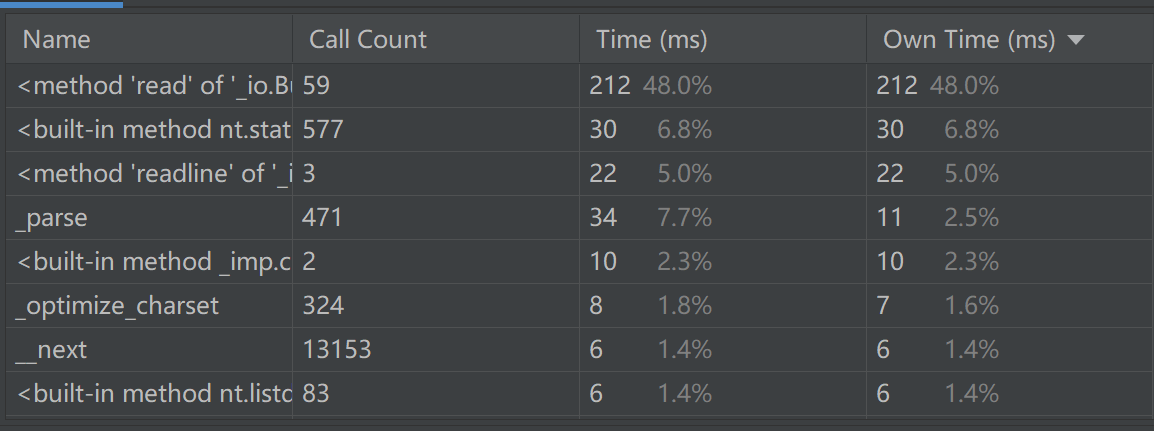
- 程序中消耗最大的函数

五、单元检测
单元测试部分我采用的是python自带的unittest
-
构造测试数据的思路
将每一份测试数据连同异常检测都封装成一个进程,在unittest中逐一对这些进程进行检测
(为了缩减代码,将单元测试所用到的函数封装在一个新的文件test_function中) -
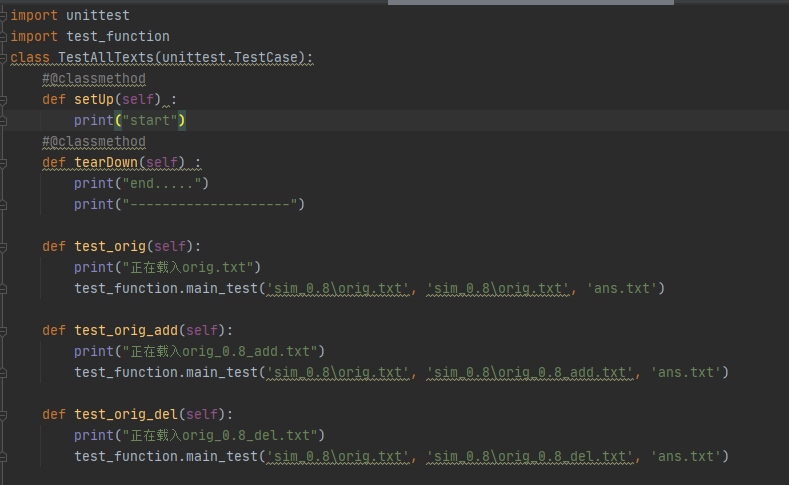
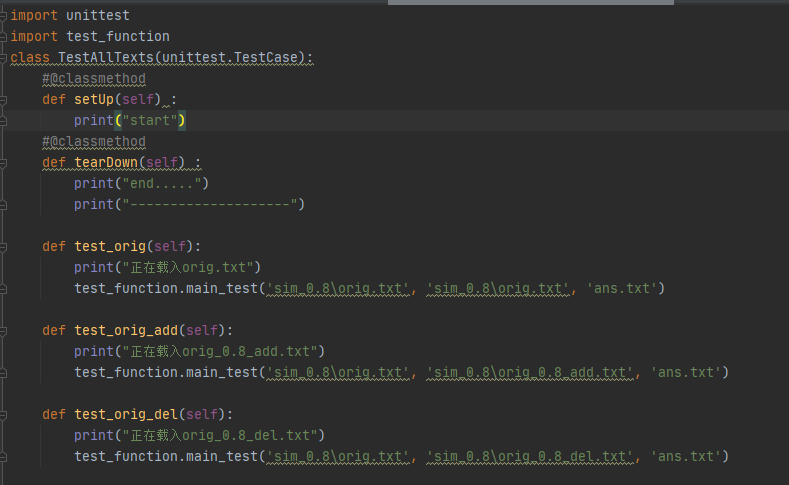
部分测试代码

-
构造测试数据的思路:
此次测试采用12组数据,前10份课来自课程提供的测试样例sim_0.8,其中一份是原文数据,其它九份是抄袭文的数据。第11组数据是自己网上copy下来的两篇文章的相似度,最后一组数据是对异常检测的测试,因此结果会抛出一个异常

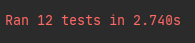
-
单元测试重复率:
使用coverage,只需在cmd中安装coverage,并输入coverage run 文件名,输出结果如下:

六、异常处理
先定义一个错误异常类,当出现这类错误时就会跳转执行这个类
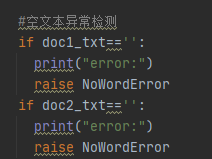
在unittest中检测这个类

异常对应的场景

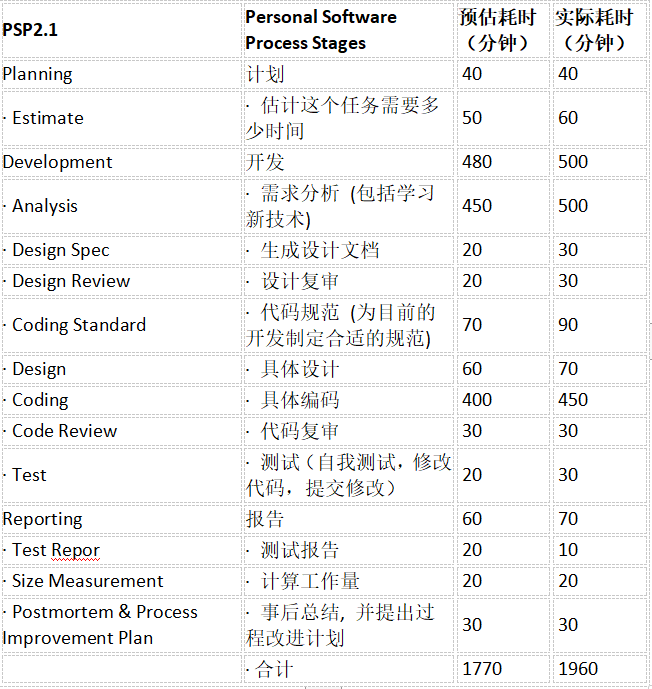
七、PSP表格
八、总结
这次软工作业虽然花了很多时间,但是真的学到了很多的东西-----新学了python,学会了如何对代码进行性能分析,异常处理.....感触如下:
其一,重要的不是结果,而是努力的过程。实践的结果只能带来短暂的成就感,这期间从博客、书籍上捕获的知识才是受用终生的。
其二,要善于批评与自我批评,代码是在不断修证的过程中实现性能优化的。
其三,要善于学习别人的代码,在学习的过程中进行独立思考,真正做到内化所学新知识。