python爬虫和node爬虫的原理是一样的,就是先请求,再换字符串,接着匹配,最后存入数据库备用
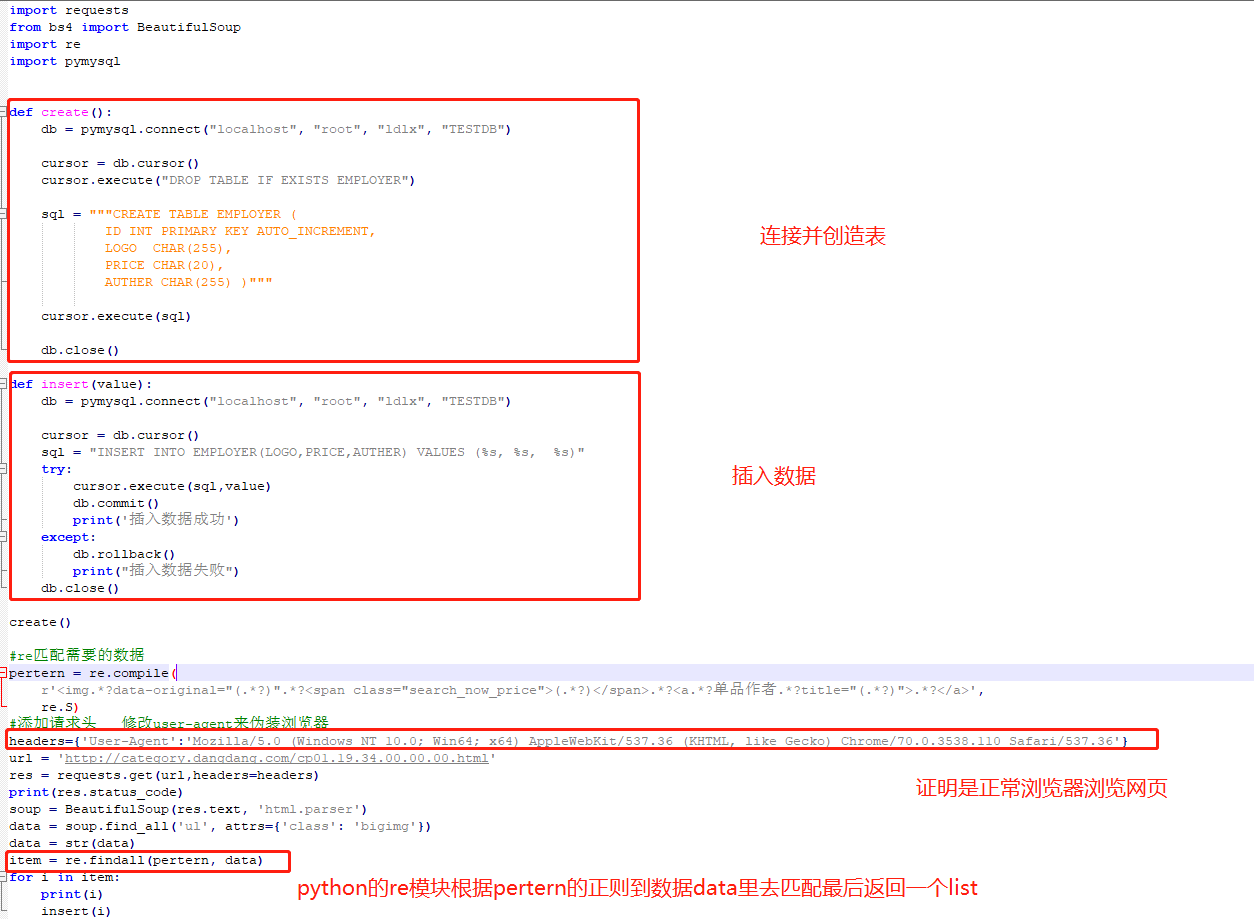
下面是爬虫一个当当网的


#!/usr/bin/python # -*- coding: UTF-8 -*- import requests from bs4 import BeautifulSoup import re import pymysql def create(): db = pymysql.connect("localhost", "root", "ldlx", "TESTDB") cursor = db.cursor() cursor.execute("DROP TABLE IF EXISTS EMPLOYER") sql = """CREATE TABLE EMPLOYER ( ID INT PRIMARY KEY AUTO_INCREMENT, LOGO CHAR(255), PRICE CHAR(20), AUTHER CHAR(255) )""" cursor.execute(sql) db.close() def insert(value): db = pymysql.connect("localhost", "root", "ldlx", "TESTDB") cursor = db.cursor() sql = "INSERT INTO EMPLOYER(LOGO,PRICE,AUTHER) VALUES (%s, %s, %s)" try: cursor.execute(sql,value) db.commit() print('插入数据成功') except: db.rollback() print("插入数据失败") db.close() create() #re匹配需要的数据 pertern = re.compile( r'<img.*?data-original="(.*?)".*?<span class="search_now_price">(.*?)</span>.*?<a.*?单品作者.*?title="(.*?)">.*?</a>', re.S) #添加请求头 修改user-agent来伪装浏览器 headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36'} url = 'http://category.dangdang.com/cp01.19.34.00.00.00.html' res = requests.get(url,headers=headers) print(res.status_code) soup = BeautifulSoup(res.text, 'html.parser') data = soup.find_all('ul', attrs={'class': 'bigimg'}) data = str(data) item = re.findall(pertern, data) for i in item: print(i) insert(i)
执行结果如下:

注:如果报错什么引入的module找不到就直接去python安装目录下的script文件夹下打开cmd,然后通过pip install 模块名下载即可