传统运维和自动化运维的对比
1.企业中,项目的发布流程
产品经理调研需求 —-》三方开会讨论(开发,产品,运维,测试) —–> 开发进行开发产品
—-> 测试流程 (黑盒和白盒测试) —–> 上线
传统的上线流程:
SVN 开发将代码压缩一下发给运维,运维拿到代码之后,然后将代码解压缩,部署到服务
器上,启动服务好处:流程比较简单
坏处: 服务器多的话,部署就非常的慢,影响上线的进度
自动化运维的流程
搞一个 web 的系统,勾选发布的机器,上传代码, 进行发布
2.监控系统
需要监控服务器的 CPU 使用率,磁盘大小(>90%,报警),内存使用率
CMDB
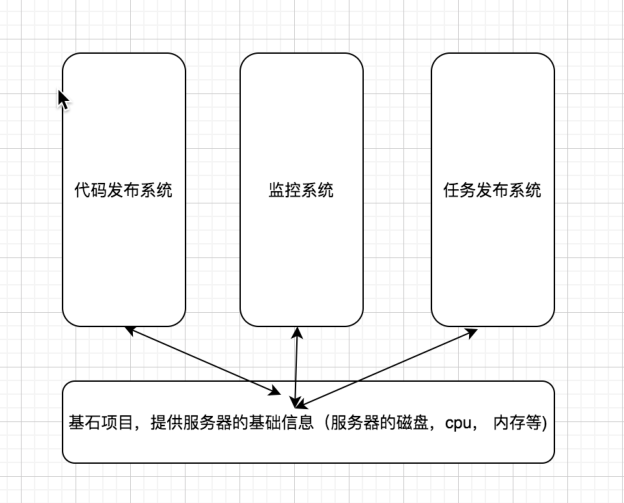
通过上面的例子,需要做一个基石项目,提供服务器的基础信息(服务器的磁盘,cpu,
内存等),这个基石项目叫做 CMDB Configure Manage DataBase 中文叫 配置管理数
据库,主要用来收集服务器的基础信息
架构图介绍
CMDB 的几种实现方式
Agent 实现方式
Agent 方式,可以将服务器上面的 Agent 程序作定时任务,定时将资产信息提交到指定 API 录入数据库
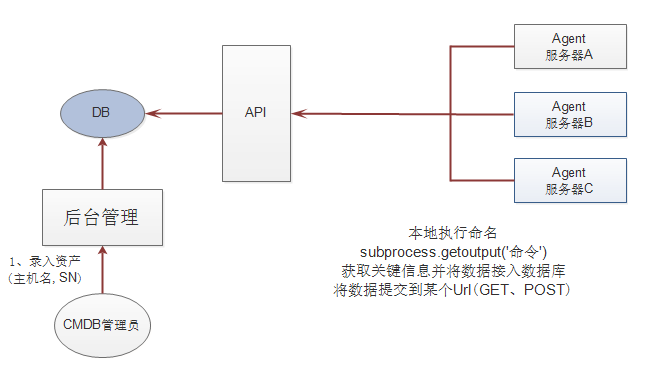
将待采集的服务器看成一个agent,然后再服务器上使用python的subprocess模块执行linux相关的命令,然后分析得到的结果,将分析得到的结果通过requests模块发送给API,API获取到数据之后,进行二次比对数据,最后将比对的结果存入到数据库中,最后django起一个webserver从数据库中将数据获取出来,供用户查看
优点:速度快
缺点:需要为每台服务器部署一个Agent程序
ssh 实现方式(基于 Paramiko)
在中控机服务器上安装一个模块叫paramiko模块,通过这个模块登录到带采集的服务器上,然后执行相关的linux命令,最后返回执行的结果,将分析得到的结果通过requests模块发送给API,API获取到数据之后,进行二次比对数据,最后将比对的结果存入到数据库中,最后django起一个webserver从数据库中将数据获取出来,供用户查看
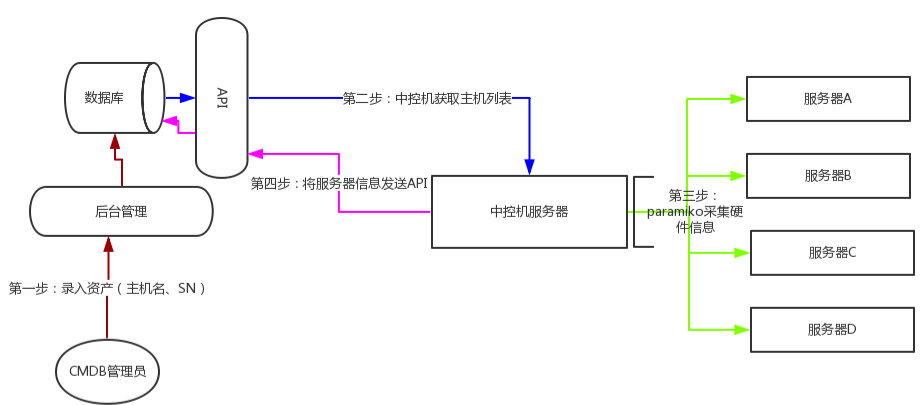
优点:不用 每一台都部署 Agent
缺点:速度慢
如果在服务器较少的情况下,可应用此方法
import paramiko # 创建SSH对象 ssh = paramiko.SSHClient() # 允许连接不在know_hosts文件中的主机 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) # 连接服务器 ssh.connect(hostname='c1.salt.com', port=22, username='root', password='123') # 执行命令 stdin, stdout, stderr = ssh.exec_command('df') # 获取命令结果 result = stdout.read() # 关闭连接 ssh.close()
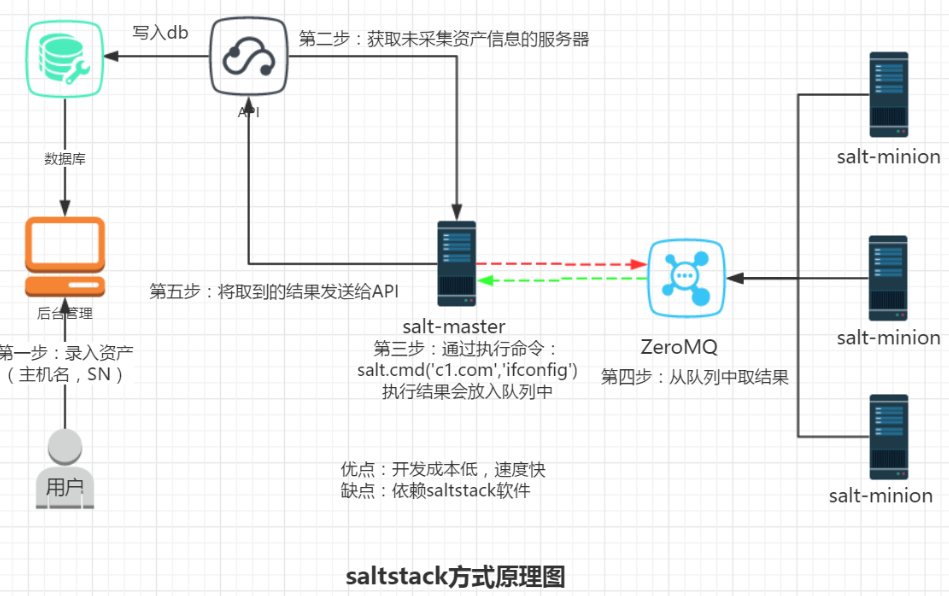
saltstack 方式
问:如何使用 Python 代码来执行 linux 的命令?
答:subproces s模块来执行 linux 命令
问:为啥post中没有收到数据,而body中有
答:django 根据你 http 协议的头信息来判断,
如果是 content-type: application/form-url-encode的话,django 会将 body 中的数据付
给 post。如果 content-type: application/json 的话,django 不会将 body 中的数据付给 post
总结:整个架构方案分 3 个部分:客户端采集,API 数据分析,数据展示