Hibernate 是一个数据层的框架 所谓框架就是提高写代码的效率
他也是ORM(对象关系映射的实现 )
里面提供了一些方言(不同数据库设置不同的方言)---跨数据库
还提供了缓存来提高查询效率
主要我们看一下配置文件(框架基本上都是用配置文件来搭建环境的)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 连接数据库的四个参数 -->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/hibernate</property>
<property name="connection.username">root</property>
<property name="connection.password">root</property>
<!-- 连接池 -->
<property name="connection.pool_size">30</property>
<!-- 方言 -->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 线程和session同步-->
<property name="current_session_context_class">thread</property>
<!--展示SQL语句 -->
<property name="show_sql">true</property>
<!-- 格式化Sql -->
<property name="format_sql">true</property>
<!-- 如果有表就使用 没表就创建 -->
<property name="hbm2ddl.auto">update</property>
<!-- 映射文件 -->
<mapping resource="com/zgl/entity/User.hbm.xml" />
</session-factory>
</hibernate-configuration>
从上面可以看这边的配置文件主要配置的是怎么连接数据库然后就是Hibernate的核心配置 ---是否线程同步 是否展示SQL语句等等
还有一个重要的就好似映射文件 这里面的映射文件极其重要 他反映了表和实体类的关系
先看单表的属性配置文件
<!-- 这个文件叫做映射文件 -->
<!--
package:实体类的额包名
-->
<hibernate-mapping package="com.qf.entity">
<class name="User" table="t_user">
<!-- id比较特殊,用id标签修饰 -->
<id name="id">
<!-- 主键自增策略 -->
<generator class="native" />
</id>
<!--
其他属性用property修饰
name:指定的是对象的中的属性名称
column:表中字段名称
-->
<property name="username" column="name"></property>
<!--
表中的字段名称和实体类中的属性名称一致,column可以不写
-->
<property name="password"></property>
</class>
</hibernate-mapping>
这个配置文件主要配置实体类和表中字段的对应关系如果表中字段和实体类属性一致的话可以只写实体类的属性即可
然后单表的增删改查
先创建Session的工厂的工具类
private static final SessionFactory sessionFactory = buildSessionFactory();
private static SessionFactory buildSessionFactory() {
try {
// 1.配置相关对象
Configuration configuration = new Configuration();
// 2.读取配置文件
Configuration configure = configuration.configure();
// 3.构建工厂
SessionFactory factory = configure.buildSessionFactory();
return factory;
} catch (Throwable ex) {
// Make sure you log the exception, as it might be swallowed
System.err.println("Initial SessionFactory creation failed." + ex);
throw new ExceptionInInitializerError(ex);
}
}
public static SessionFactory getSessionFactory() {
return sessionFactory;
}
}
然后在测试类调用这个方法这个类中的方法就可以获得Session工厂了
记得操作数据库之前要开启事务session.beginTransaction(); 然后结束后要提交事务transaction.commit();
@Test
public void testHello() {
// 1.创建一个SessionFactory
SessionFactory sessionFactory = HibernateUtil.getSessionFactory();
// 2.通过SessionFactory创建session
Session session = sessionFactory.getCurrentSession();
// 3.开启事务
Transaction transaction = session.beginTransaction();
User user = new User();
user.setUsername("admin");
user.setPassword("admin");
// 4.保存user
Serializable save = session.save(user);
System.out.println("save方法的返回值:"+save);
// 5.事务提交
transaction.commit();
其中 具体的调用方法
添加:session.save(user);--传入对象
删除:session.delete(user);---传入对象
查找:session.get(User.class, userId);-传入对象类型 和查找的条件
更新:先查找然后修改--session.get(User.class, 2);---session.update(user);
---------------------------------------------------------------其中这个Session 的创建有两种方式
方式一:openSession
sessionFactory.openSession();---需要关闭Session
1.每次都会创建一个新的Session
2.session需要手动关闭
3.可以在没有事务的情况下操作事务--查询
4.提交事务的时候 会刷新缓冲区 提交事务
方式二 :getCurrentSession
sessionFactory.getCurrentSession();
1.每次创建Session 的时候会先在缓存区找如果有就直接使用没有的话就创建
2.必须要开启事务才可以操作数据库
3.提交事务的时候 会自动 关闭Session 刷新缓冲区 提交事务
----------------------------------------------------load 和 get查询的区别
load:
session.load(User.class, 1);
查询结果返回的是一个代理对象 这个对象只有ID有值 其他属性都为空 只有 调用 除ID以外的属性时 才会 发送 sql语句
懒加载 可以 更改 修改配置文件 的 Class节点 中的 lazy属性
如果查询的数据 会抛出异常
get:
session.get(User.class, 1);
查询结果返回的是一个真实 的 对象
很积极查询后立马发送那个SQL语句
查询一个 不存在的值 返回 NULL
-------------------------------------------------------------------------------------------------------------------------------------------------------
两张表的连接 一对多 :
此时就需要 配置他们的对应关系了
一 的一方 :
首先要在实体类的里面添加多的一方实体类用集合接收 然后配置 XML
这里用set集合接收
name一的一方中多的一方的属性名
关联外键 一的一方在多的一方表中的字段名
配置关系 多的一方的实体类的全类名
<set name="addresss" inverse="true">
<!-- 关联的外键 -->
<key column="user_id"></key>
<!-- 多的一方的全类名 -->
<one-to-many class="com.qf.entity.Address"/>
</set>
多的一方 --
同样也要在实体类的里面 添加 一 的一方的属性
然后配置
多的一方 只需要配置与多的一方的关系
然后 关联外间一的一方在多的一方的字段名
<many-to-one name="user">
<!-- 关联外键 -->
<column name="user_id"></column>
</many-to-one>
这样简单的一对多的关系就配置好了
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------
两张表的级联操作 :改变一张表另一张表也随之改变
cascade--级联操作 (添加在一的一方的set标签中 )
save-update:保存多的一方多的一方自动保存
delete : 删除一的一方多的一方自动删除
all:包含上面两种 方式
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
inverse 控制反转--设置为true把维护权给另一方
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1.多对多
a)配置
1)A方
a)<set>
1)name:另一方集合名称
2)table:中间表名称
3)<key>:当前表在中间表的关联字段
b)<many-to-many>
a)class:另一方的类型
b)column:另一方在中间表的关联字段

2)B方和A方相反
b)级联操作
1)需要保存哪一方中间表维护权就给哪一方,所以另一方需要反转
------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1.抓取策略 抓取数据的一种策略
它是改变hibernate查询的方式从而提高查询效率
检索方式
立即检索 ---get
延时检索---load
检索级别 :
类级别的检索
查询的时候当前对象中的其他属性是否需要查询
关联级别
查询的时候当前对象中的其他对象是否需要查询
fetch:决定的SQL语句
select:普通的查询
join:连接查询
subselect:子查询
lazy:决定的懒载程度
true:懒惰
false:不懒惰
extra:极其懒惰

------------------------------------------------------------------------------------------------------------------------------------------------------------------
HQL查询 :
纯面向对象的查询
里面的关键字不区分大小写
操作的都是对象或者属性不是表中的字段
1.查询List集合数据
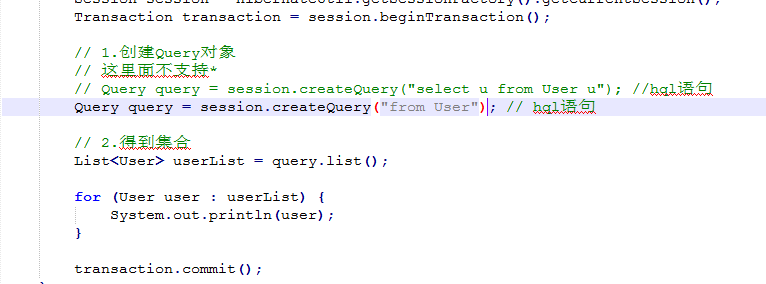
利用Session的createQuery() 方法编写 sql语句 ----面向对象 操作
然后得到Query对象 然后 用List() 方法接受List集合数据 最后遍历集合
查询单个数据

和上面一样只不过得到Query对象后用 uniqueResult接收单个对象 或数据
演示分页:
先写Sql语句在缓冲区 然后设置他的大小 然后执行

绑定参数 :--传入参数更灵活

看其中的?和 :id是占位符 这边赋值的话
知道类型就用类型不知道的话就用SetParmeter()----相当于Object

------------------------------------------------------------------------------------------------------------------------
QBC语句查询:hql更加的面向对象
查询集合 ;
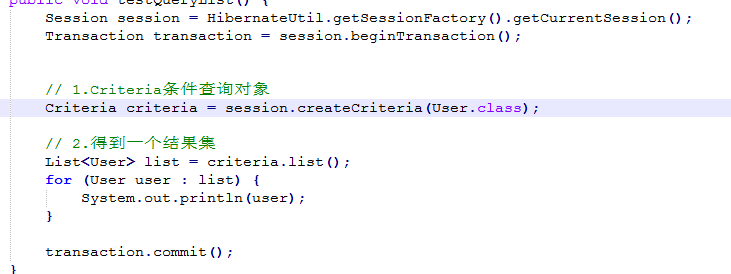
分页查询:

离线查询:

条件查询:


排序:

-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
缓存机制
一级缓存 :session级别的缓存
在同一个Session中查询语句的时候 先去缓存中去找 如果有就使用 没有的话就去数据库查询然后在缓存中放一份
不同的Session之间的缓存不共享
二级缓存:sessionfacory级别的缓存
二级缓存默认不开启 要在XMl文件中开启 二级缓存 、
并且确定二级缓存的供应商
然后确定需要缓存的对象



应用场景:
1)什么样的数据应该方法缓存里面
a)经常被访问
b)不经常修改
c)不是很重的数据,允许偶尔出现并发问题
2)不应该放在缓存中的数据
a)经常被修改
b)重要的数据,不允许发生并发问题
3)性能和安全都在的时候先安全
1)内置缓存:给Hiberate自己使用
2)外置缓存:给用户使用,但是只提供了一个接口,具体实现由第三方来做
三级缓存--查询缓存----查询缓存要依赖二级缓存
需要开启查询缓存:

1)导入jar包
2)开启二级缓存
3)确定二级缓存的供应商
4)配置要缓存的对象
1)<class-cache>
a)class:需要被缓存的对象
b)usage:缓存的数据是否能被修改,一般都是只读
2)<collection-cache>:可以缓存一个集合,还要把集合中方的对象也要缓存起来
---------------------------------------------------------------------------------------------------------------------------------------------------------------
Hibernate里面也可以使用原生态的Sql语句
session.createSQLQuery("sql")
这种一般适用于比较复杂的SQL语句 一般都是用前面的 HQL 和 自定义的方法
几种方式比较

-----------------------------------------------------------------------------------------------------------------------------------------------------
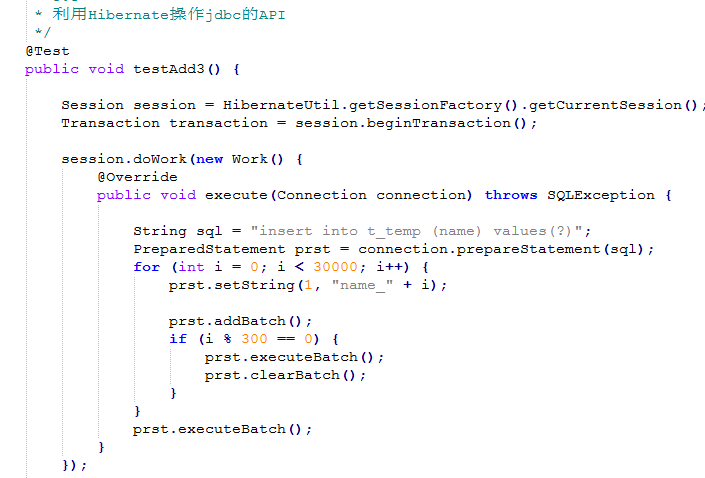
批处理 :
1.Hibernate框架是提高开发效率,性能没有jdbc高
2.项目中做批量操作的时候要用jdbc
3.commit的方法会隐式调用flush()
----------------------------------------------------------------------------------------------------------------------------------------------------
Hibernate整合C3p0
a)导入jra包
b)配置
1)配置c3p0的驱动
2)配置c3p0属性

-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
锁:解决并发问题
乐观锁:
修改的时候总会认为别人不会修改,底层通过版本号控制来实现
1)原理
a)表中添加一个version字段
b)添加的时候先判断version字段是否一致
1)如果一致就提交,版本号自增
2)如果不一致就不让提交,说明数据已经被别的事务修改
2)Hibernate中如何实现
a)表中添加一个version字段
b)对象中添加一个version属性
c)在映射文件中建立关系
d)这个字段Hibernate会帮我们维护
悲观锁 :
b)悲观锁:修改的时候总会认为别的事务也会修改,所以要加锁。底层通过数据库锁实现的
1)select * from t_user where id = 1 for update
2)session.get(User.class, 1, LockOptions.UPGRADE);
-------------------------------------------------------------------------------------------------------------------------------------------------------
最后在连接前端的时候需要进行级联操作 然而Session 已经关闭 会报错 所以我们要添加过滤器设置Session关闭的时机


----------------------------------------------------------------------------------------------------------------------------------------------
利用注解实现对象关系映射:
首先在核心配置文件里面要改变映射表达 配置全类名即可

然后在实体类的上面进行关系映射
2)注解
a)@Entity // 实体类
b)@Table // 表名称
c)@id // 主键
d)@column // 列名称
e)@OneToMany // 一对多
f)@ManyToOne // 多对一
g)@joinColumn // 关联外键

=====================================================================================================================================