上周五就要发的,拖........拖.......拖到现在,文中有不准确的地方,欢迎批评指正。
DeepID是一种特征提取的算法,由港中文汤晓鸥团队于2014年提出,发表于CVPR2014。其应用领域是人脸识别的子领域——人脸验证,就是判断两张图片是不是同一个人。之前的人脸验证任务主要的方法是使用过完备的(over-complete)低层次特征,结合浅层的机器学习模型进行的。过去的方法常常是将人脸提取出几万乃至几百万的特征,然后将特征进行降维,再计算两个特征的相似度,本文提出一种使用深度学习提取人脸深层次特征(称之为DeepID)的方法。DeepID特征由人脸分类任务学习得到,此特征可以用于人脸验证中,最终在LFW数据集上取得了97.45%的成绩。
一、网络架构
DeepFace的架构并不复杂,层数也不深。网络架构由4个卷积层 + 1个全连接层构成。

二、从实现过程,理解网络
(一)做patch
1.截区域
按照人脸特征点的分布,在1张输入图片上取10个区域,如下图所示:

2.数据增强
(1)将每个区域,resize成3中不同尺度的pic,如下图所示:

(2)将图像进行水平翻转

(3)提取灰度图

(4)patches总量
经过前3步的数据增强,此时的1张image,产生了10 * 3 * 2 * 2 = 120个区域,将每1个区域与其水平翻转的区域,送入网络,进行特征提取。此步共训练60个神经网络。输出160*2维的DeepID

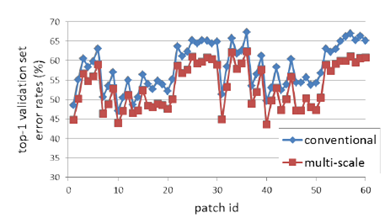
3.增加patches效果
由下图可见,增加patches数量后,网络性能,相对于只用了1整张image的原始结构,提升明显,感觉就是数据增强的原因。

(二)过ConvNets

以1个区域的输入为例,如果区域是长方形,则resize成39*31,如果如果区域是正方形,则resize成31*31,假设本次输入的区域是长方形,喂入网络,如上图所示。
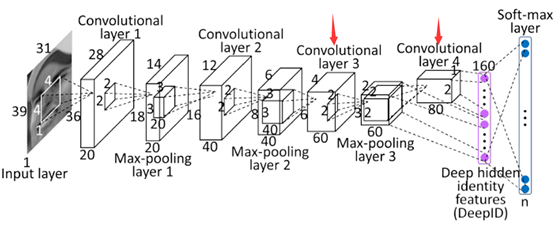
图片经过4层卷积,第3层,和第4层的feature map分别是3*2*60,和2*1*80维。将最后2层的feature map分别过全连接层,concatenate成1个160维的vector

不同hierarchy的Feature map叠加在一起,分类器可以看到多尺度的图像。想当于联系了上下文,网络性能更好。
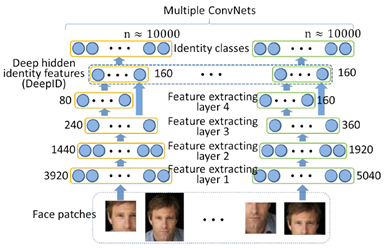
将上文160维的vector送入soft-max进行分类,输出10000分类的结果。60个网络,各自对应各自预测的cls结果,如下图所示:
三、利用DeepID做verification
本来以为做完cls,这个paper就可以结束了,然鹅,看了paper后面密密麻麻的2张,才意识到这个paper是关于verification的,之所以要做cls,主要是多分类的训练,可以提高ConvNet的提取特征的能力,终其目的,还是为了拿到提取的特征,做其关心的verification
(一)用前面训练好的网络,对2张图片做verification
每张照片,根据是否水平翻转,分为2组,每组有60个patches(10个区域,每个区域3个size,每个size有RGB和Grey2种模式)
将每1个区域与其水平翻转对应的部分,联合要对比的图片的同一个区域,组着在一起,送入网络,进行特征提取。此步调用了60个神经网络。
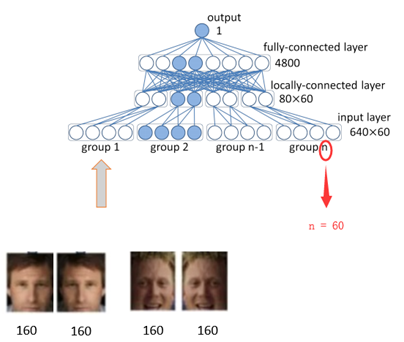
每张输入的160维vector,即为那个区域的identity,可视化160维的数据如下,可以看出相同人脸的identity相似度高,不同人脸的identity区别较大。

1张image经过网络,输出120(60个patches,每个patch里2张图)*160=19200维vector,以此vector表征人脸的identity。
将2张face的identity,送入joint Bayesian,判断是否为同1个人。
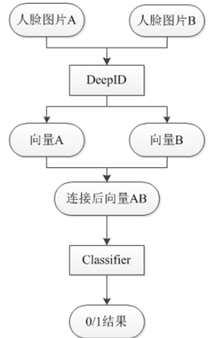
下面介绍一下classifier里面的joint Bayesian分类器
(二)Joint Bayesian
(1)经典Bayesian Face
在介绍joint Bayesian之前,先看一下joint Bayesian出现之前,业界广泛使用的经典Bayesian Face,算法描述如下

但是经典bayesian从2维投射到1维时,会丧失一些分区信息,导致在2维平面上可分的目标,在1维平面上变得不可区分。

从上图中可以看到,2-D的数据通过差分x-y映射到1-D上。O附近的点交错在一起, 使得在O附近的Class-1 和Class-2 无法区分开来。这就是经典Bayesian Face的缺陷
(2)joint Bayesian
针对经典Bayesian Face出现的问题,中科大,港中文以及亚研院的4位同学,在孙剑的指导下于2012年提出来joint Bayesian方法

(三)神经网络分类器
14年,当时的verification sota 分类器还是joint Bayesian,神经网络成绩一般,作者试了这2种方法后,选择了性能更优的joint Bayesian
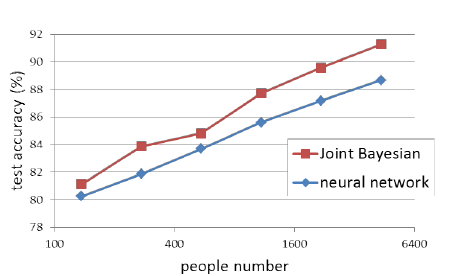
四、网络成绩
DeepID相对于传统的PCA方法,表征能力进一步增强
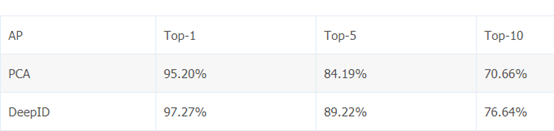
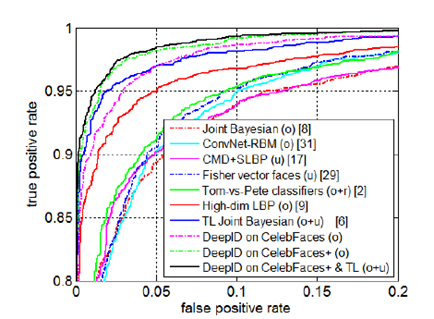
DeepID在LFW数据集上取得了97.45%的准确率,相比于DeepFace的97.35%,获得了进一步的提高。ROC曲线如下:
五、数据指标
简单的介绍下ROC,以前看的时候没有仔细去弄明白这个指标,最近看好多paper上都有这个东西,查阅了资料,总结如下
ROC全名叫receiver operating characteristic curve,中文译为:接收者操作特征曲线,用以说明二分类器在识别阈值变化时的诊断能力。
ROC将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。绘图方法如下
(一)统计样本分类score
将一系列样本,按照positive可能性得分,进行排序

(二)计算真阳率和假阳率
以score作为阈值,依次对排好序的样本进行判断,score > threshold, 则判定为Positive, 否则判为Negative,每一个threshold计算1次真阳率和假阳率,做出这个20个样本的真阳率-假阳率对应图。

(三)ROC曲线优势
为什么要使用ROC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变换的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现样本类不平衡,即正负样本比例差距较大,而且测试数据中的正负样本也可能随着时间变化。下图是ROC曲线和Presision-Recall曲线的对比。

(a)和(c)为Roc曲线,(b)和(d)为Precision-Recall曲线。(a)和(b)展示的是分类其在原始测试集(正负样本分布平衡)的结果,(c)(d)是将测试集中负样本的数量增加到原来的10倍后,分类器的结果,可以明显的看出,ROC曲线基本保持原貌,而Precision-Recall曲线变化较大。
六、小结
分类数提高,可以学到表征力更强的identity
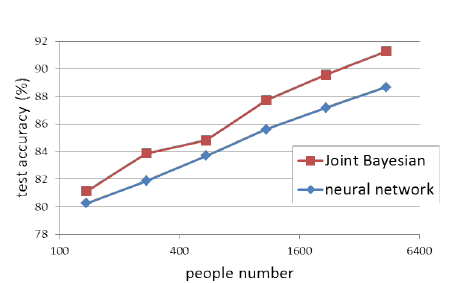
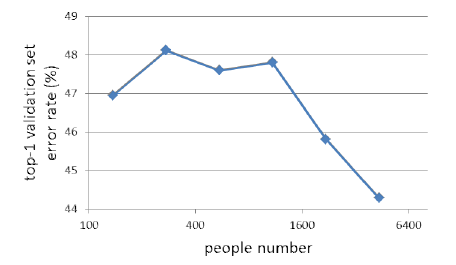
用更多的分类来训练网络,测试的error rate持续降低。一开始还疑惑DeepID初衷是做verification,为什么一开始要用softmax做cls,其实原因到这里就明了了,分类越多,学到的160维的identity表征力越强。