.中文分词
- 下载一中文长篇小说,并转换成UTF-8编码。
- 使用jieba库,进行中文词频统计,输出TOP20的词及出现次数。
- 排除一些无意义词、合并同一词。
- 对词频统计结果做简单的解读。
import jieba txt=open('背影.txt','r',encoding='UTF-8').read() for i in ''',,.。、"“”'-??;:;;!! u3000ufeff''': txt=txt.replace(i,'') words=list(jieba.cut(txt)) dic={} for i in words: if len(i)==1: continue else: dic[i]=dic.get(i,0)+1 a=list(dic.items()) a.sort(key=lambda x:x[1],reverse=True) #print(a) for i in range(20): print(a[i])
运行结果是: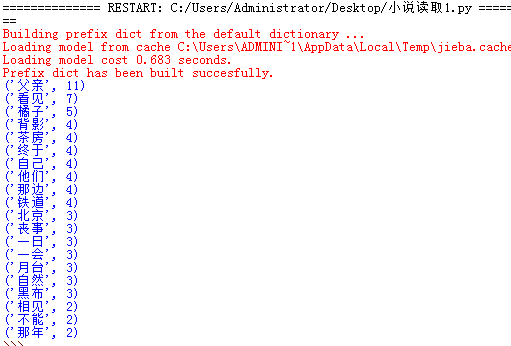
解读:我选取的小说是朱自清的《背影》,根据运行结果可以知道,该文章主要讲的是作者的父亲,处理好家人的丧事,他们大概在北京离别的铁道边上,作者父亲照料他上车,并替他买橘子的情形。在作者脑海里印象最深刻的,是他父亲替他买橘子时在月台爬上攀下时的背影。