华为codecraft2018总结
想来也是参加了第二次了,自己还是那么的菜。总结下今年的比赛,得奖是不存在的了,但是收获还是有的。
代码相关的都在这里了:https://github.com/huipengly/CodeCraft-2018-ecs
一、赛题
为了防止明年赛题官网更新,这里我传一份在网盘。
链接: https://pan.baidu.com/s/1C--5XEtVQq3LJQXWq_4yXw 密码: z5mc
二、赛题分析
首先,官方不让用第三方库了(上一年没参加,但是也是不让用了)。我参加的第一年,大家用库用的太疯狂了,不是编程大赛了。真是苦了python选手。
今年的赛题主要分为两个方面,第一是对flavor数量的预测。第二是对预测结果进行分配。
预测方面,这是一个时间序列预测的问题。数据中体现的特征有历史销量数据和flavor的型号参数。这里,我认为有助于预测的特征信息有1.flavor的cpu/mem比例。2.日期中的周末,节假日。从官方的给出的数据例子中,可以看出,节假日和周末的购买量明显的小。这两点看出来了,但是不知道怎么用,很无奈。
装箱方面,官方这里有一个小坑。赛题里提到了优化方向有cpu和mem两种,只需要将其中所需要的一个优化到最小。但是去仔细推导一下,由于系统不允许物理机资源超分,无论要求那个优化方向,只需要将总物理机数目优化到最小即可。所以装箱对整个赛题分数的影响较小,最重要的还是预测。
三、解题思路
3.1数据预测
数据预测用了挺多方法的,越做分越低(心疼自己)。
1.线性自回归(AR)
最简单的一个方法。初赛指导思路上给到的预测思路就是这个。这是统计学里做时间序列预测最简单的方法。AR方法认为,下一时刻的数据与之前n个时刻的数据是线性相关的,只是与每个时刻相关性不同,需要乘一个系数。最后的公式如下。3.3.2为矩阵形式,具体为3.3.3式。这里Xp是p时刻的数据。
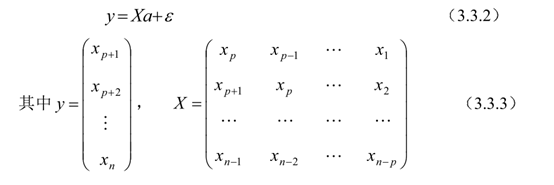
知道形式之后,有两个问题需要确定,第一是之前p个时刻相关,这个p如何确定。第二是在确定p后,每个时刻的系数如何确定。
对于问题一,我没有学会,比赛代码中的阶数是随便试的。哎,数学能力太差。怀念本科做比赛只用写代码的日子。
对于问题二,一般使用的就是最小二乘法。预测做不到准确无误,最小二乘法就是寻找一个式3.3.2中的a,使得式子的误差最小。对于矩阵有求解公式,具体的推导可以看这篇博文https://blog.csdn.net/monsterhoho/article/details/46753673。
目标函数:
解:
当阶数p定的不好时,可能会不可逆。我的做法是,不可逆就降低阶数。
这个方法是一开始就实现了的。结果是分最高的,贼气,虽然也就68分。
2.神经网络
本科做数模,神经网络对于我就是一个工具箱,把数据导进去就好了。也不懂输出的是个啥,为啥这么输出。这次算是把全连接网络和bp(反向传播)看懂了。本应在上学期上课学会的。想出这个方法的人真牛逼。具体讲解、推导可以看这个。
https://www.zybuluo.com/hanbingtao/note/476663
然后就是c++实现,写了两天,没写出来,真丢人。一定程度上说明自己没有完全看透这个算法。然后用了别人的代码,跑了起来。
三层神经网络,第一层输入层,输入预测前三天的数据。第二层隐层,4个节点。第三层输出层,输出预测结果。梯度下降方法没看代码,不清楚。学习率0.5。
输入数据做了缩放处理,将所有历史数据缩放为0-1的数。历史数据中最大的数据为1,最小为0.
最后结果是60-65吧。
3.自回归滑动平均模型(ARMA)
在线性自回归中加入了对误差的使用。具体做法是,首先用比较高的阶数进行一次ar,会得到一个预测结果和预测误差,这里的预测误差就是MA所用到的误差值。第二部,使用误差来做arma。预测方法还是最小二乘法。简要的如下图。

具体的讲解可以看这三个pdf,把ar、ma、arma讲的很清楚。分数50多。
4.还是arma,但是有新想法
在这个时候,看了别人做天池,盐城车牌上牌量的比赛,我有了一个新的想法。这里我们需要预测几个flavor,把flavor整体先加起来,预测整体的数据,再将整体预测的数据拆分到每一个flavor。这样做的好处是让每天的数值更大,之前每个flavor时,数据比较稀疏,有较多的天数没有数据,我认为是不利于预测的。但是这样也有一个很大很大的坏处,最后没有很好的拆分想法,结果还是不理想。
总体预测。然后按照总的/最后30天的/最后7天的比例拆分,分数很低,而且是个下降的趋势。
把数据按照7天/3天先平均一下,分数更低。
加一点点随机值后,能够把分数提到69。改了评分bug之后,始终上不去70。
3.2预测结果装箱
由于上学期学习了智能优化方法,自己写过遗传算法的代码,所以决定使用遗传算法。遗传算法是一种启发式算法,通过模仿生物进化的优胜劣汰来巡游,并且有一定的跳出局部最优的能力。具体遗传算法的内容可以去网上搜,很多资料。这里讲主要思想。
遗传算法染色体编码有很多种,这里使用顺序编码,按照1-n的自然数进行编码,每个自然数出现且只出现一次。
染色体解码,首先将预测出的n个flavor按照1-n的自然数进行编号。染色体会是这n个编码的排列,例如预测了5个flavor,染色体可能是1|3|2|5|4,按照从前往后的顺序放入物理机,当物理机被装满时,向下一个物理机放置。直到染色体被放置完,完成染色体解码。
染色体交叉,这里我使用了ox的方式。可以看这个网站了解染色体交叉的信息。https://blog.csdn.net/u012750702/article/details/54563515。使用轮盘赌的方式选择交叉的染色体。轮盘赌可以看这个网站:https://www.cnblogs.com/adelaide/articles/5679475.html
我测试的分配的速度、结果都不错。
四、结果
渣渣效果,我觉得时预测阶段没做好。还是自己数学能力太弱了,满脑子都是编程。最后测试用例300分,就拿了220分。
写这个博客纪念一下这个比赛吧,虽然自己很菜。