一、学习资料
北京博雅数据酷客平台大讲堂:http://cookdata.cn/auditorium/course_room/10017/
案例分析:http://cookdata.cn/note/view_static_note/91fef440f61ec0fa68c121b958fd6385/
二、内容
1、什么是降维?

2、PCA:基本原理、优化目标和求解方法

优化目标:

3、自编码器:找到数据高效表示的神经网络方法

4、实践案例:PCA算法的Python实现
1)Numpy 的 linalg 模块实现了常见的线性代数运算,包括矩阵的特征值求解。其中 eig 函数能够计算出给定方阵的特征值和对应的右特征向量。我们实现函数 principal_component_analysis,其输入为数据集 XX 和主成分数量 ll,返回降维后的数据、 ll 个主成分列表和对应的特征值列表。主成分按照特征值大小降序排序。
import numpy as np def principal_component_analysis(X, l): X = X - np.mean(X, axis=0)#对原始数据进行中心化处理 sigma = X.T.dot(X)/(len(X)-1) # 计算协方差矩阵 a,w = np.linalg.eig(sigma) # 计算协方差矩阵的特征值和特征向量 sorted_indx = np.argsort(-a) # 将特征向量按照特征值进行排序 X_new = X.dot(w[:,sorted_indx[0:l]])#对数据进行降维 return X_new,w[:,sorted_indx[0:l]],a[sorted_indx[0:l]] #返回降维后的数据、主成分、对应特征值
2)生成一份随机的二维数据集。为了直观查看降维效果,我们借助 make_regression 生成一份用于线性回归的数据集。将自变量和标签进行合并,组成一份二维数据集。同时对两个维度均进行归一化。
from sklearn import datasets import matplotlib.pyplot as plt %matplotlib inline x, y = datasets.make_regression(n_samples=200,n_features=1,noise=10,bias=20,random_state=111) x = (x - x.mean())/(x.max()-x.min()) y = (y - y.mean())/(y.max()-y.min()) fig, ax = plt.subplots(figsize=(6, 6)) #设置图片大小 ax.scatter(x,y,color="#E4007F",s=50,alpha=0.4) plt.xlabel("$x_1$") plt.ylabel("$x_2$")
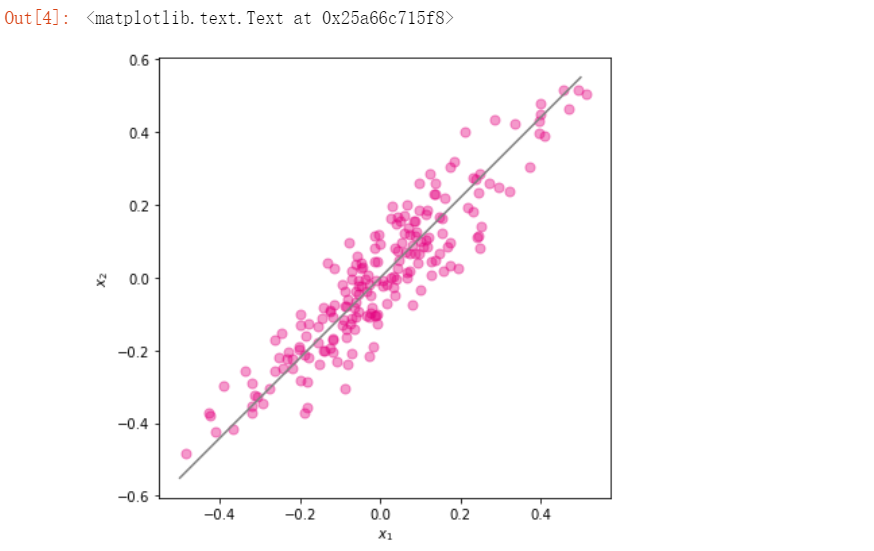
3)使用 PCA 对数据集进行降维,并将第一个主成分方向的直线绘制出来。直线的斜率为 w[1,0]/w[0,0]。将主成分方向在散点图中绘制出来。
import pandas as pd X = pd.DataFrame(x,columns=["x1"]) X["x2"] = y X_new,w,a = principal_component_analysis(X,1) import numpy as np x1 = np.linspace(-.5, .5, 50) x2 = (w[1,0]/w[0,0])*x1 fig, ax = plt.subplots(figsize=(6, 6)) #设置图片大小 X = pd.DataFrame(x,columns=["x1"]) X["x2"] = y ax.scatter(X["x1"],X["x2"],color="#E4007F",s=50,alpha=0.4) ax.plot(x1,x2,c="gray") # 画出第一主成分直线 plt.xlabel("$x_1$") plt.ylabel("$x_2$")
5、运行截图