一、学习资料
北京博雅数据酷客平台大讲堂:http://cookdata.cn/auditorium/course_room/10018/
案例分析:http://cookdata.cn/note/view_static_note/24b53e7838cde188f1dfa6b62824edbb/
二、学习内容
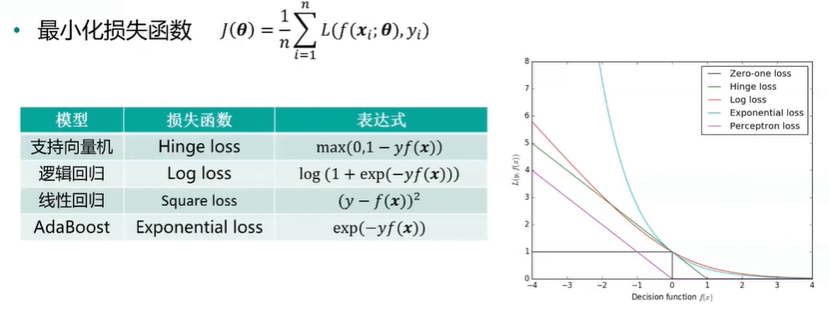
1、机器学习模型的优化目标
2、随机梯度下降(SGD)


3、动量法(momentum)

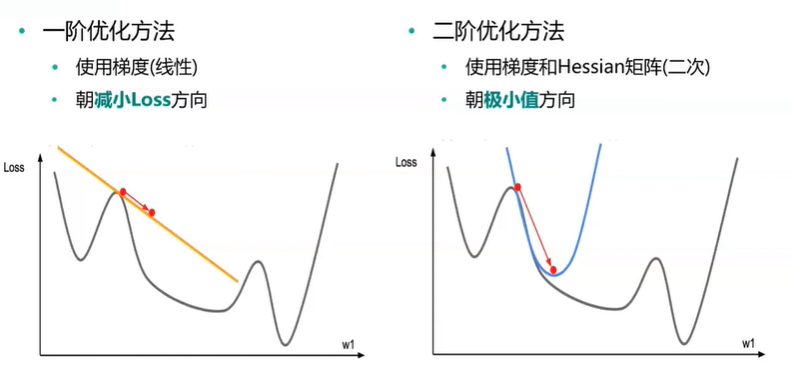
4、二阶方法
5、实现梯度下降
简单优化函数:借助Python的匿名函数定义目标函数
f1 = lambda x1,x2 : x1**2 + 0.5*x2**2 #函数定义 f1_grad = value_and_grad(lambda args : f1(*args)) #函数梯度
梯度下降法使用迭代公式![]() 进行参数更新
进行参数更新
def gradient_descent(func, func_grad, x0, learning_rate=0.1, max_iteration=20): path_list = [x0] best_x = x0 step = 0 while step < max_iteration: update = -learning_rate * np.array(func_grad(best_x)[1]) if(np.linalg.norm(update) < 1e-4): break best_x = best_x + update path_list.append(best_x) step = step + 1 return best_x, np.array(path_list)