项目地址
github项目地址
注:因为使用的是java语言,为了保证没有java环境的计算机可以运行,在BIN目录下内嵌了JRE,所以会显得整个程序有点大(zip格式下载下有110MB)
结对成员
黄浩 031502310
刘晓 081500124
生成数据程序
一组最“好”的数据 input_data.txt
数据生成原理:
学生信息:
学号增量生成
时间生成:
对于每一个星期先随机决定是否有空,如果有空,则规定在8:00与21:00(这个时间段比较符合学生作息)间随机生成13个互斥的有空时间段.如果生成的时间为空,则默认有空时间为"Sat.19:0021:00" 这个比较常见的有空时间
部门申请表:
先随机生成部门申请的个数
然后在随机一种方式遍历部门列表进行随机选择(正序,逆序,随机区间正序,随机区间逆序)。
选择完调用shuffle函数打乱顺序,模拟随机优先级.如果最后生成的为空,则在部门中随机挑一个
兴趣标签:
有一个兴趣标签列表,遍历列表进行随机取舍
部门信息:
编号增量生成
限定人数10~15随机选一个数
时间生成:
先取一个13的随机数表示部门的活动时间数(部门活动时间一般每周13个比较合适)
取一个随机遍历方式(正序,逆序,随机区间正序,随机区间逆序)对星期进行遍历
对于每一个星期先随机决定是否有空,如果有空,则规定在8:00与21:00间随机生成13个互斥的有空时间段.如果生成的时间为空,则默认有空时间为"Sat.19:0021:00" 这个比较常见的有空时间
兴趣标签:
有一个兴趣标签列表,遍历列表进行随机取舍
考虑因素:
合理的作息时间,部门的活动时间个数不能太多(之前部门和学生的时间生成用的是同一个函数,结果部门的活动时间过多导致部门和学生的匹配十分不成功),对于时间的生成、部门申请表的生成尽可能公平(每个星期都有可能取到,每个部门都尽可能申请)
数据生成的核心部分Util.java
匹配数据程序
核心代码
建模过程
Department类
部门编号department_no
各部门需要学生数的要求的上限member_limit
各部门的特点标签tags
各部门的常规活动时间段event_schedules
部门录取学生成员members
Student类
学生编号student_no
学生空闲时间段free_time
兴趣标签tags
部门意愿applications_department
DSSystem类
学生列表studentList
部门列表departmentList
未被部门选中的学生finalUnluckyStudent
未被分配到学生的部门unluckyDepartment
Util类
基本的IO操作和数据处理
匹配思路
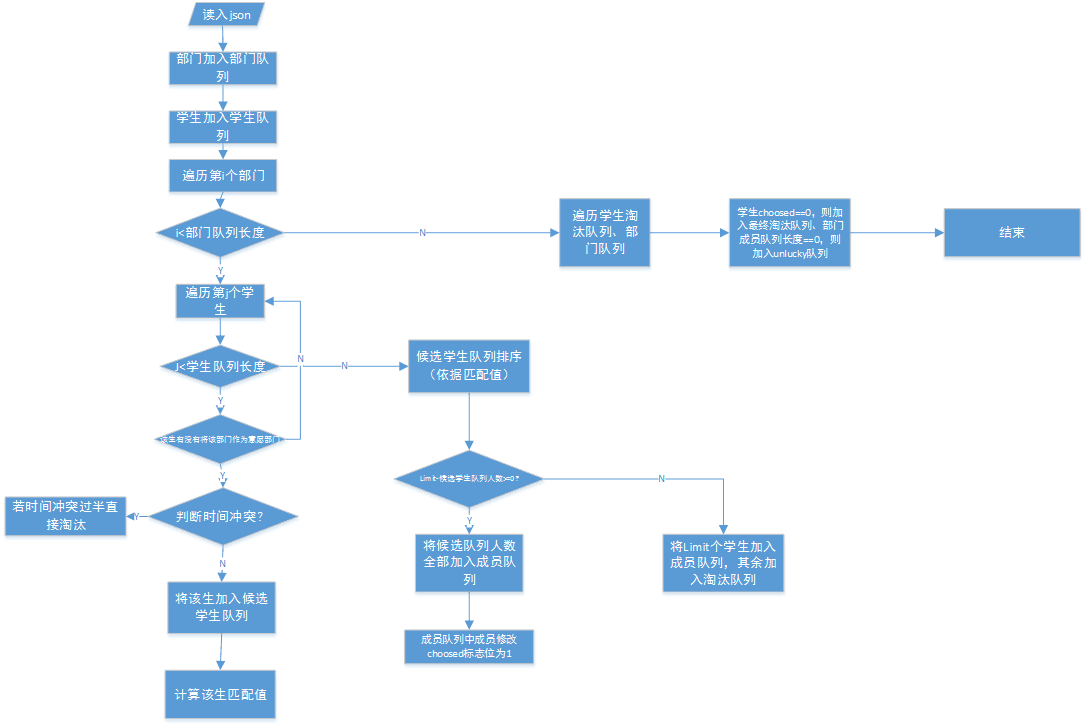
1.对学生列表studentList进行一次遍历,将有意愿的学生加入相应的部门的候选列表candidates。
2.遍历部门列表departmentList,对每个部门的候选列表的成员计算一个匹配值count,然后按照这个值排序。然后根据排序结果取出在最大人数限定范围limit内匹配值不为0学生,加入部门的成员列表members,并且让学生的加入部门数+1,同时修改学生的空闲时间,让学生的空闲时间排除掉加入部门的活动时间。没有加入的学生进入unluckyStudent集合。
3.对unluckyStudent列表中的每个学生进行遍历,如果加入的部门数为0,则加入最终不幸运列表finalUnluckyList;
4.对部门列表遍历,如果部门的成员数为0的话,加入不幸运的部门列表unluckyDepartment
PS. 匹配值计算
需要为智能匹配算法确立分配原则,之前考虑说以兴趣为优先,经讨论,决定综合考虑兴趣、部门意愿优先级、和时间冲突情况(其中比重比较大的是时间冲突的状态,各个比重可以根据实际进行调整)。通过匹配值count的计算来排序得到部门录取学生的序列。
匹配公式:
//如果超过1/2活动时间未能到达,则淘汰(返回0)。
if(conflict>(timeSize*1/2)) {
return 0;
}
count=3*(5-choosed)+4*(hobbies)+3*(5-priority)+10*(timeSize-conflict+1);//考虑的因素:已加入部门的个数越少越好+兴趣匹配越高越好+优先级匹配越高越好+时间冲突个数越少越好
代码规范
因为使用的是java语言,java有一套成熟的语言规范,所以使用该规范。
1.注释习惯
2.左大括号不换行,右括号换行

3.类名采用各单词首字母大写,变量名和函数名采用驼峰规则
4.变量命名以英文单词组合而成


5.各种缩进,空行等在个人注意的同时,最后使用eclipse的代码格式快捷键进行统一的java规范格式。
结果评估
中间过程
改进:
比较函数方向错了
修复了时间冲突逻辑错误(原本是在星期几相同的情况下遍历当天时间判断是否冲突,有冲突则返回,但是没有考虑到同一天有多个时间段导致了错误判断时间冲突)
时间冲突函数返回冲突个数而不是返回是否冲突(是为了呼应匹配值计算的时候宽容一些,一半的活动时间冲突则直接淘汰,否则进行排序考虑,这也比较现实,也是一些部门的底线)
修改了评估函数count(对一些参数进行调整)
最终结果
通过对上述生成样例进行分析input_data.txt,可以得出结果output_data.txt:
1.未匹配人数:192人,占比64%;
2.未匹配部门:1个,占比5%;
3.部门最多招纳人数:14人;
4.部门平均招纳人数:6.3人。
基本满意。
总结
结对感受
作业发布之后,我们在10.5号网络交流过程中,我们选择了使用java语言(我是因为在暑假学习过程中有用java处理过json格式文件,我的伙伴是因为想要锻炼使用java语言的能力),同时决定使用jackson包进行json处理。然后决定10.5号晚先各自思考,10.6上午,我搭建了一个框架(需要类,需要哪些函数,相当于骨架)然后10.6号的晚上第一次见面,同时分工编程,对骨架进行逐步填充。之后不断的在网络交流,见面交流,代码改进之间循环,才有了这一次作业的完成。
结对过程与个人编程相比,有很大的不同。一方面,要经常进行跟伙伴进行沟通交流,每个思路都要双方拍板,沟通的方法以及效率上都是很大的考验,因为同伴并不是同班的,在沟通上增加了困难。另一方面伙伴减轻了编程的压力,同时可以多一个人对算法思路以及实现进行检验,提出问题,同时一起解决问题,同时可以分享经验与建议,从而自我成长。
伙伴印象
同伴是一个十分细心而且好学的人。在共同的讨论中,她会注意到一些细节部分的处理。另外在这个过程中她从一个入门者也渐渐得明白了java的一些思想和eclipse的使用。我相信她也是有收获的。虽然她是一个入门者,但是会询问问题,我在讲述代码的规范以及Java特性时会特别认真的聆听(倾听是十分重要的),印象最深的就是跟她讲述Java的List,ArrayList,HashMap,Set等集合接口或集合类的异同点和适用场合。还有就是在整个问题的难点--时间处理上,我把问题想复杂化了,还想着为时间写一个减法,但是她提出了一个观点:学生空闲时间-部门活动时间其实就是4种情况,而且这些情况的处理只是学生的初始时间替换为部门的结束时间或者学生的结束时间替换为部门的开始时间等情况。