读累了就看看实操https://www.cnblogs.com/huasky/p/10214642.html
一、SOA
概念:SOA:Service-Oriented Architecture,面向服务的架构,将应用程序的不同功能(服务)通过定义的接口来实现数据通信;服务治理;服务调度中心和治理中心;
架构演变:单一应用架构ORM | 垂直应用架构MVC | 分布式服务架构RPC | 流动计算架构SOA
ORM :流量小,单一应用,部署一起;关注于简化增删改查的对象关系映射,
MVC :流量增加,应用拆分;关注于提高前端开发速度;
RPC :远程过程调用;通过网络进行远程计算机服务的请求;核心业务抽取;关注于业务的复用和整合;
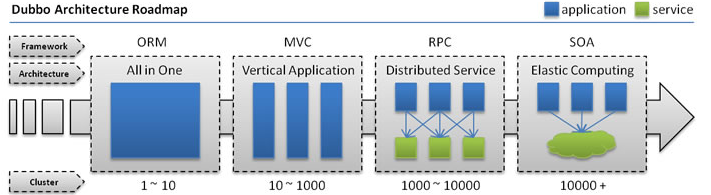
由统一到分布式:


使用场景由混乱到统一:

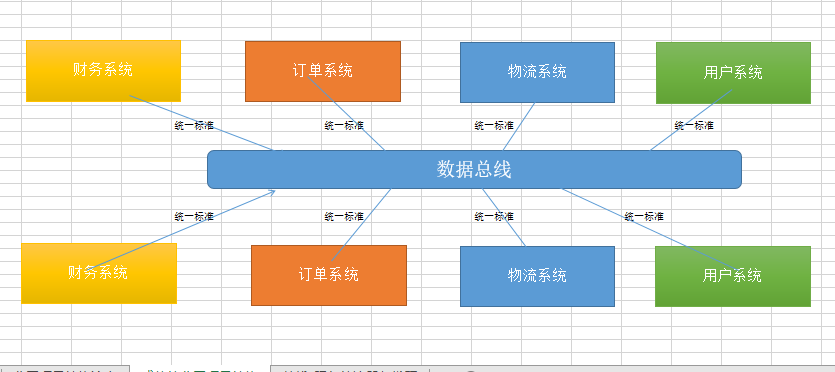
SOA又叫服务治理,SOA就是帮助我们把服务之间调用的乱七八糟的关系给治理起来,然后提供一个统一的标准;
统一标准:各系统的协议、地址、交互方式。
新的交互方式:各个系统分别根据统一标准向数据总线进行注册,各子系统调用其他子系统时,我们并不关心如果找到其他子系统,我们只招数据总线,数据总线再根据统一标准找其他子系统,所以数据总线在这里充当一个只路人的作用。
数据总线是起到调度服务的作用,数据总线不是集成服务,数据总线更新一个调度框架,每个服务需要根据约定向数据总线注册服务;服务不是经过总线的,是直接向client响应;
二、dubbo
概念:dubbo:一个解决大规模服务治理的高性能分布式服务框架;分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架;
流程与说明:
dubbo的架构图如下:

其中,
· Provider: 暴露服务的服务提供方。
· Consumer: 调用远程服务的服务消费方。
· Registry: 服务注册与发现的注册中心。
· Monitor: 统计服务的调用次调和调用时间的监控中心。
· Container: 服务运行容器。
调用关系说明:
-
服务容器负责启动,加载,运行服务提供者。
-
服务提供者在启动时,向注册中心注册自己提供的服务。
-
服务消费者在启动时,向注册中心订阅自己所需的服务。
-
注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
-
服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
-
服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
Dubbo提供了很多协议,Dubbo协议、RMI协议、Hessian协议,Dubbo源代码有各种协议的实现,我们之前没用Dubbo之前时,大部分都用Hessian来使用我们服务的暴露和调用,利用HessianProxyFactory调用远程接口。
原理:
初始化过程细节:
第一步,就是将服务装载容器中,然后准备注册服务。和spring中启动过程类似,spring启动时,将bean装载进容器中的时候,首先要解析bean。所以dubbo也是先读配置文件解析服务。
解析服务:
1)、基于dubbo.jar内的Meta-inf/spring.handlers配置,spring在遇到dubbo名称空间时,会回调DubboNamespaceHandler类。
2)、所有的dubbo标签,都统一用DubboBeanDefinitionParser进行解析,基于一对一属性映射,将XML标签解析为Bean对象。生产者或者消费者初始化的时候,会将Bean对象转会为url格式,将所有Bean属性转成url的参数。 然后将URL传给Protocol扩展点,基于扩展点的Adaptive机制,根据URL的协议头,进行不同协议的服务暴露和引用。
暴露服务:
a、 直接暴露服务端口
在没有使用注册中心的情况,这种情况一般适用在开发环境下,服务的调用这和提供在同一个IP上,只需要打开服务的端口即可。 即,当配置 or ServiceConfig解析出的URL的格式为: Dubbo://service-host/com.xxx.TxxService?version=1.0.0 基于扩展点的Adaptiver机制,通过URL的“dubbo://”协议头识别,直接调用DubboProtocol的export()方法,打开服务端口。
b、向注册中心暴露服务:
和上一种的区别:需要将服务的IP和端口一同暴露给注册中心。 ServiceConfig解析出的url格式为: registry://registry-host/com.alibaba.dubbo.registry.RegistryService?export=URL.encode(“dubbo://service-host/com.xxx.TxxService?version=1.0.0”)
基于扩展点的Adaptive机制,通过URL的“registry://”协议头识别,调用RegistryProtocol的export方法,将export参数中的提供者URL先注册到注册中心,再重新传给Protocol扩展点进行暴露: Dubbo://service-host/com.xxx.TxxService?version=1.0.0
引用服务:
a、直接引用服务:
在没有注册中心的,直连提供者情况下, ReferenceConfig解析出的URL格式为: Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptive机制,通过url的“dubbo://”协议头识别,直接调用DubboProtocol的refer方法,返回提供者引用。
b、从注册中心发现引用服务:
此时,ReferenceConfig解析出的URL的格式为: registry://registry-host/com.alibaba.dubbo.registry.RegistryService?refer=URL.encode(“consumer://consumer-host/com.foo.FooService?version=1.0.0”)
基于扩展点的Apaptive机制,通过URL的“registry://”协议头识别,就会调用RegistryProtocol的refer方法,基于refer参数总的条件,查询提供者URL,如: Dubbo://service-host/com.xxx.TxxService?version=1.0.0
基于扩展点的Adaptive机制,通过提供者URL的“dubbo://”协议头识别,就会调用DubboProtocol的refer()方法,得到提供者引用。 然后RegistryProtocol将多个提供者引用,通过Cluster扩展点,伪装成单个提供这引用返回。
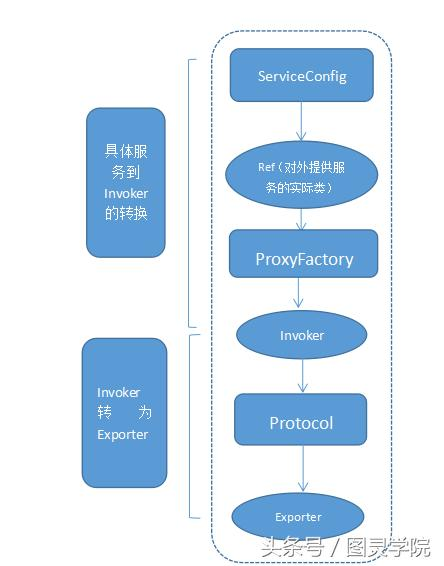
暴露服务的主过程:
首先ServiceConfig类拿到对外提供服务的实际类ref,然后将ProxyFactory类的getInvoker方法使用ref生成一个AbstractProxyInvoker实例,到这一步就完成具体服务到invoker的转化。接下来就是Invoker转换到Exporter的过程。 Dubbo处理服务暴露的关键就在Invoker转换到Exporter的过程,下面我们以Dubbo和rmi这两种典型协议的实现来进行说明: Dubbo的实现: Dubbo协议的Invoker转为Exporter发生在DubboProtocol类的export方法,它主要是打开socket侦听服务,并接收客户端发来的各种请求,通讯细节由dubbo自己实现。 Rmi的实现: RMI协议的Invoker转为Exporter发生在RmiProtocol类的export方法,他通过Spring或Dubbo或JDK来实现服务,通讯细节由JDK底层来实现。
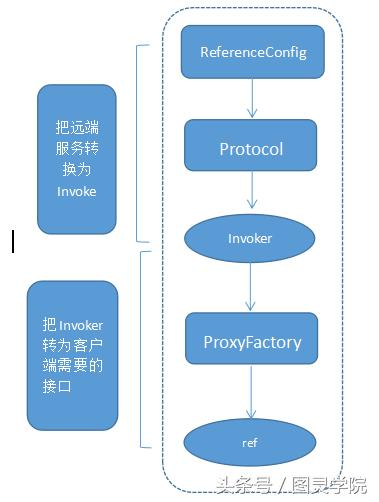
服务消费的主过程:
首先ReferenceConfig类的init方法调用Protocol的refer方法生成Invoker实例。接下来把Invoker转为客户端需要的接口
三、zookeeper(可作为Dubbo的注册中心使用)
概念zookeeper:为分布式应用程序提供协调服务;为其他分布式程序提供协调服务;本身也是分布式程序;
zookeeper提供的服务:配置维护、域名服务、分布式同步、组服务;其实只提供了两个功能(管理数据和监听数据): 管理(存储,读取)用户程序提交的数据; 并为用户程序提供数据节点监听服务;
应用场景:
Zookeeper主要是做注册中心用;基于Dubbo框架开发的提供者、消费者都向Zookeeper注册自己的URL,消费者还能拿到并订阅提供者的注册URL,以便在后续程序的执行中去调用提供者。而提供者发生了变动,也会通过Zookeeper向订阅的消费者发送通知;
用于担任服务生产者和服务消费者的注册中心,服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据;

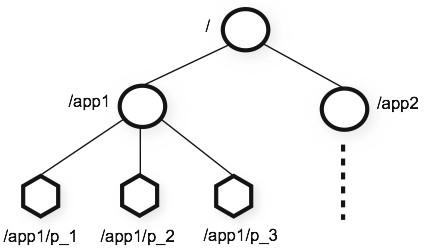
zookeeper数据模型
Znode:目录结构;节点;
数据模型是一棵树(ZNode Tree),由斜杠(/)进行分割的路径,就是一个ZNode,如/hbase/master,其中hbase和master都是ZNode;
每个Znode节点都包含了该节点的数据、状态信息、子节点。状态信息用来记录每次节点变更后的时间戳、版本等信息。因此,当版本发生变更的时候,ZooKeeper会同步修改该节点的状态信息。
Znode有如下特征:
-
监视(Watch)
客户端可以在Znode上面增加监视事件,当Znode发生变化的时候,ZooKeeper就会触发watch,并向客户端发送且仅通知一次,watch只能被触发一次。
-
数据访问
节点数据访问是原子性,每个节点都有ACL(权限列表),规定了用户的权限,可以划分权限设定。
-
节点类型
节点类型分为两种,永久性和临时性。临时性节点在每次会话结束的时候,自动删除。也可以手动删除临时节点,而且临时节点没法建立子节点。
-
顺序节点
每个节点创建的时候,都会给新创建的节点增加1个身份数字,从1开始。它的格式“%10d”,计数超过2^32-1时,会有溢出风险。
Znode类型有4种:永久性节点、临时性节点、永久性有序节点、临时性有序节点
ZooKeeper采用ACL(Access Control Lists)策略来进行权限控制;
zookeeper的5种权限:
·CREATE: 创建子节点的权限。
·READ: 获取节点数据和子节点列表的权限。
·WRITE:更新节点数据的权限。
·DELETE: 删除子节点的权限。
·ADMIN: 设置节点ACL的权限。
注意:CREATE 和 DELETE 都是针对子节点的权限控制。
zookeeper原理:
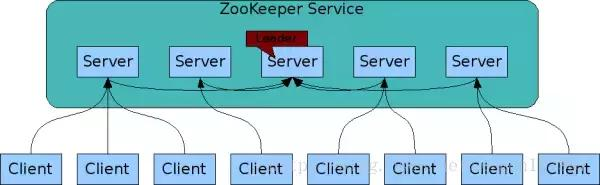
(1)ZooKeeper分为服务器端(Server) 和客户端(Client),客户端可以连接到整个 ZooKeeper服务的任意服务器上(除非 leaderServes 参数被显式设置, leader 不允许接受客户端连接)。
(2)客户端使用并维护一个 TCP 连接,通过这个连接发送请求、接受响应、获取观察的事件以及发送心跳。如果这个 TCP 连接中断,客户端将自动尝试连接到另外的 ZooKeeper服务器。客户端第一次连接到 ZooKeeper服务时,接受这个连接的 ZooKeeper服务器会为这个客户端建立一个会话。当这个客户端连接到另外的服务器时,这个会话会被新的服务器重新建立。
(3)上图中每一个Server代表一个安装Zookeeper服务的机器,即是整个提供Zookeeper服务的集群(或者是由伪集群组成);
(4)组成ZooKeeper服务的服务器必须彼此了解。 它们维护一个内存中的状态图像,以及持久存储中的事务日志和快照, 只要大多数服务器可用,ZooKeeper服务就可用;
(5)ZooKeeper 启动时,将从实例中选举一个 leader,Leader 负责处理数据更新等操作,一个更新操作成功的标志是当且仅当大多数Server在内存中成功修改数据。每个Server 在内存中存储了一份数据。
(6)Zookeeper是可以集群复制的,集群间通过Zab协议(Zookeeper Atomic Broadcast)来保持数据的一致性;
(7)Zab协议包含两个阶段:leader election阶段和Atomic Brodcast阶段。
-
a) 集群中将选举出一个leader,其他的机器则称为follower,所有的写操作都被传送给leader,并通过brodcast将所有的更新告诉给follower。
-
b) 当leader崩溃或者leader失去大多数的follower时,需要重新选举出一个新的leader,让所有的服务器都恢复到一个正确的状态。
-
c) 当leader被选举出来,且大多数服务器完成了 和leader的状态同步后,leadder election 的过程就结束了,就将会进入到Atomic brodcast的过程。
-
d) Atomic Brodcast同步leader和follower之间的信息,保证leader和follower具有形同的系统状态。
Leader算法:以Fast Paxos算法为基础的
zookeeper角色:Leader、learner或follower、ObServer
领导者(Leader):负责进行投票的发起和决议,更新系统状态;
学习者(Learner)或跟随者(Follower):接收客户端请求,并向客户端返回结果,在选主过程中参与投票;如果接收到的客户端请求为写请求,将转发给Leader来完成系统状态的更新;
观察者(ObServer):接收客户端的连接,将写请求转发给Leader;不参与选主过程的投票,仅同步Leader状态;扩展系统,提高读写速度;
应用场景
1 统一命名服务(如Dubbo服务注册中心)
Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,是阿里巴巴SOA服务化治理方案的核心框架,每天为2,000+个服务提供3,000,000,000+次访问量支持,并被广泛应用于阿里巴巴集团的各成员站点。
在Dubbo实现中:
服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。
服务消费者启动的时候,订阅/dubbo/${serviceName}/providers目录下的提供者URL地址, 并向/dubbo/${serviceName} /consumers目录下写入自己的URL地址。
注意,所有向ZK上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。 另外,Dubbo还有针对服务粒度的监控,方法是订阅/dubbo/${serviceName}目录下所有提供者和消费者的信息。
2 配置管理 (如淘宝开源配置管理框架Diamond)
在大型的分布式系统中,为了服务海量的请求,同一个应用常常需要多个实例。如果存在配置更新的需求,常常需要逐台更新,给运维增加了很大的负担同时带来一定的风险(配置会存在不一致的窗口期,或者个别节点忘记更新)。zookeeper可以用来做集中的配置管理,存储在zookeeper鸡群中的配置,如果发生变更会主动推送到连接配置中心的应用节点,实现一处更新处处更新的效果。
3 分布式集群管理 (Hadoop分布式集群管理)
这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:
(1) 集群中机器有变动的时候,牵连修改的东西比较多。
(2) 有一定的延时。
利用ZooKeeper有两个特性,就可以实现另一种集群机器存活性监控系统:
(1) 客户端在节点 x 上注册一个Watcher,那么如果 x?的子节点变化了,会通知该客户端。
(2) 创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
例如,监控系统在 /clusterServers 节点上注册一个Watcher,以后每动态加机器,那么就往 /clusterServers 下创建一个 EPHEMERAL类型的节点:/clusterServers/{hostname}. 这样,监控系统就能够实时知道机器的增减情况,至于后续处理就是监控系统的业务了。
4 分布式锁(强一致性)
这个主要得益于ZooKeeper为我们保证了数据的强一致性。锁服务可以分为两类,一个是 保持独占,另一个是 控制时序。
(1) 所谓保持独占,就是所有试图来获取这个锁的客户端,最终只有一个可以成功获得这把锁。通常的做法是把zk上的一个znode看作是一把锁,通过create znode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
(2) 控制时序,就是所有视图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里 /distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。