第一篇文章,思来想去,写一写Redis吧,最近在深入研究它。
一丶Redis底层结构
1. redis 存储结构
- redis的存储结构从外层往内层依次是redisDb、dict、dictht、dictEntry。
- redis的Db默认情况下有16个,每个redisDb内部包含一个dict的数据结构。
- redis的dict内部包含dictht的数组,数组个数为2,主要用于hash扩容使用。
- dictht内部包含dictEntry的数组,可以理解就是hash的桶,然后如果冲突通过挂链法解决
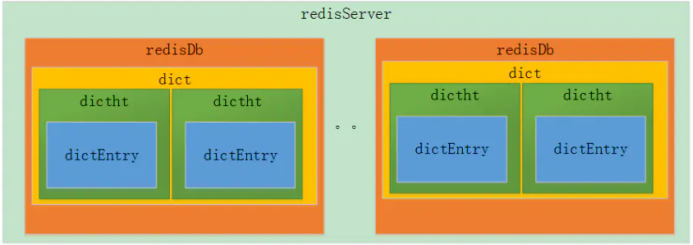
redisServer内部包含着 redisDb *db的数组元素,只是用指针体现而已。
redisDb内部包含着dict *dict和dict *expires,用于存储数据和过期事件。
dict内部包含 dictht ht[2],是存储数据的对象,之所以有两个元素是为了扩容方便。
真正保存数据的核心数据结构, dictEntry **table可以理解为hash的桶,通过挂链法解决冲突。
存储数据的单个节点,包含key和value。保存我们存储在redis的数据。
2.redis 数据存储过程
数据存储过程以set为例作为说明,过程如下:
- 从redisDb当中找到dict,每个db就一个dict而已。
- 从dict当中选择具体的dictht对象。
- 首先根据key计算hash桶的位置,也就是index。
- 新建一个DictEntry对象用于保存key/value,将新增的entry挂到dictht的table对应的hash桶当中,每次保存到挂链的头部。
- dictSetKey的宏保存key
- dictSetVal的宏保存value
3.redis 过期事件存储过程
redis的过期事件存储在db->expires的对象当中,整个设置过期时间的过程如下:
- 从db-dict获取原来存储数据,之所以去取数是为了保证key的存在性
- 从db->expires获取旧的过期事件并重新计算过期时间dictReplaceRaw
- 过期时间重新保存到DictEntry当中,也就是db->expires中的某个对象。
4.命令执行过程
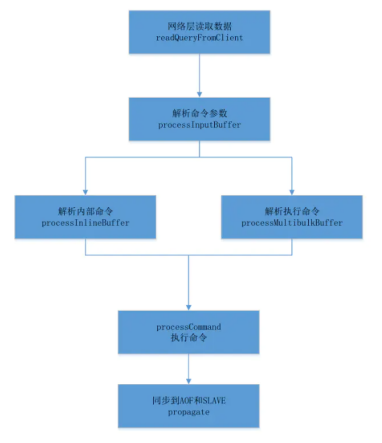
整个redis的server端命令执行过程就如下面这个流程图:
- nio层读取数据
- 解析数据到命令行格式
- 查找命令对应的执行函数执行命令
- 同步数据到slave和aof
二丶Redis底层数据结构
1.string
- 整数:存储字符串长度小于21且能够转化为整数的字符串。
- emstr:存储字符串长度小于39的字符串
- sds:剩余情况使用sds进行存储。
embstr和sds的区别在于内存的申请和回收
embstr的创建只需分配一次内存,而raw为两次(一次为sds分配对象,另一次为redisObject分配对象,embstr省去了第一次)。相对地,释放内存的次数也由两次变为一次。
embstr的redisObject和sds放在一起,更好地利用缓存带来的优势
缺点:redis并未提供任何修改embstr的方式,即embstr是只读的形式。对embstr的修改实际上是先转换为raw再进行修改。
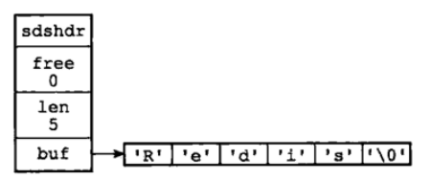
用SDS保存字符串 “Redis”具体图示如下:
2.List
redis list数据结构底层采用压缩列表ziplist或linkedlist两种数据结构进行存储,首先以ziplist进行存储,在不满足ziplist的存储要求后转换为linkedlist列表。
当列表对象同时满足以下两个条件时,列表对象使用ziplist进行存储,否则用linkedlist存储。
- 列表对象保存的所有字符串元素的长度小于64字节
- 列表对象保存的元素数量小于512个。
redis list元素添加过程:
list的数据添加根据传入的变量个数一个个顺序添加,整个顺序如下:
- 创建list对象并添加到db的数据结构当中
- 针对每个待插入的元素添加到list当中
- list的每个元素的插入过程中,我们会对是否需要进行转码作两个判断:
- 对每个插入元素的长度进行判断是否进行ziplist->linkedlist的转码。
- 对list总长度是否超过ziplist最大长度的判断。
3.hashmap
redis的哈希对象的底层存储可以使用ziplist(压缩列表)和hashtable。当hash对象可以同时满足一下两个条件时,哈希对象使用ziplist编码。
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
- 哈希对象保存的键值对数量小于512个
4.set
redis的集合对象set的底层存储结构特别神奇,我估计一般人想象不到,底层使用了intset和hashtable两种数据结构存储的,intset我们可以理解为数组,hashtable就是普通的哈希表(key为set的值,value为null)。是不是觉得用hashtable存储set是一件很神奇的事情。
set的底层存储intset和hashtable是存在编码转换的,使用intset存储必须满足下面两个条件,否则使用hashtable,条件如下:
- 结合对象保存的所有元素都是整数值
- 集合对象保存的元素数量不超过512个
5.zset
zset底层的存储结构包括ziplist或skiplist,在同时满足以下两个条件的时候使用ziplist,其他时候使用skiplist,两个条件如下:
- 有序集合保存的元素数量小于128个
- 有序集合保存的所有元素的长度小于64字节
当ziplist作为zset的底层存储结构时候,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值。
当skiplist作为zset的底层存储结构的时候,使用skiplist按序保存元素及分值,使用dict来保存元素和分值的映射关系。
6.数据结构
ziplist:
压缩列表,压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。
压缩列表的原理:压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。
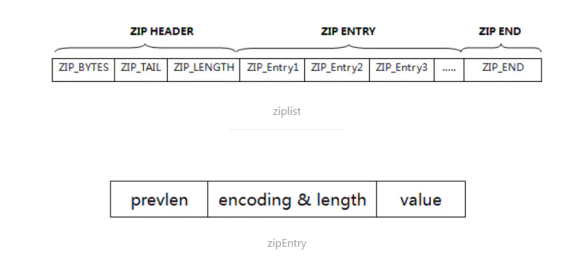
ziplist的数据结构主要包括两层,ziplist和zipEntry。
- ziplist包括zip header、zip entry、zip end三个模块。
- zip entry由prevlen、encoding&length、value三部分组成。
- prevlen主要是指前面zipEntry的长度,coding&length是指编码字段长度和实际- 存储value的长度,value是指真正的内容。
- 每个key/value存储结果中key用一个zipEntry存储,value用一个zipEntry存储。
inset:
intset内部其实是一个数组(int8_t coentents[]数组),而且存储数据的时候是有序的,因为在查找数据的时候是通过二分查找来实现的。整数集合(intset)是Redis用于保存整数值的集合抽象数据类型,它可以保存类型为int16_t、int32_t 或者int64_t 的整数值,并且保证集合中不会出现重复元素。
整数集合的每个元素都是 contents 数组的一个数据项,它们
升级
当我们新增的元素类型比原集合元素类型的长度要大时,需要对整数集合进行升级,才能将新元素放入整数集合中。具体步骤:
- 根据新元素类型,扩展整数集合底层数组的大小,并为新元素分配空间。
- 将底层数组现有的所有元素都转成与新元素相同类型的元素,并将转换后的元素放到正确的位置,放置过程中,维持整个元素顺序都是有序的。
- 将新元素添加到整数集合中(保证有序)。
升级能极大地节省内存。
降级
整数集合不支持降级操作,一旦对数组进行了升级,编码就会一直保持升级后的状态。
按照从小到大的顺序排列,并且不包含任何重复项。
length 属性记录了 contents 数组的大小。
需要注意的是虽然 contents 数组声明为 int8_t 类型,但是实际上contents 数组并不保存任何 int8_t 类型的值,其真正类型有 encoding 来决定。
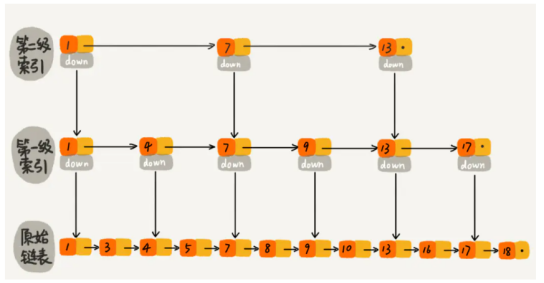
skiplist:
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。具有如下性质:
- 由很多层结构组成;
- 每一层都是一个有序的链表,排列顺序为由高层到底层,都至少包含两个链表节点,分别是前面的head节点和后面的nil节点;
- 最底层的链表包含了所有的元素;
- 如果一个元素出现在某一层的链表中,那么在该层之下的链表也全都会出现(上一层的元素是当前层的元素的子集);
- 链表中的每个节点都包含两个指针,一个指向同一层的下一个链表节点,另一个指向下一层的同一个链表节点;