| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | 为后续的作业预热,遇到困难自主学习,体验一次次commit的感觉以及进行必要的测试与性能分析 |
| 学号 | 061800508 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 800 | 900 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 15 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 15 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 250 | 300 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 60 | 70 |
| Size Measurement | 计算工作量 | 15 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 60 |
| 合计 | 1390 | 1620 |
心路历程
-
期待期:呀,第一次个人编程作业是什么呢,有不有趣啊,
好不好玩呢 -
崩溃期:作业发布时,怀揣着激动与恐惧点开了链接作业链接,一脸懵逼地读完整篇作业要求,内心久久不能平静。这个数据来源是什么鬼?咋读取这个文件啊??What?这一长串的运行格式又是什么鬼??救命!!单元测试覆盖率优化和性能测试是啥啊??是分析算法复杂度、有效效率的意思吗?不好玩,不好玩,这作业一点也不好玩!!

-
冷静期:
- 栋哥:“这作业要是写不出来以后工作怎么办啊!”
- 助教:“这次作业比K班简单很多!”
内心疑惑:嗯?真的吗?那就再认真多看看几次题目呗。嗯,还是看不懂
但是男人不能说不行!! 冲鸭!
冲鸭!
解题思路
题意理解
一道大数据分析题,制作一个程序统计和分析 GitHub 的用户行为数据,就是从一大堆数据中筛选和统计出几个事件的数量吧。
需要解决的问题
- 语言选择:诶,示例代码是python,但我只会C++,很久没用感觉也忘得差不多了,和不会好像没什么差别。听说python比C++简单点,也适合大数据处理?不如就试着用python写写吧。
- 学会读取json文件:写代码从没读取过文件,之前数据全是手动输入。。。
- 学会按照格式要求实现命令行参数
- git的使用
- 学会简单的单元测试、性能分析
具体学习步骤
- 学习python:在网上找了下网课最少也要十几个小时,感觉时间有点来不及,就找了《Python编程从入门到实践》这本书来看。
- 真正写代码前先依据《Python PEP8》制定代码规范。
- 写代码:刚学习python有许多不懂和不熟练,在努力尝试看懂助教的示例代码后。首先从从网上查阅了json文件格式的解析方法,知道了要先用json库,主要就是
json.loads用于解码JSON数据该函数返回Python字段的数据类型。json.dumps用于将Python对象编码成JSON字符串。还有命令行参数应使用argparse模块,创建ArgumentParser()对象,再调用add_argument()方法添加参数,最后使用parse_args()解析添加的参数。 - 测试:测试代码主要参考了大佬们的博客,单元覆盖率就使用Pycharm的
run with coverage,但要下载coverage库,尝试下载好几次都是失败,刚开始以为是网络问题,后来百度了一下才知道是镜像路径不对。其实对测试代码的使用还是有点懵懵的,也不知道具体要测些什么,这几天要再看看。 - 性能分析:使用Pycharm的Profile,一键分析,这个feel崩爽~~。
- 不断commit,git的一些使用参考了这篇教程《廖雪峰git介绍》
- 写博客总结。
设计实现过程
框架设计
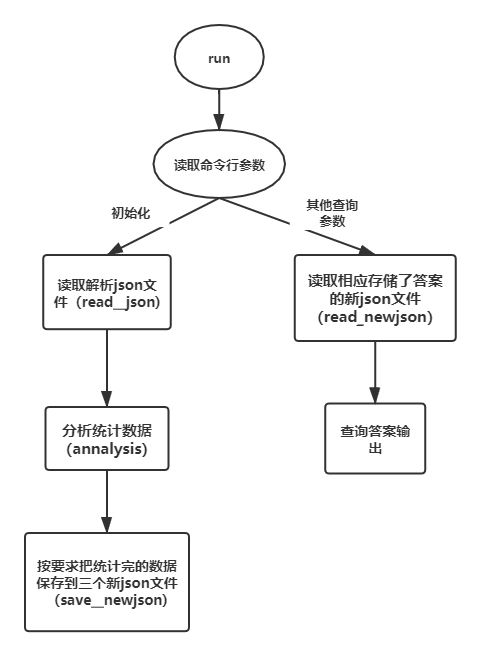
整个代码可以分为几个部分:
- 命令行参数的设置。
- 初始化(包括了json文件的读取,分析数据,存储数据。分别对应read_json、analysis、save_newjson三个函数)
- 其他查询命令(其实就是到三个对应题目要求、存储python字典的json文件找答案,三个问题对应三个query_函数)。
具体流程图
代码说明
命令参数的设置
my_parser = argparse.ArgumentParser(description='analysis the json file')
my_parser.add_argument('-i', '--init', help='json file path')
my_parser.add_argument('-u', '--user', help='username')
my_parser.add_argument('-r', '--repo', help='repository name')
my_parser.add_argument('-e', '--event', help='type of event')
json文件的读取
def __read_json(self):
self.__dicts = []
for root, dirs, files in os.walk(self.__dir_addr):
for file in files:
if file[-5:] == '.json' and file[-6:] != '1.json' and file[-6:] != '2.json'
and file[-6:] != '3.json': #防止误读取到后来生成的三个json文件
with open(file, 'r', encoding='utf-8') as f:
self.__jsons = [x for x in f.read().split('
') if len(x)>0] #列表生成式,读取json文件并按行分割
for self.__json in self.__jsons:
self.__dicts.append(json.loads(self.__json)) #将json文件转换成字典,并添加到列表中
分析与统计数据
def __analysis(self):
self.__types = ['PushEvent', 'IssueCommentEvent', 'IssuesEvent', 'PullRequestEvent']
self.__cnt_perP = {}
self.__cnt_perR = {}
self.__cnt_perPperR = {}
for self.__dict in self.__dicts:
if self.__dict['type'] in self.__types: #属于题目要求的信息
self.__event = self.__dict['type']
self.__name = self.__dict['actor']['login']
self.__repo = self.__dict['repo']['name']
#对三个事件分别进行统计,直接用user+resp+event来当做键,数量当作值,一个字典存取就好,不用字典里套字典
self.__cnt_perP[self.__name + self.__event] = self.__cnt_perP.get(self.__name
+ self.__event, 0) + 1
self.__cnt_perR[self.__repo + self.__event] = self.__cnt_perR.get(self.__repo
+ self.__event, 0) + 1
self.__cnt_perPperR[self.__name + self.__repo + self.__event] = self.__cnt_perPperR.get(self.__name
+ self.__repo + self.__event, 0) + 1
生成三个新json文件
def __save_newjson(self): #使用json.dump()
with open("1.json", 'w', encoding='utf-8') as f:
json.dump(self.__cnt_perP, f)
with open("2.json", 'w', encoding='utf-8') as f:
json.dump(self.__cnt_perR, f)
with open("3.json", 'w', encoding='utf-8') as f:
json.dump(self.__cnt_perPperR, f)
print("Save to json files successfully!")
三个查询函数
def query_cnt_user(self, user:str, event:str) -> int:
return self.__cnt_perP.get(user + event, 0)
def query_cnt_repo(self, repo:str, event:str) -> int:
return self.__cnt_perR.get(repo + event, 0)
def query_cnt_user_and_repo(self, user, repo, event) -> int:
return self.__cnt_perPperR.get(user + repo + event, 0)
单元测试

- 测试了三个查询函数都成功运行,但覆盖率只有百分之75,主要原因应该是主函数中的命令行参数解析没有覆盖到。
性能分析
- 使用Pycharm自带的profile
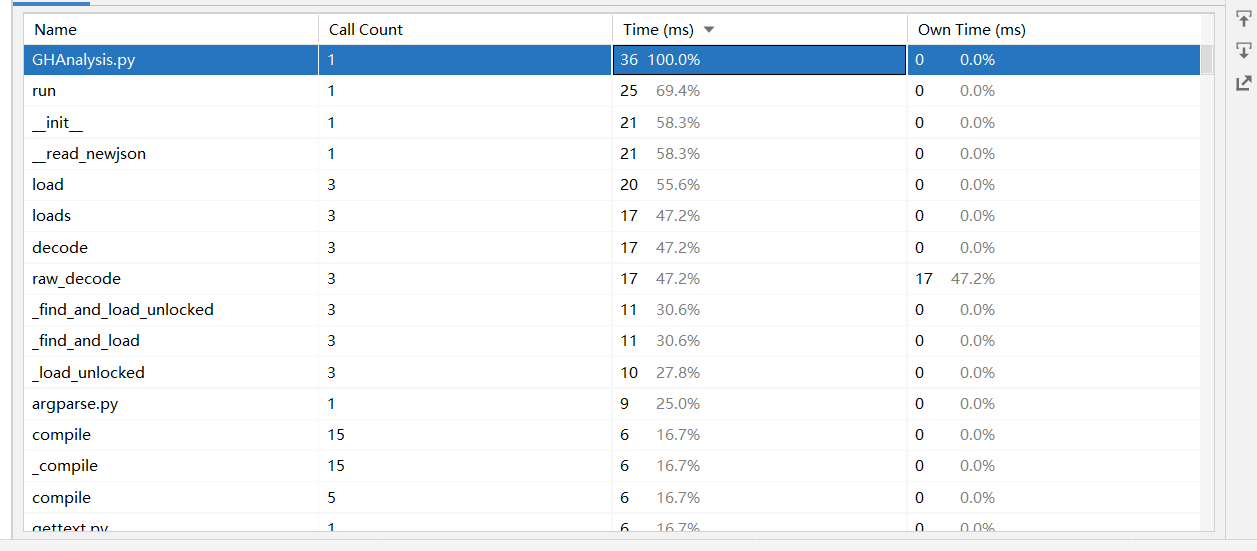

这次的代码只是很普通很常规的代码,性能肯定不算优秀,感觉要改进的话可能要朝着多线程方向努力,但好像python的多线程也并不给力,或许用数据库查询会快一点?但是这已经超出我能力范围,看了大佬们的博客,觉得他们会的东西好多,很羡慕,看来自己也要多多学习,别再做懒狗了。
代码规范
总结
- python这语言真神奇,大一刚开始学习C时,很多当时想当然的操作竟然在python可以直接实现,字典真好用。硬要说有什么不好,刚开始写python就感觉缩进还是没有大括号{}来的直接好辨认。
- 这次作业明白了软件工程不只是一个写程序的课,它包括很多方面,不是只要写出代码就好,它是一个从最初的设计到后面的测试与优化一个环环相扣的过程。
- 其实很多你第一眼看起来很难的东西,比你想象中的要简单。
- 遇到不会的东西要善于自己百度,网上一般都有解决方案。如果问同学老师,要先想想提问的智慧。
- 这次作业完成的很艰难,但也真的学到了很多!