我总结了以下特征工程的一些方法,好的数据和特征往往在数据挖掘当中会给我们带来更好的acc,尤其对于数据挖掘而言。数据决定了预测准确度的上线,而模型的目的则是去尽量逼近这个上限。由此可见,对数据进行特征工程,拥有良好的数据是多么的重要。
对于特征工程而言,我们一般会对类别型数据或者数值型数据进行相应的编码。下面我们首先来看看对类别型数据进行编码:
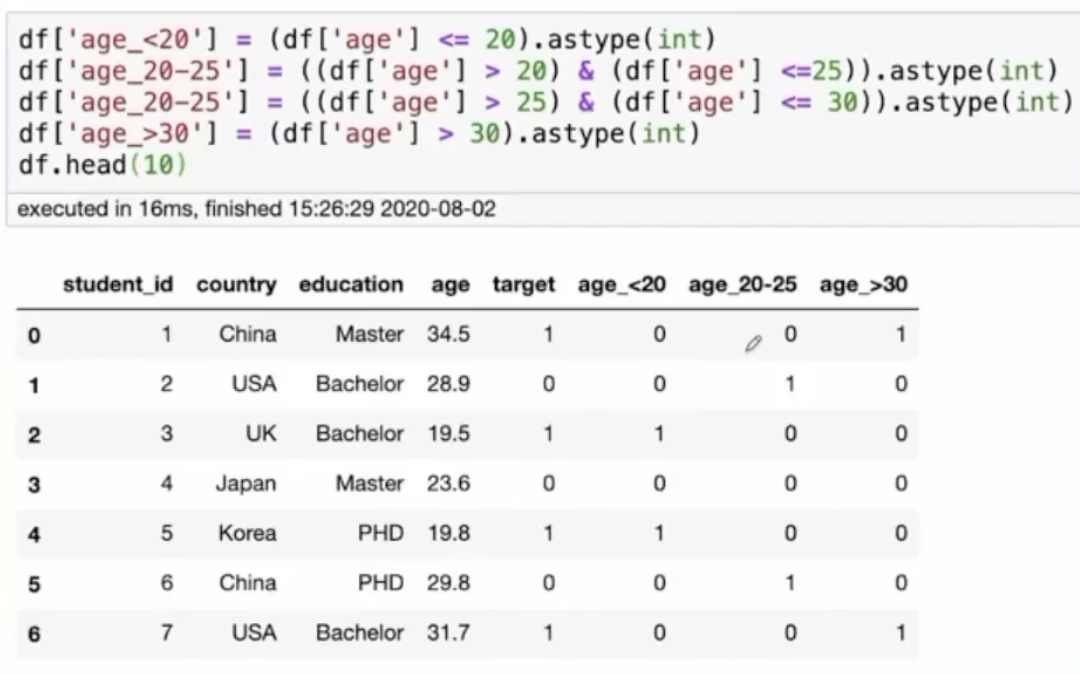
一.one-hot编码
形式:one-hot编码是以one of k的形式。
用途:在所有的线性模型,nlp的词汇也可以用这种方式进行编码,树模型不适合
优点:简单,可以对所有类别型数据进行编码
缺点:会带来维度爆炸(如果属性的类别过多,那么经过one hot处理之后,会产生2^n个新的维度)和特征稀疏(因为会出现很多0)
实现方法:
1.在pandas中使用:get_dummies
2.在sklearn中使用OneHotEncode
如下图所示:
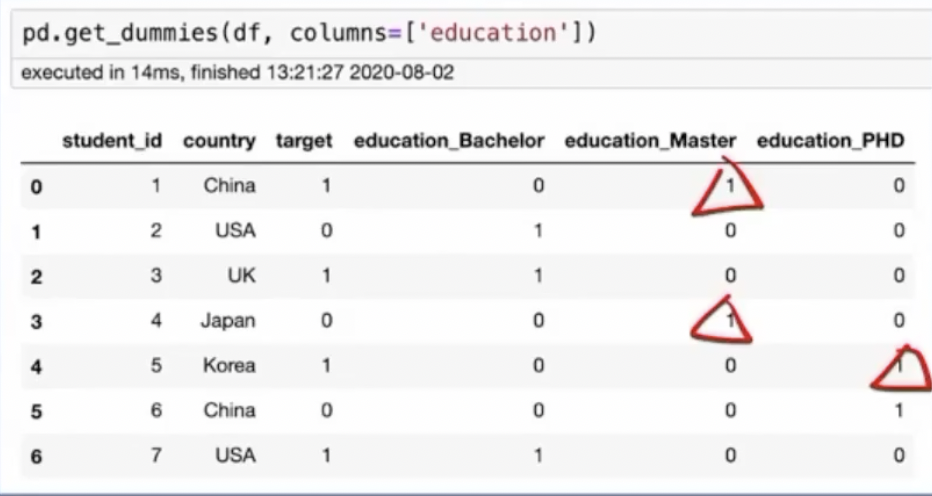
二.Label Encoding 标签编码
形式:将每个类别数据使用独立的数字IDj进行编码
用途:在树模型当中比较适合
优点:简单,不增加类别的维度
缺点:会改变原始标签的类别次序,one-hot不会具有大小关系
实现方法;
sklearn的labelencoder
pandas中的factorize
如下图所示:

在lightbgm和catboost当中会指定类别类型,当然在xgboost/lightbgm的后续版本当总已经不需要使用labelencoder,会自动对已经是数值型的类别数据进行相应的处理
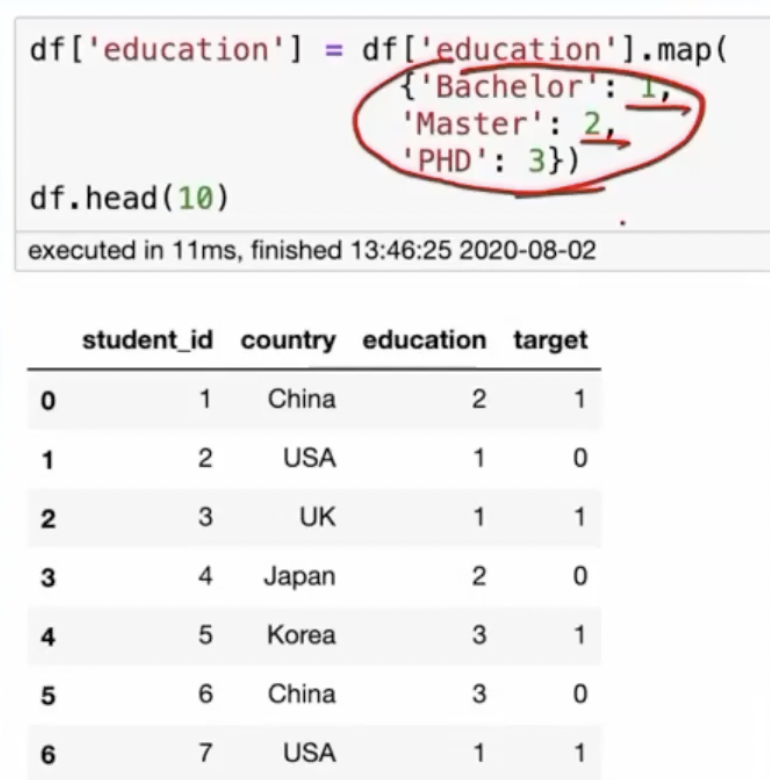
三.顺序编码
形式:按照类别的大小关系进行编码
用途:在大部分场景都适用
优点;简单,不会增加类别的维度
缺点:需要人工知识
实现方法:手动定义字典进行映射
使用代码如下所示:
四.Frequency Encoding, Count Encoding
形式:按照类别出现的次数和频率进行编码(做的优先级低于前面的encoding)
用途:在大部分场景都适用
优点;简单,可以统计类别的次数,从一列的角度进行统计,模型可以学习到频率的信息
缺点:容易收到类别分布带来的影响,比如train 和test的类别分布频率是不一样的,那么对test预测结果可能就没有那么准确,acc不升反降。
实现方法:使用次数进行统计
使用代码如下所示:

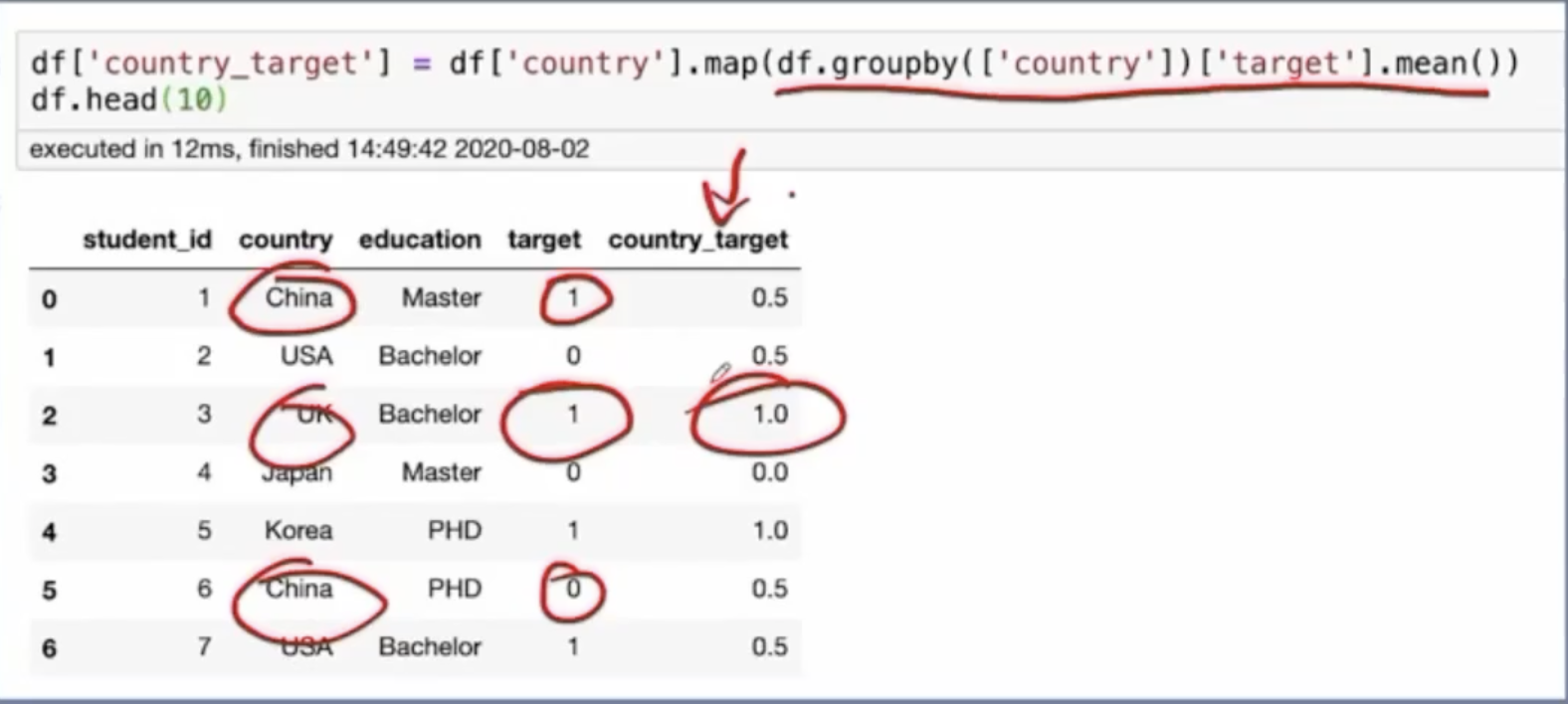
五. Mean/Target Encoding
形式:将类别对应的标签概率进行相应的编码,比如某个country在某个target下出现的概率大小。example:
country为china,target为0或者1,那么概率为0.5 。如果target为0,1,2,则概率为1/3
用途:在大部分场景都适用
优点;让模型能够学习到标签之间相互的一个信息
缺点:容易过拟合,因为比如target只有一个数值,china对应的这一个数值1的概率也永远为1,相当于把country=china这个数值泄漏了出去。造成过拟合
实现方法:使用次数进行统计
下面我们进行数值型数据的特征工程:
一.Round
形式:将数值进行缩放,取整
用途:在大部分场景都适用
优点:可以保留数值的大部分信息
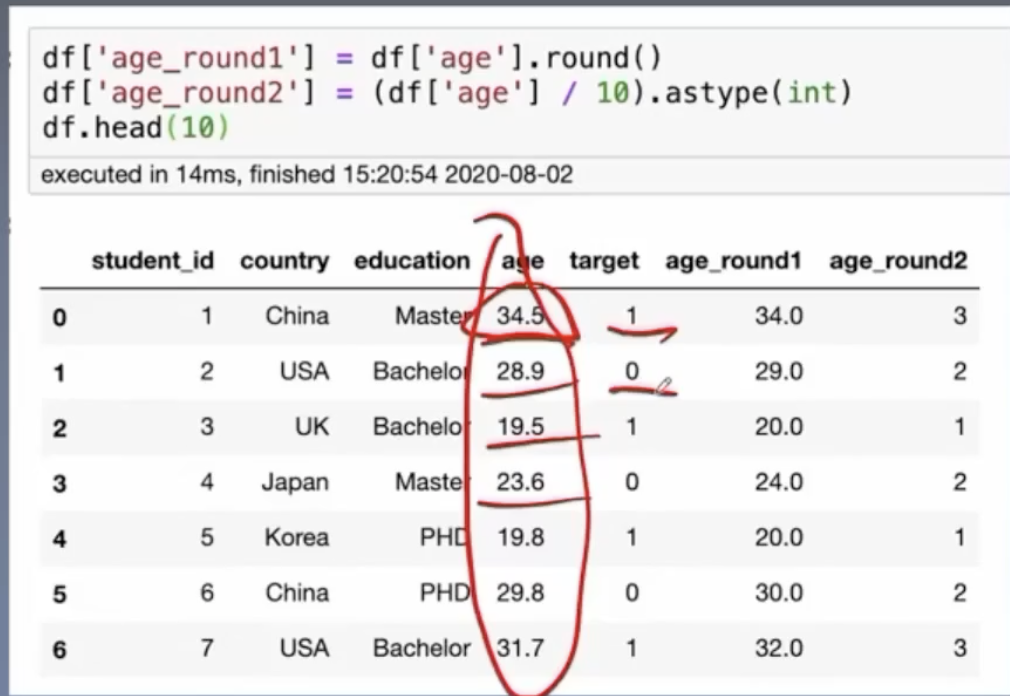
二.数据的分箱
特点:将连续的特征离散化
备注:其实cart回归树(决策树/xgboost/gbdt当中均使用)自动也会帮我们形成一个最优的数据分箱策略,使用的是均方误差来进行的衡量,有的时候可能还比我们手动做数据的分箱更加管用
代码如下所示: