shuffle阶段
概念
shuffle 是 Mapreduce 的核心,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。一般把从 Map 产生输出开始到 Reduce 取得数据作为输入之前的过程称作 shuffle。
一张图看懂Mapreduce全过程

概念解释
- Collect阶段 :将 MapTask 的结果输出到默认大小为 100M 的环形缓冲区,保存的是 key/value,Partition 分区信息等。
- Spill阶段 :当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘, 在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了 combiner,还会将 有相同分区号和 key 的数据进行排序。
- Merge阶段 :把所有溢出的临时文件进行一次合并操作,以确保一个 MapTask 最终只 产生一个中间数据文件。
- Copy阶段 :ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制一份属于 自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值 的时候,就会将数据写到磁盘之上。
- Merge阶段 :在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本 地的数据文件进行合并操作。
- Sort阶段 :在对数据进行合并的同时,会进行排序操作,由于 MapTask 阶段已经对数 据进行了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。 Shule 中的缓冲区大小会影响到 mapreduce 程序的执行效率,原则上说,缓冲区越大, 磁盘io的次数越少,执行速度就越快 缓冲区的大小可以通过参数调整, 参数:mapreduce.task.io.sort.mb 默认100M
共同好友案例
需求分析
以下是qq的好友列表数据,冒号前是一个用户,冒号后是该用户的所有好友(数据中的好友 关系是单向的)

求出哪些人两两之间有共同好友,及他俩的共同好友都有谁?
过程分析
mapreduce最重要的是根据自己的项目确定 K2和V2的类型,此案例中要用俩个mapreduce实现,将第一个mapreduce的输出作为第二个mapreduce的输入,第一个mapreduce要实现A-O分别是谁的好友,例如:A-E B;A-C-E D B是A和E 的好友,D是A,C和E的好友。我们求的是俩俩之间的好友,要把A-C-E拆分成A-C A-E C-E;第二个阶段实现共同好友的求取。
一个图看懂实现过程

代码实现
第一个mapper
1 package Commond_friends; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 7 import java.io.IOException; 8 9 // K1行偏移量没有意义 ,V1是每行的内容 10 public class FirstMapper extends Mapper<LongWritable, Text,Text,Text> { 11 @Override 12 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 13 //1:以冒号拆分行文本数据: 冒号左边就是V2 14 String[] split = value.toString().split(":"); 15 String userStr = split[0]; 16 //2:将冒号右边的字符串以逗号拆分,每个成员就是K2 17 String[] split1 = split[1].split(","); 18 for (String s : split1) { 19 //3:将K2和v2写入上下文中 20 context.write(new Text(s),new Text(userStr)); 21 } 22 } 23 }
第一个reduce
1 package Commond_friends; 2 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 import java.io.IOException; 7 8 public class FirstReduce extends Reducer<Text,Text,Text,Text> { 9 @Override 10 protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 11 //1:遍历集合,并将每一个元素拼接,得到K3 12 StringBuffer buffer = new StringBuffer(); 13 for (Text value : values) { 14 buffer.append(value.toString()+"-"); 15 } 16 //2:K2就是V3 17 //3:将K3和V3写入上下文中 18 context.write(new Text(buffer.toString().substring(0,buffer.length()-1)),key); 19 } 20 }
第一个jabmain
1 package Commond_friends; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.conf.Configured; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 10 import org.apache.hadoop.util.Tool; 11 import org.apache.hadoop.util.ToolRunner; 12 13 public class jobMain extends Configured implements Tool { 14 @Override 15 public int run(String[] strings) throws Exception { 16 //1:获取Job对象 17 Job job = Job.getInstance(super.getConf(), "common_friends_step1_job"); 18 19 //2:设置job任务 20 //第一步:设置输入类和输入路径 21 job.setInputFormatClass(TextInputFormat.class); 22 TextInputFormat.addInputPath(job, new Path("file:///D:\learnpath\Bigdata\project\Mapreduce\input\input.txt")); 23 24 //第二步:设置Mapper类和数据类型 25 job.setMapperClass(FirstMapper.class); 26 job.setMapOutputKeyClass(Text.class); 27 job.setMapOutputValueClass(Text.class); 28 29 //第三,四,五,六 30 31 //第七步:设置Reducer类和数据类型 32 job.setReducerClass(FirstReduce.class); 33 job.setOutputKeyClass(Text.class); 34 job.setOutputValueClass(Text.class); 35 36 //第八步:设置输出类和输出的路径 37 job.setOutputFormatClass(TextOutputFormat.class); 38 TextOutputFormat.setOutputPath(job, new Path("file:///D:\learnpath\Bigdata\project\Mapreduce\input\input2")); 39 40 //3:等待job任务结束 41 boolean bl = job.waitForCompletion(true); 42 43 44 45 return bl ? 0: 1; 46 } 47 48 public static void main(String[] args) throws Exception { 49 Configuration configuration = new Configuration(); 50 //启动job任务 51 int run = ToolRunner.run(configuration, new jobMain(), args); 52 System.exit(run); 53 } 54 55 }
第二个mapper
1 package common_friends_step2; 2 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 7 import java.io.IOException; 8 import java.util.Arrays; 9 10 public class scendMapper extends Mapper<LongWritable, Text,Text,Text> { 11 /* 12 K1 V1 13 0 A-F-C-J-E- B 14 ---------------------------------- 15 K2 V2 16 A-C B 17 A-E B 18 A-F B 19 C-E B 20 */ 21 22 @Override 23 protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { 24 //1:拆分行文本数据,结果的第二部分可以得到V2 25 String[] split = value.toString().split(" "); 26 String friend = split[1]; 27 28 //2:继续以'-'为分隔符拆分行文本数据第一部分,得到数组 29 String[] userStr = split[0].split("-"); 30 Arrays.sort(userStr); 31 //4:对数组中的元素进行两两组合,得到K2 32 /* 33 A-E-C -----> A C E 34 A C E 35 A C E 36 */ 37 for(int i=0;i<userStr.length-1;i++) 38 { 39 for(int j=i+1;j<userStr.length;j++) 40 { 41 context.write(new Text(userStr[i]+"-"+userStr[j]),new Text(friend)); 42 } 43 } 44 45 46 } 47 }
第二个reduce
1 package common_friends_step2; 2 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 import java.io.IOException; 7 8 public class secondReduce extends Reducer<Text,Text,Text,Text> { 9 @Override 10 protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 11 StringBuffer stringBuffer = new StringBuffer(); 12 for (Text value : values) { 13 stringBuffer.append(value.toString()).append("-"); 14 } 15 context.write(key,new Text(stringBuffer.toString().substring(0,stringBuffer.length()-1))); 16 } 17 }
第二个jobmain
1 package common_friends_step2; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.conf.Configured; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; 10 import org.apache.hadoop.util.Tool; 11 import org.apache.hadoop.util.ToolRunner; 12 13 public class jobMain extends Configured implements Tool { 14 @Override 15 public int run(String[] strings) throws Exception { 16 //1:获取Job对象 17 Job job = Job.getInstance(super.getConf(), "common_friends_step2_job"); 18 19 //2:设置job任务 20 //第一步:设置输入类和输入路径 21 job.setInputFormatClass(TextInputFormat.class); 22 TextInputFormat.addInputPath(job, new Path("file:///D:\learnpath\Bigdata\project\Mapreduce\input\input2")); 23 24 //第二步:设置Mapper类和数据类型 25 job.setMapperClass(scendMapper.class); 26 job.setMapOutputKeyClass(Text.class); 27 job.setMapOutputValueClass(Text.class); 28 29 //第三,四,五,六 30 31 //第七步:设置Reducer类和数据类型 32 job.setReducerClass(secondReduce.class); 33 job.setOutputKeyClass(Text.class); 34 job.setOutputValueClass(Text.class); 35 36 //第八步:设置输出类和输出的路径 37 job.setOutputFormatClass(TextOutputFormat.class); 38 TextOutputFormat.setOutputPath(job, new Path("file:///D:\learnpath\Bigdata\project\Mapreduce\out")); 39 40 //3:等待job任务结束 41 boolean bl = job.waitForCompletion(true); 42 43 44 45 return bl ? 0: 1; 46 } 47 48 public static void main(String[] args) throws Exception { 49 Configuration configuration = new Configuration(); 50 51 //启动job任务 52 int run = ToolRunner.run(configuration, new jobMain(), args); 53 54 System.exit(run); 55 } 56 }
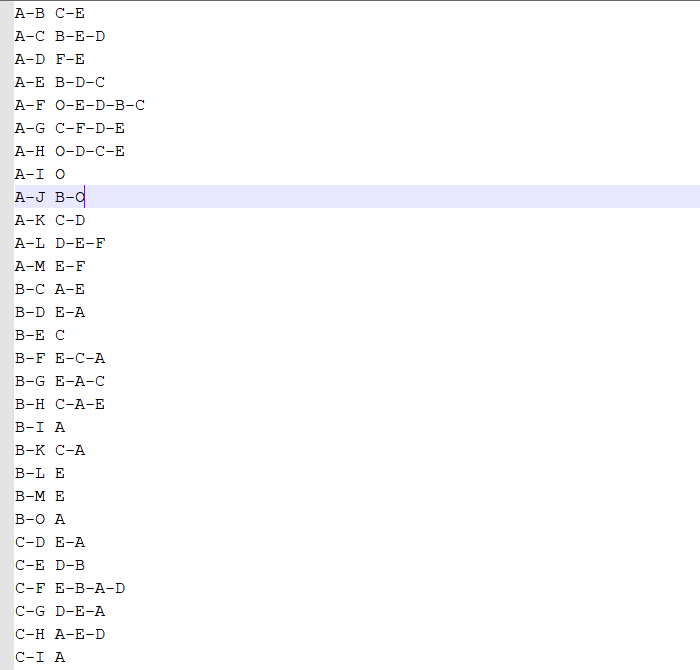
运行截图
初始文件表示一个用户的好友列表

结果文件
示例:A-B C-E 表示A和B 的共同好友有C和E