There are many things that impact database performance. The most obvious is the amount of data: the more you have, the slower your database will be. While there are many ways to fix performance problems (like removing old data or using denormalization反规范化), the primary solution is to properly index your database.
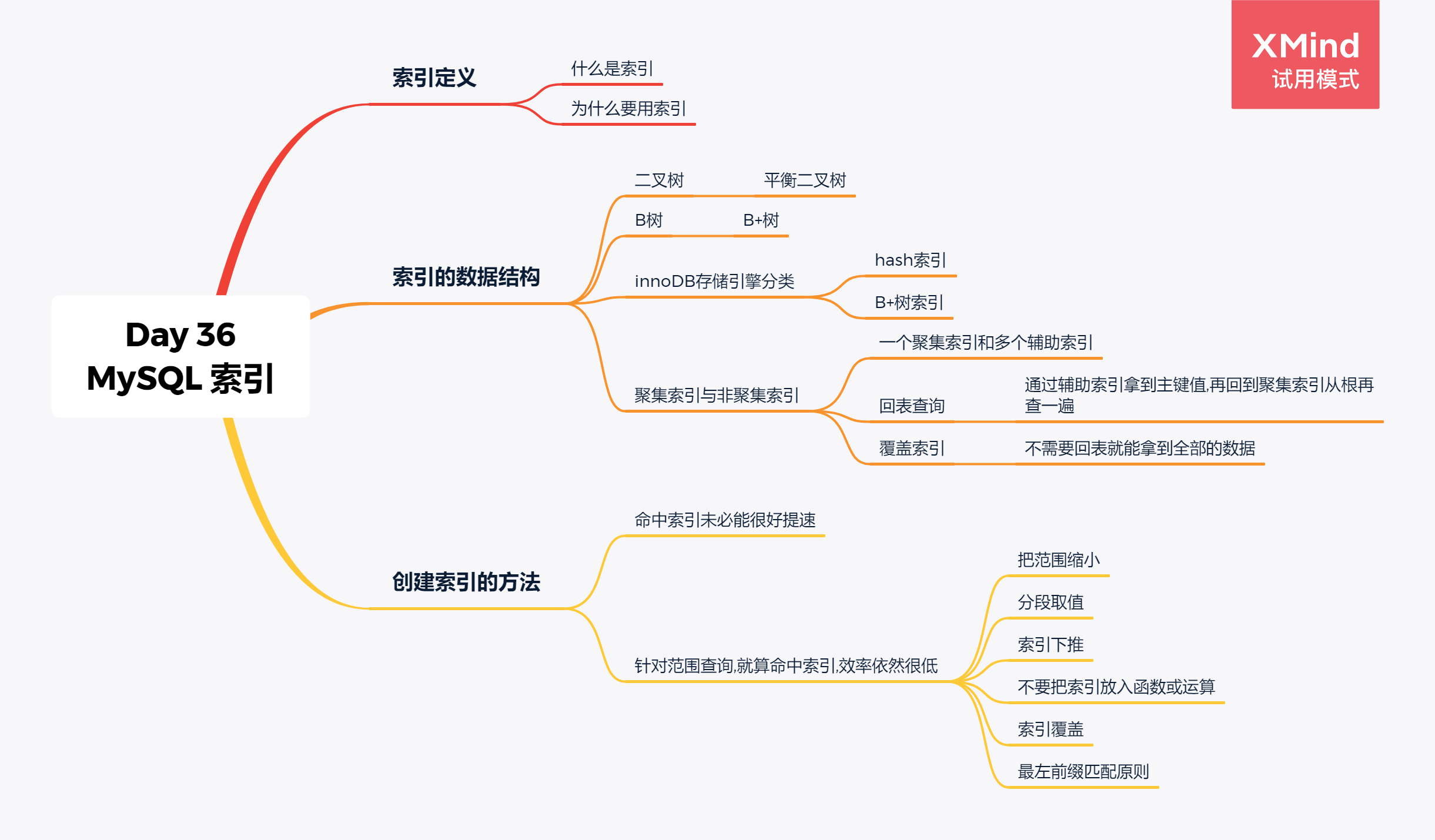
What Is a Database Index?
A database index is a specialized data structure that allows us to locate information quickly. It’s organized like a binary tree structure, with smaller values to the left and larger values to the right. Rather than force a scan of the entire table, an index can compare row values in the tree-like structure to locate desired data faster.
When we create an index on one or more columns, we store their values in a new structure. We also store pointers to rows the values come from. This organizes and sorts the information, but it doesn’t change the information itself. Think of a database index as the digital equivalent to the index in the back of a book. While it stores some actual information, it also includes pointers to the locations where more details can be found.
After the data is sorted by our search criteria标准, locating the desired records becomes much simpler. Picture an old telephone book that was sorted alphabetically. Knowing someone’s last name, first name, and address meant you could find their telephone number very quickly. But what if you only knew someone’s address and first name? Without the last name, finding the phone number would be quite difficult. You’d do much better with a reverse telephone directory, which lists phone numbers based on addresses.
In databases, changing your search criteria often means creating a new index for a combination of attributes. As mentioned, adding these indexes would require additional disk space. When we add, delete or update values, changes are also made to the indexes.
What Structures Do Indexes Use?
Database indexes speed up data retrieval /rɪˈtriːvl/检索 operations. But there is a price we pay for these benefits.
MySQL supports a few different index types. The most important are BTREE and HASH. These types are also the most common types in other DBMSs.
Before we start describing index types, let’s have a quick review of the most common node types:
-
Root node – the topmost node in the tree structure
-
Child nodes – nodes that another node (the parent node) points to
-
Parent nodes – nodes that point to other nodes (child nodes)
-
Leaf nodes – nodes that have no child nodes (located on the bottom of the tree structure)
-
Internal nodes – all “non-leaf” nodes, including the root node
-
External nodes – another name for leaf nodes
Binary Search Trees
Now let’s consider the binary search tree (BST) structure. These structures are not database indexes, but it’s good to understand how they work. You’ll soon see that the tree-structures (B-Tree and B+Tree) used by databases are similar.
A BST is a binary tree in which the nodes are sorted. In the picture above, we see that the values on the left of node X are smaller than X, and the values on the right of node X are greater. This is how any BST is organized.
When we search for a value in the BST, we start from the root node and compare the searched value with the value of the root node. If the searched value is lower than the root value, we’ll go to the left subtree. If it’s higher, then we go to the right subtree. If we find the value, we’re done. If we reach the leaf node without finding our value, we know that it’s not in our tree.
Adding a new value to the BST starts just like searching for a value. (Once we find the right place for our value, of course, the process changes.) For example, if we want to add the value “30”, we would add it as a left child node of the node “31” (30 is greater than 27, so we go right; 30 is less than 35, so we go left; 30 is less than 31, so we go left again.)
When we want to delete a value from the BST, the situation is more complicated. We may even need to rearrange the tree in some cases. There are three possible situations:
-
Deleting a node that has no child nodes – We’ll simply remove the node from the BST. In our example, these are the nodes“10”, “19”, “31” and “42”.
-
Deleting a node that has one child node – We’ll replace the deleted node with the child node. If node “31” has “30” as a child node in the left subtree and we delete it, we’ll simply replace “31” with “30”.
-
Deleting a node that has two child nodes – This is the most complex case. In this situation, we’ll find the smallest element in the right subtree of the deleted node and put it in place of the deleted node. So if we delete node “27”, we’ll look for the minimum value in the right subtree and that is “31”. We’ll replace the node “27” with the node “31”.
B-Trees
The *B-Tree* is the basic index structure for most MySQL storage engines. Each node in a B-Tree has between d and 2d values. Values in each node are sorted. Each node has between 0 to 2d+1 child nodes. Each child node is attached before, after, or between values. (In the above graphic, values “9” and “12” come between values “7” and “16”.)
The values in B-Tree are sorted in a similar way to those in a binary search tree. Child nodes to the left of value “X” have values smaller than X; child nodes to the right of the value “X” have values greater than X (see the picture).
In contrast to a BST, a B-Tree is a balanced tree: all branches of the tree have the same length.
Searching for values in a B-Tree also corresponds to searching in a BST. First we check if the value is present in the root node. If it isn’t, we select the appropriate child node, and look for the value in that node.
Adding and removing values from a B-tree usually does not create new nodes: the number of values in each node can vary. Of course, that means we’ll have some empty space, so a B-tree will require more disk space than a denser tree would.
Adding a value has to maintain both the order of value and the balance of the tree. First we’ll find the leaf node where the values should be added. If there is enough space in the leaf node, we’ll simply add the value; the structure and the tree depth won’t change.
In our example, adding the value “22” would be extremely simple. We would simply add it to the third leaf node. If we want to add the value “4”, we would split the first leaf node. This always happens in a case of overflow. Values “1” and “2” would form a new leaf node (the left one); value “4” would be the middle node (and inserted into the parent node), while values “5” and “6” would form another new leaf node (the right one).
We would split the parent node in the same manner if an overflow happens there. In extreme cases, we’d have to split the root node and the tree depth would increase.
When we want to delete a value from the B-Tree, we’ll locate that value and remove it. If that deletion caused underflow (the number of values stored in a node is too low) we’ll have to merge nodes together. This is exactly the opposite from what happens when we’re adding values. We’ll merge that node with the neighboring node that contains the most values. If the newly merged node contains too many values (overflow) we’ll split it to the left, middle, and right and rearrange the tree structure.
When B-Tree is used in database index, each node holds the index value and the pointer to the row it comes from. For example, if the index is on the column id, then the tree will hold both the value "7" and a pointer to the row where id=7. When we search for the row where id=7, we can quickly find the value 7 in the B-Tree and then follow the pointer to get the actual row
.
The important thing to remember is that in the B-tree structure each node contains key values, pointers to the values, and pointers to child nodes with smaller and larger values than the value in the parent node. Of course, leaf nodes don’t point to any child nodes.
With a B-Tree index, we can use equality operators (= or <=>), operators that will result in a range (>, <, >=, <=, BETWEEN), and the LIKE operator.
We can create an index on more than one column, too. If we created an index on a (first_name, last_name) pair, we could search using either term, but the index will also work when we’re using just one of these attributes.
Finally, it’s good to note that the B-tree will perform better when the data accessed most frequently lies closer to the root node.
B+Tree
The *B+Tree* structure is similar to the B-Tree structure. The most important differences are:
-
The internal nodes only store values; they don’t store pointers to actual rows. The leaf nodes store the values and row pointers. This reduces the internal nodes’ size, allowing the storage of more nodes on the same memory page. In turn, this increases the branching factor. As the branching factor grows, the height of the tree decreases and that results in fewer disk I/O operations.
-
Leaf nodes in the B+Tree are linked, so we can conduct a full scan with only one pass. That is very helpful when we need to find all the data in a given range. Because row pointers are stored in both internal and leaf nodes, this isn’t possible in a B-Tree.
-
Performing delete operations in a B+tree structure is much easier than in a B-tree. This is because we don’t need to remove values from the internal nodes. In a B+Tree structure, we’ll have the same value repeated; in a B-Tree structure, each value is unique. In B+Tree, we’ll store one value and one data pointer in the leaf node, but that value could also be stored in internal nodes (where it’s used to point to child nodes).
-
The advantage of B-Tree is that we can find values that lie close to the root fairly quickly, while in B+Tree we would need to look all the way down to the leaf nodes for any value.
The InnoDB storage engine uses a B+Tree structure to store indexes.
Hash Indexes
Hash indexes are directly related to the hashing technique. Look at the picture above. On the left side, we see the set of key values used to find data. In this case, they are numeric values. The hash function is used to calculate the address where the actual data bucket is stored. That will give us the location of records related to each key value.
Values are stored in buckets based on the value of a hash function. When we want to search for a value, we’ll use the hash function to calculate the address where our data could be stored. We’ll look for the data in the bucket. If we find it, we’re done. If we don’t find our value, it means it’s not in the index.
Adding new values works similarly: we’ll use the hash function to calculate the address where we’ll store our data. If that address is already occupied, we’ll add new buckets and re-compute the hash function. Once again, we’ll use the whole key as an input for our function. The result is the actual address (in disk memory) where we can find the desired data.
Updating or deleting values consists of first searching for a value and then applying the desired operation on that memory address.
Hash table indexes are very fast when testing for equality (= or <=>). This is because we’re using the whole key and not just its parts. Individual parts can’t help us when we want to find range, use the < or > operators, or speed up the ORDER BY part of the clause.
Tips for Improving Your Indexing
Avoid duplication.
Duplication takes up more disk space, and for no good reason. Set parameters on your indexing to make sure you don’t have multiple indexes for the same query — it not only takes up more space, but it can also slow down your environment.
Use the right type of index.
B-trees are the most commonly used for index, due to the fact that they are the most efficient. However, in certain cases, other types of indexes may be more useful for your MySQL database, like a hash table index (best for searching values) or an R-tree data structure (recommended for spatial searches).
Review your indexes regularly.
What are the most common queries on your database? Do you have indexes for these? See how they are being leveraged and make sure you have the right ones in place to make sure you are getting the best bang for your buck.
How to Monitor MySQL Indexing