第1部分 Hashtable介绍
Hashtable 简介
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
此类实现一个哈希表,该哈希表将键映射到相应的值。任何非 null 对象都可以用作键或值。
为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。
注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。
加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。
关于何时以及是否调用 rehash
方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,
但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)。
Hashtable的构造函数
1.默认构造函数,容量为11,加载因子为0.75。
public Hashtable() { this(11, 0.75f); }
2.用指定初始容量和默认的加载因子 (0.75) 构造一个新的空哈希表。
public Hashtable(int initialCapacity) { this(initialCapacity, 0.75f); }
3.用指定初始容量和指定加载因子构造一个新的空哈希表。
public Hashtable(int initialCapacity, float loadFactor) { //验证初始容量 if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); //验证加载因子 if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0) initialCapacity = 1; this.loadFactor = loadFactor; //初始化table,获得大小为initialCapacity的table数组 table = new Entry[initialCapacity]; //计算阀值 threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1); //初始化HashSeed值 initHashSeedAsNeeded(initialCapacity); }
其中initHashSeedAsNeeded方法用于初始化hashSeed参数,其中hashSeed用于计算key的hash值,它与key的hashCode进行按位异或运算。
这个hashSeed是一个与实例相关的随机值,主要用于解决hash冲突。
private int hash(Object k) { // hashSeed will be zero if alternative hashing is disabled. return hashSeed ^ k.hashCode(); }
4.构造一个与给定的 Map 具有相同映射关系的新哈希表。
public Hashtable(Map<? extends K, ? extends V> t) { //设置table容器大小,其值==t.size * 2 + 1 this(Math.max(2*t.size(), 11), 0.75f); putAll(t); }
Hashtable的API
void clear() 将此哈希表清空,使其不包含任何键。 Object clone() 创建此哈希表的浅表副本。 boolean contains(Object value) 测试此映射表中是否存在与指定值关联的键。 boolean containsKey(Object key) 测试指定对象是否为此哈希表中的键。 boolean containsValue(Object value) 如果此 Hashtable 将一个或多个键映射到此值,则返回 true。 Enumeration<V> elements() 返回此哈希表中的值的枚举。 Set<Map.Entry<K,V>> entrySet() 返回此映射中包含的键的 Set 视图。 boolean equals(Object o) 按照 Map 接口的定义,比较指定 Object 与此 Map 是否相等。 V get(Object key) 返回指定键所映射到的值,如果此映射不包含此键的映射,则返回 null. 更确切地讲,如果此映射包含满足 (key.equals(k)) 的从键 k 到值 v 的映射,则此方法返回 v;否则,返回 null。 int hashCode() 按照 Map 接口的定义,返回此 Map 的哈希码值。 boolean isEmpty() 测试此哈希表是否没有键映射到值。 Enumeration<K> keys() 返回此哈希表中的键的枚举。 Set<K> keySet() 返回此映射中包含的键的 Set 视图。 V put(K key, V value) 将指定 key 映射到此哈希表中的指定 value。 void putAll(Map<? extends K,? extends V> t) 将指定映射的所有映射关系复制到此哈希表中,这些映射关系将替换此哈希表拥有的、针对当前指定映射中所有键的所有映射关系。 protected void rehash() 增加此哈希表的容量并在内部对其进行重组,以便更有效地容纳和访问其元素。 V remove(Object key) 从哈希表中移除该键及其相应的值。 int size() 返回此哈希表中的键的数量。 String toString() 返回此 Hashtable 对象的字符串表示形式,其形式为 ASCII 字符 ", " (逗号加空格)分隔开的、括在括号中的一组条目。 Collection<V> values() 返回此映射中包含的键的 Collection 视图。
第2部分 Hashtable数据结构
Hashtable的继承关系
java.lang.Object ↳ java.util.Dictionary<K, V> ↳ java.util.Hashtable<K, V> public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable { }
Hashtable与Map关系如下图:

从图中可以看出:
(01) Hashtable继承于Dictionary类,实现了Map接口。Map是"key-value键值对"接口,Dictionary是声明了操作"键值对"函数接口的抽象类。
(02) Hashtable是通过"拉链法"实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的"key-value键值对"都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值="容量*加载因子"。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
第3部分 Hashtable主要方法
HashTable的API对外提供了许多方法,这些方法能够很好帮助我们操作HashTable,
首先我们先看put方法:将指定 key 映射到此哈希表中的指定 value。注意这里键key和值value都不可为空。
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } /* * 确保key在table[]是不重复的 * 处理过程: * 1、计算key的hash值,确认在table[]中的索引位置 * 2、迭代index索引位置,如果该位置处的链表中存在一个一样的key,则替换其value,返回旧值 */ Entry tab[] = table; //计算key的hash值 int hash = hash(key); //确认该key的索引位置 int index = (hash & 0x7FFFFFFF) % tab.length; //迭代,寻找该key,替换 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; //如果容器中的元素数量已经达到阀值,则进行扩容操作 if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; hash = hash(key); index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<>(hash, key, value, e); count++; return null; }
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表(我们暂且理解为链表),
若该链表中存在一个这个的key对象,那么就直接替换其value值即可,否则在将改key-value节点插入该index索引位置处。如下:
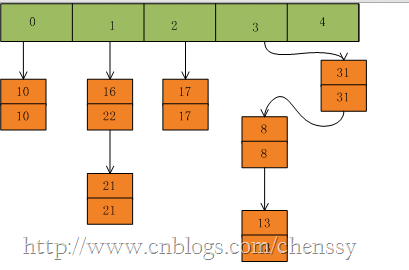
首先我们假设一个容量为5的table,存在8、10、13、16、17、21。他们在table中位置如下:

然后我们插入一个数:put(16,22),key=16在table的索引位置为1,同时在1索引位置有两个数,程序对该“链表”进行迭代,
发现存在一个key=16,这时要做的工作就是用newValue=22替换oldValue16,并将oldValue=16返回。

在put(31,31),key=31所在的索引位置为3,并且在该链表中也没有存在某个key=31的节点,所以就将该节点插入该链表的第一个位置。
在HashTabled的put方法中有两个地方需要注意:
1、HashTable的扩容操作,在put方法中,如果需要向table[]中添加Entry元素,会首先进行容量校验,如果容量已经达到了阀值,HashTable就会进行扩容处理rehash(),如下:
protected void rehash() { int oldCapacity = table.length; Entry<K,V>[] oldMap = table; // overflow-conscious code int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) // Keep running with MAX_ARRAY_SIZE buckets return; newCapacity = MAX_ARRAY_SIZE; } //新建一个size = newCapacity 的HashTable Entry<K,V>[] newMap = new Entry[newCapacity]; modCount++; //重新计算阀值 threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); //重新计算hashSeed boolean rehash = initHashSeedAsNeeded(newCapacity); table = newMap; //将原来的元素拷贝到新的HashTable中 for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; if (rehash) { e.hash = hash(e.key); } int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = newMap[index]; newMap[index] = e; } } }
在这个rehash()方法中我们可以看到容量扩大两倍+1,同时需要将原来HashTable中的元素一一复制到新的HashTable中,这个过程是比较消耗时间的,
同时还需要重新计算hashSeed的,毕竟容量已经变了。这里对阀值啰嗦一下:比如初始值11、加载因子默认0.75,那么这个时候阀值threshold=8,
当容器中的元素达到8时,HashTable进行一次扩容操作,容量 = 8 * 2 + 1 =17,而阀值threshold=17*0.75 = 13,
当容器元素再一次达到阀值时,HashTable还会进行扩容操作,以此类推。
2、其实这里是我的一个疑问,在计算索引位置index时,HashTable进行了一个与运算过程(hash & 0x7FFFFFFF),
至于为什么要与 0x7FFFFFFF, 那是hashtable 提供的hash算法, hashMap提供了不同的算法, 用户如果要定义自己的算法也是可以的.
下面是计算key的hash值,这里hashSeed发挥了作用。
private int hash(Object k) { return hashSeed ^ k.hashCode(); }
相对于put方法,get方法就会比较简单,处理过程就是计算key的hash值,判断在table数组中的索引位置,然后迭代链表,匹配直到找到相对应key的value,若没有找到返回null。
public synchronized V get(Object key) { Entry tab[] = table; int hash = hash(key); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }
putAll() 的作用是将“Map(t)”的中全部元素逐一添加到Hashtable中
public synchronized void putAll(Map<? extends K, ? extends V> t) { for (Map.Entry<? extends K, ? extends V> e : t.entrySet()) put(e.getKey(), e.getValue()); }
clear() 的作用是清空Hashtable。它是将Hashtable的table数组的值全部设为null
public synchronized void clear() { Entry tab[] = table; modCount++; for (int index = tab.length; --index >= 0; ) tab[index] = null; count = 0; }
3.5 contains() 和 containsValue()
contains() 和 containsValue() 的作用都是判断Hashtable是否包含“值(value)”
public synchronized boolean contains(Object value) { if (value == null) { throw new NullPointerException(); } Entry tab[] = table; for (int i = tab.length ; i-- > 0 ;) { for (Entry<K,V> e = tab[i] ; e != null ; e = e.next) { if (e.value.equals(value)) { return true; } } } return false; }
public boolean containsValue(Object value) { return contains(value); }
containsKey() 的作用是判断Hashtable是否包含key
public synchronized boolean containsKey(Object key) { Entry tab[] = table; int hash = hash(key); // 计算索引值,% tab.length 的目的是防止数据越界 int index = (hash & 0x7FFFFFFF) % tab.length; // 找到“key对应的Entry(链表)”,然后在链表中找出“哈希值”和“键值”与key都相等的元素 for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return true; } } return false; }
elements() 的作用是返回“所有value”的枚举对象
public synchronized Enumeration<V> elements() { return this.<V>getEnumeration(VALUES); } // 获取Hashtable的枚举类对象 private <T> Enumeration<T> getEnumeration(int type) { if (count == 0) { return Collections.emptyEnumeration(); } else { return new Enumerator<>(type, false); } }
从中,我们可以看出:
(01) 若Hashtable的实际大小为0,则返回“空枚举类”对象emptyEnumerator;
(02) 否则,返回正常的Enumerator的对象。(Enumerator实现了迭代器和枚举两个接口)
先看看emptyEnumerator对象是如何实现的:
public static <T> Enumeration<T> emptyEnumeration() { return (Enumeration<T>) EmptyEnumeration.EMPTY_ENUMERATION; } private static class EmptyEnumeration<E> implements Enumeration<E> { static final EmptyEnumeration<Object> EMPTY_ENUMERATION = new EmptyEnumeration<>(); // 空枚举类的hasMoreElements() 始终返回false public boolean hasMoreElements() { return false; } // 空枚举类的nextElement() 抛出异常 public E nextElement() { throw new NoSuchElementException(); } }
我们在来看看Enumeration类
Enumerator的作用是提供了“通过elements()遍历Hashtable的接口” 和 “通过entrySet()遍历Hashtable的接口”。
因为,它同时实现了 “Enumerator接口”和“Iterator接口”。
private class Enumerator<T> implements Enumeration<T>, Iterator<T> { Entry[] table = Hashtable.this.table; int index = table.length; Entry<K,V> entry = null; Entry<K,V> lastReturned = null; int type; /** * Indicates whether this Enumerator is serving as an Iterator * or an Enumeration. (true -> Iterator). */ boolean iterator; // 在将Enumerator当作迭代器使用时会用到,用来实现fail-fast机制。 protected int expectedModCount = modCount; Enumerator(int type, boolean iterator) { this.type = type; this.iterator = iterator; } // 从遍历table的数组的末尾向前查找,直到找到不为null的Entry。 public boolean hasMoreElements() { Entry<K,V> e = entry; int i = index; Entry[] t = table; /* Use locals for faster loop iteration */ while (e == null && i > 0) { e = t[--i]; } entry = e; index = i; return e != null; } //从hasMoreElements() 和nextElement() 可以看出“Hashtable的elements()遍历方式” // 首先,从后向前的遍历table数组。table数组的每个节点都是一个单向链表(Entry)。 // 然后,依次向后遍历单向链表Entry。 public T nextElement() { Entry<K,V> et = entry; int i = index; Entry[] t = table; /* Use locals for faster loop iteration */ while (et == null && i > 0) { et = t[--i]; } entry = et; index = i; if (et != null) { Entry<K,V> e = lastReturned = entry; entry = e.next; return type == KEYS ? (T)e.key : (type == VALUES ? (T)e.value : (T)e); } throw new NoSuchElementException("Hashtable Enumerator"); } // Iterator methods // 迭代器Iterator的判断是否存在下一个元素,实际上,它是调用的hasMoreElements() public boolean hasNext() { return hasMoreElements(); } public T next() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); return nextElement(); } //首先,它在table数组中找出要删除元素所在的Entry,然后,删除单向链表Entry中的元素。 public void remove() { if (!iterator) throw new UnsupportedOperationException(); if (lastReturned == null) throw new IllegalStateException("Hashtable Enumerator"); if (modCount != expectedModCount) throw new ConcurrentModificationException(); synchronized(Hashtable.this) { Entry[] tab = Hashtable.this.table; int index = (lastReturned.hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index], prev = null; e != null; prev = e, e = e.next) { if (e == lastReturned) { modCount++; expectedModCount++; if (prev == null) tab[index] = e.next; else prev.next = e.next; count--; lastReturned = null; return; } } throw new ConcurrentModificationException(); } } }
remove() 的作用就是删除Hashtable中键为key的元素
public synchronized V remove(Object key) { Entry tab[] = table; int hash = hash(key); int index = (hash & 0x7FFFFFFF) % tab.length; // 找到“key对应的Entry(链表)”,然后在链表中找出要删除的节点,并删除该节点。 for (Entry<K,V> e = tab[index], prev = null ; e != null ; prev = e, e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { modCount++; if (prev != null) { prev.next = e.next; } else { tab[index] = e.next; } count--; V oldValue = e.value; e.value = null; return oldValue; } } return null; }
第4部分 Hashtable实现的Cloneable接口
Hashtable实现了Cloneable接口,即实现了clone()方法。
clone()方法的作用很简单,就是克隆一个Hashtable对象并返回。
public synchronized Object clone() { try { Hashtable<K,V> t = (Hashtable<K,V>) super.clone(); t.table = new Entry[table.length]; for (int i = table.length ; i-- > 0 ; ) { t.table[i] = (table[i] != null) ? (Entry<K,V>) table[i].clone() : null; } t.keySet = null; t.entrySet = null; t.values = null; t.modCount = 0; return t; } catch (CloneNotSupportedException e) { // this shouldn't happen, since we are Cloneable throw new InternalError(); } }
第5部分 Hashtable实现的Serializable接口
Hashtable实现java.io.Serializable,分别实现了串行读取、写入功能。
串行写入函数就是将Hashtable的“总的容量,实际容量,所有的Entry”都写入到输出流中
串行读取函数:根据写入方式读出将Hashtable的“总的容量,实际容量,所有的Entry”依次读出
/** * Save the state of the Hashtable to a stream (i.e., serialize it). * * @serialData The <i>capacity</i> of the Hashtable (the length of the * bucket array) is emitted (int), followed by the * <i>size</i> of the Hashtable (the number of key-value * mappings), followed by the key (Object) and value (Object) * for each key-value mapping represented by the Hashtable * The key-value mappings are emitted in no particular order. */ private void writeObject(java.io.ObjectOutputStream s) throws IOException { Entry<K, V> entryStack = null; synchronized (this) { // Write out the length, threshold, loadfactor s.defaultWriteObject(); // Write out length, count of elements s.writeInt(table.length); s.writeInt(count); // Stack copies of the entries in the table for (int index = 0; index < table.length; index++) { Entry<K,V> entry = table[index]; while (entry != null) { entryStack = new Entry<>(0, entry.key, entry.value, entryStack); entry = entry.next; } } } // Write out the key/value objects from the stacked entries while (entryStack != null) { s.writeObject(entryStack.key); s.writeObject(entryStack.value); entryStack = entryStack.next; } } /** * Reconstitute the Hashtable from a stream (i.e., deserialize it). */ private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException { // Read in the length, threshold, and loadfactor s.defaultReadObject(); // Read the original length of the array and number of elements int origlength = s.readInt(); int elements = s.readInt(); // Compute new size with a bit of room 5% to grow but // no larger than the original size. Make the length // odd if it's large enough, this helps distribute the entries. // Guard against the length ending up zero, that's not valid. int length = (int)(elements * loadFactor) + (elements / 20) + 3; if (length > elements && (length & 1) == 0) length--; if (origlength > 0 && length > origlength) length = origlength; Entry<K,V>[] newTable = new Entry[length]; threshold = (int) Math.min(length * loadFactor, MAX_ARRAY_SIZE + 1); count = 0; initHashSeedAsNeeded(length); // Read the number of elements and then all the key/value objects for (; elements > 0; elements--) { K key = (K)s.readObject(); V value = (V)s.readObject(); // synch could be eliminated for performance reconstitutionPut(newTable, key, value); } this.table = newTable; }
hashtable 的序列化和反序列化例子:
/** * hashtale 序列化和反序列化 * * @ClassName: hashtable_test * @author Xingle * @date 2014-6-30 上午9:33:04 */ public class hashtable_test { public static void main(String[] args) { Hashtable<String, String> ht = new Hashtable<>(); ht.put("1", "测试hashtable序列化"); ht.put("2", "天天见"); System.out.println("序列化前hashtable:"+ht); new hashtable_test().serializable(ht); } private void serializable(Hashtable<String, String> ht_int) { try { ObjectOutputStream out = new ObjectOutputStream( new FileOutputStream("test")); out.writeObject(ht_int); out.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } try { ObjectInputStream in = new ObjectInputStream(new FileInputStream( "test")); Hashtable<String, String> ht_out = (Hashtable<String, String>) in.readObject(); System.out.println("反序列化后hashtable:"+ht_out); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }