SQL语句是如何执行的?

连接器:第一步,先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的: mysql -h$ip -P$port -u$user -p 连接建立完成后,你就可以执行 select 语句了。
查询缓存:第二步执行逻辑,MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。但是大多数情况下我会建议你不要使用查询缓存,为什么呢?因为查询缓存往往弊大于利。
分析器:先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
优化器:是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
执行器:MySQL 通过分析器知道了你要做什么,通过优化器知道了该怎么做,于是就进入了执行器阶段,开始执行语句。开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证。查询也会在优化器之前调用 precheck 验证权限)。
索引分类?
单列索引,聚合索引,全文索引
单列索引又分:主键索引,唯一索引,普通索引
主键索引 :又称聚簇索引,主键索引的叶子节点存的是整行数据,根据主键查询可以直接查询出记录,没有回表的操作。
普通索引: 又称二级索引,非主键索引的叶子节点内容是主键的值,基于非主键索引的查询需要多扫描一棵索引树(回表)。
覆盖索引:查询的结果直接在索引树上 (select 字段在索引树上),不需要回表。覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段,explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
couny()最优?
首先couny(*)、couny(主键 id) 和 couny(1) 都表示返回满足条件的结果集的总行数;
至于分析性能差别的时候,你可以记住这么几个原则:
1)server 层要什么就给什么;
2)InnoDB 只给必要的值;
3)现在的优化器只优化了couny(*)的语义为取行数
couny(主键 id) :InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
couny(1) :InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
couny(*): 是例外,并不会把全部字段取出来,而是专门做了优化,不取值。couny(*) 肯定不是 null,按行累加
couny(字段):则表示返回满足条件的数据行里面,参数“字段”不为 NULL 的总个数
couny性能比较,couny(字段)<couny(主键)<couny(1)基本等于couny(*),但是MySQL目前只对couny(*)进行了优化,因此建议使用couny(*)
排序原理?
MySQL会为每个线程分配一个sort_buffer,当查询出符合条件的记录后,会将记录存放到sort_buffer。 当sort_buffer_size够用的时候,就直接在内存中排序,如果当sort_buffer_size不够用的时候,就会借助磁盘进行排序。 一般MySQL会优先选择全字段排序,只有当记录数量比较大时,才使用Rowid排序,使用Rowid排序会有回表的过程,因此性能也会有所降低。
回表查询?
一次查询索引树就能到得结果的,不会回表查询,需要多次查询索引树,才能得到需要的结果称为回表查询。
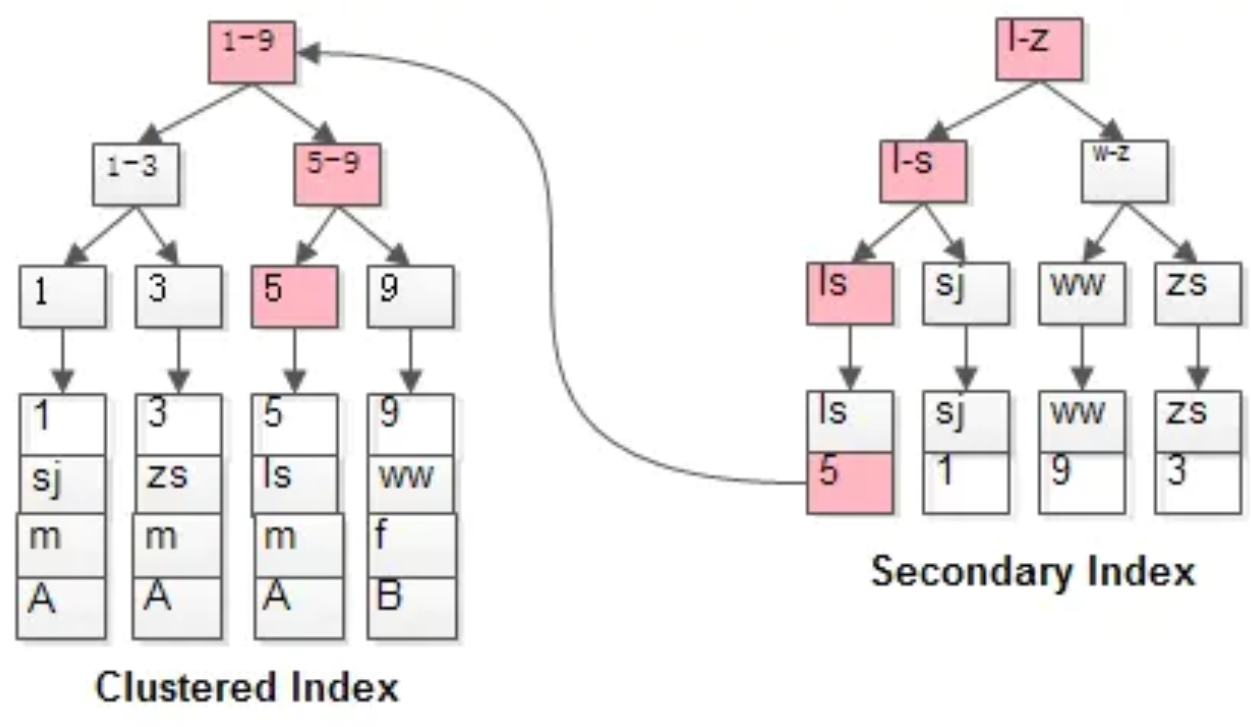
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
例如:
CREATE TABLE t ( id INT PRIMARY KEY, age INT NOT NULL DEFAULT 0, addr VARCHAR(64), INDEX age(age) ) ENGINE = INNODB; SELECT * FROM t WHERE id=1;
使用主键索引 SELECT * FROM t WHERE age BETWEEN 3 AND 5;使用普通索引age,并且会有回表操作,select * 查询的字段不全在索引树上,需要通过主键再次去主键索引树上查找,所以有回表操作
SELECT id FROM t WHERE age BETWEEN 3 AND 5;使用覆盖索引,没有回表操作
覆盖索引?
create table user ( id int primary key, name varchar(20), sex varchar(5), key(name) )engine=innodb;
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高

能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。

普通索引VS唯一索引?
查询
唯一索引:扫描索引树,如果找到,则停止扫描。
普通索引:扫描索引树,如果找到,则继续扫描,直到找不到。
更新
唯一索引:用不到change buffer
普通索引:可能会用到change buffer,提高性能
1.新增:唯一索引和普通索引的查询性能差距微乎其微
2.更新: 为了说明普通索引和唯一索引对更新语句性能的影响这个问题,先了解一下 change buffer。当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。需要说明的是,虽然名字叫作 change buffer,实际上它是可以持久化的数据。也就是说,change buffer 在内存中有拷贝,也会被写入到磁盘上。将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。
组合索引?
在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时遵循最左前缀原则。
索引下推?
MySQL 5.6 引入的索引下推优化, 可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,优化减少回表次数。
CREATE TABLE `tuser` ( `id` int(11) NOT NULL, `name` varchar(32) DEFAULT NULL, `age` int(11) DEFAULT NULL, `ismale` tinyint(1) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name_age` (`name`,`age`) ) ENGINE=InnoDB;
SELECT * from tuser where name like '陈%' and age=20
Mysql5.6及之前版本
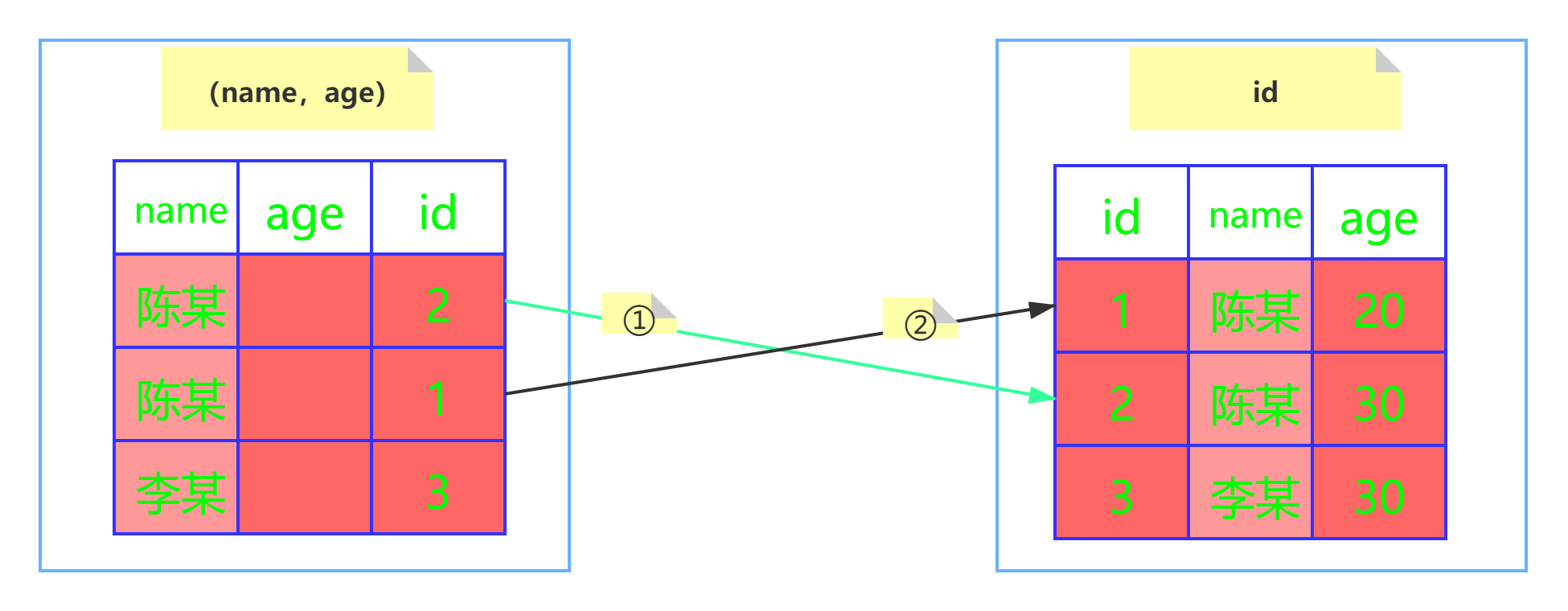
会忽略age这个字段,直接通过name进行查询,在(name,age)这课树上查找到了两个结果,id分别为2,1,然后拿着取到的id值一次次的回表查询,因此这个过程需要回表两次。
Mysql5.6及之后版本
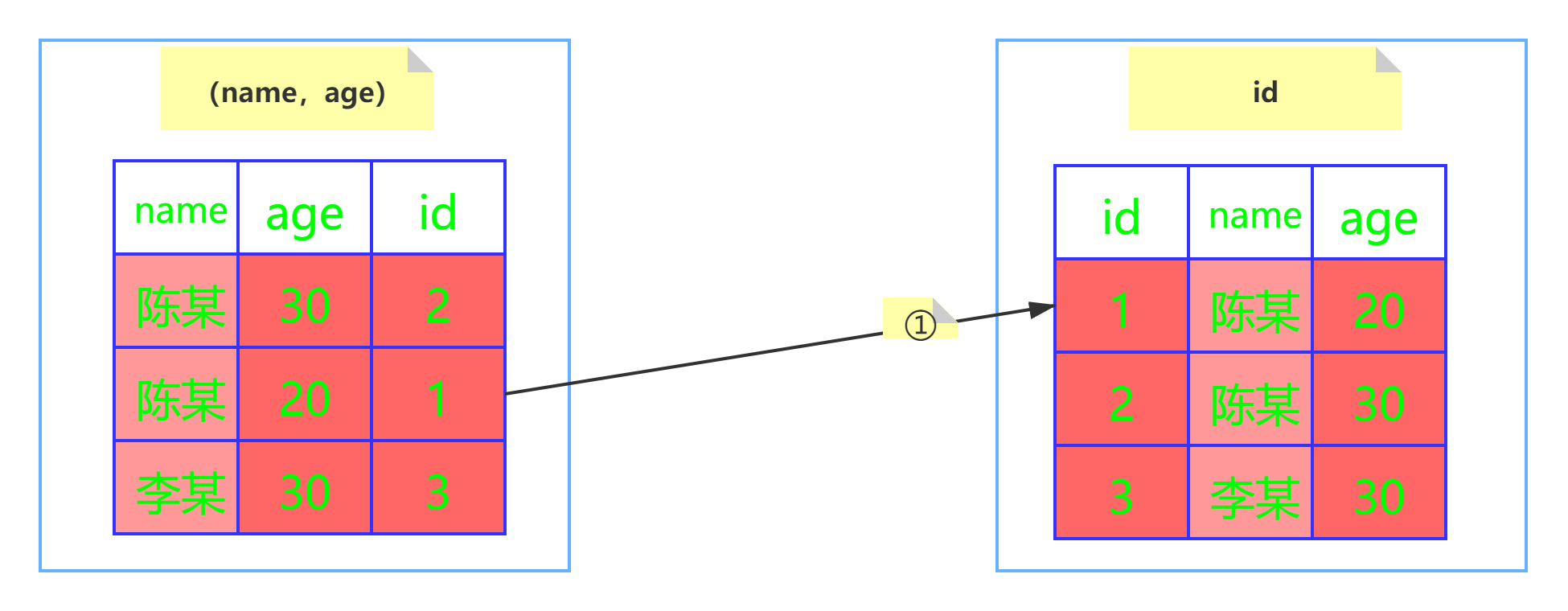
InnoDB并没有忽略age这个字段,而是在索引内部就判断了age是否等于20,对于不等于20的记录直接跳过,因此在(name,age)这棵索引树中只匹配到了一个记录,此时拿着这个id去主键索引树中回表查询全部数据,这个过程只需要回表一次。

根据explain解析结果可以看出Extra的值为Using index condition,表示已经使用了索引下推。