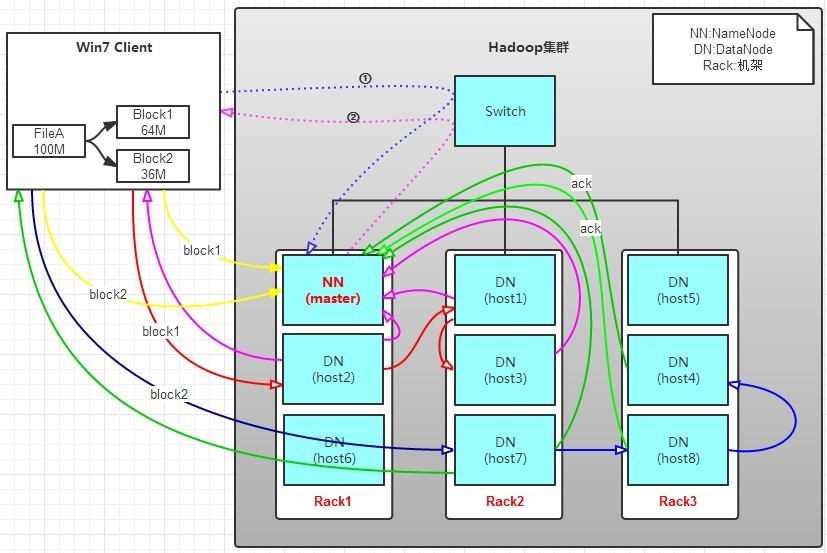
-- copy from Internet https://www.cnblogs.com/wxplmm/p/7239342.html
NameNode:是Master节点,有点类似Linux里的根目录。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:保存着NameNode的部分信息(不是全部信息NameNode宕掉之后恢复数据用),是NameNode的冷备份;合并fsimage和edits然后再发给namenode。(防止edits过大的一种解决方案)
DataNode:负责存储client发来的数据块block;执行数据块的读写操作。是NameNode的小弟。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
Namenote 详解
作用:
Namenode起一个统领的作用,用户通过namenode来实现对其他数据的访问和操作,类似于root根目录的感觉。
Namenode包含:目录与数据块之间的关系(靠fsimage和edits来实现),数据块和节点之间的关系
fsimage文件与edits文件是Namenode结点上的核心文件。
Namenode中仅仅存储目录树信息,而关于BLOCK的位置信息则是从各个Datanode上传到Namenode上的。
Namenode的目录树信息就是物理的存储在fsimage这个文件中的,当Namenode启动的时候会首先读取fsimage这个文件,将目录树信息装载到内存中。
而edits存储的是日志信息,在Namenode启动后所有对目录结构的增加,删除,修改等操作都会记录到edits文件中,并不会同步的记录在fsimage中。
而当Namenode结点关闭的时候,也不会将fsimage与edits文件进行合并,这个合并的过程实际上是发生在Namenode启动的过程中。
也就是说,当Namenode启动的时候,首先装载fsimage文件,然后在应用edits文件,最后还会将最新的目录树信息更新到新的fsimage文件中,然后启用新的edits文件。
整个流程是没有问题的,但是有个小瑕疵,就是如果Namenode在启动后发生的改变过多,会导致edits文件变得非常大,大得程度与Namenode的更新频率有关系。
那么在下一次Namenode启动的过程中,读取了fsimage文件后,会应用这个无比大的edits文件,导致启动时间变长,并且不可控,可能需要启动几个小时也说不定。
Namenode的edits文件过大的问题,也就是SecondeNamenode要解决的主要问题。
SecondNamenode会按照一定规则被唤醒,然后进行fsimage文件与edits文件的合并,防止edits文件过大,导致Namenode启动时间过长。
DataNode详解
DataNode在HDFS中真正存储数据。
首先解释块(block)的概念:
- DataNode在存储数据的时候是按照block为单位读写数据的。block是hdfs读写数据的基本单位。
- 假设文件大小是100GB,从字节位置0开始,每128MB字节划分为一个block,依此类推,可以划分出很多的block。每个block就是128MB大小。
- block本质上是一个 逻辑概念,意味着block里面不会真正的存储数据,只是划分文件的。
- block里也会存副本,副本优点是安全,缺点是占空间
SecondaryNode
执行过程:从NameNode上 下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.