




first order markov chain








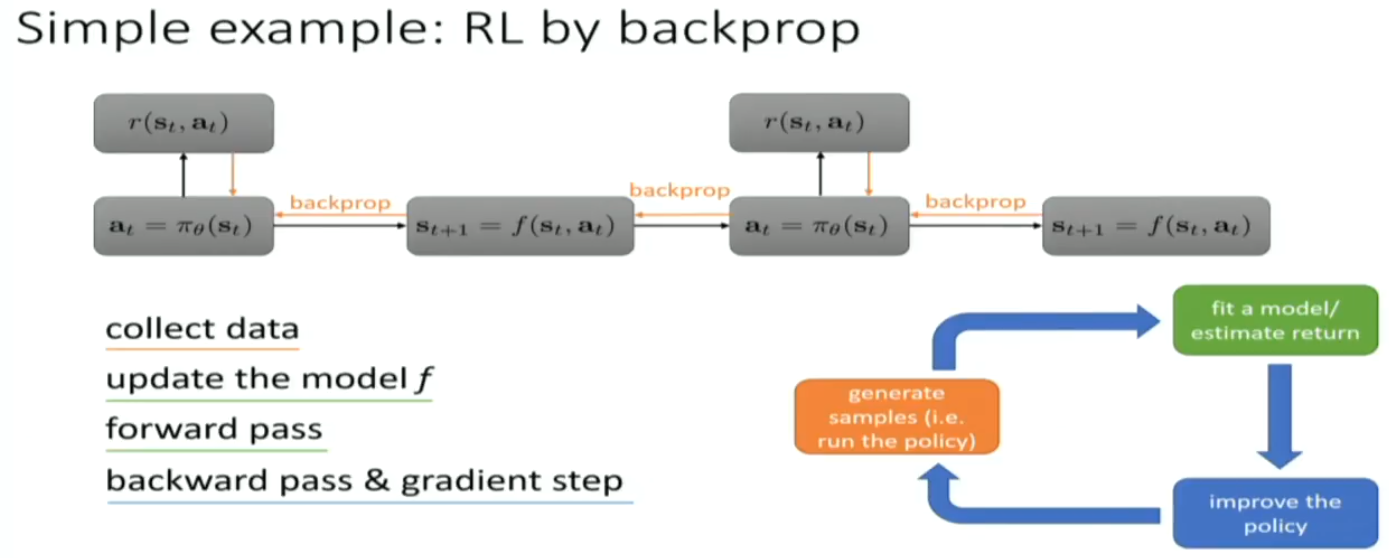









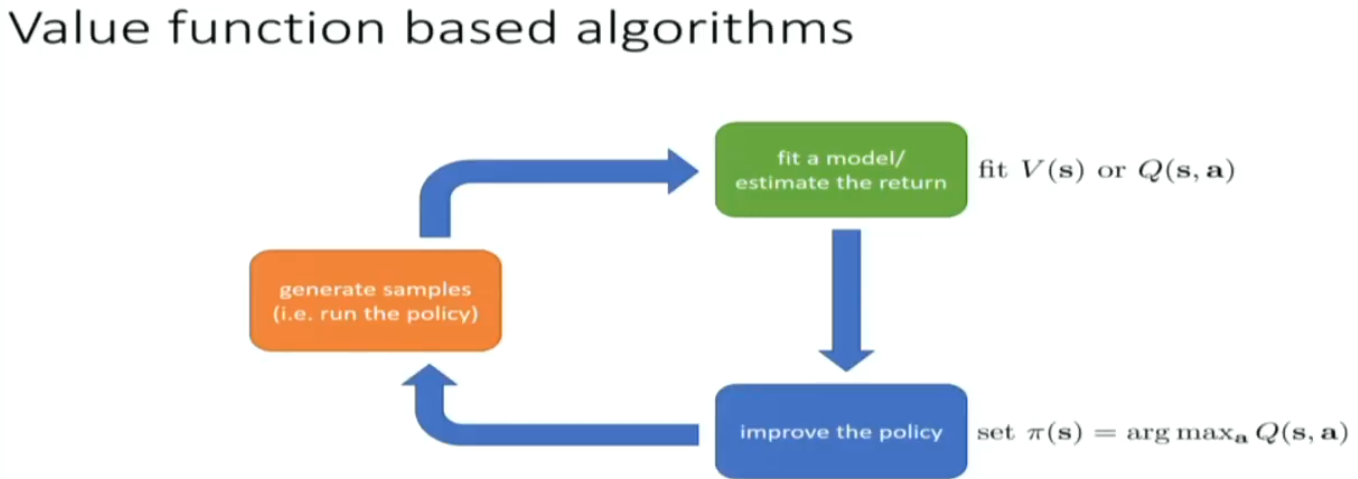






on policy algorithm is easier to be paralleled
off policy algorithm has to fit transition net, and policy net. much more computationally expensive








first order markov chain
on policy algorithm is easier to be paralleled
off policy algorithm has to fit transition net, and policy net. much more computationally expensive