当前智能网卡已经从10G时代迈入25G时代,并且向50G/100G时代演进。云化带来的每年的增量是非常客观的,Mellanox/Broadcom等厂商之间的竞争也很激烈。降成本,提性能,是个永恒的话题。
在相关性能技术支撑中,多队列是很重要的一环。它源起处理器的多核技术带来的并行挑战,后来加入QoS和虚拟化技术的支持。利用多队列和流分类,可以达到更为高效的IO处理。基本上目前主流的技术,都要跟多队列打交道,比如:virtio,nvme,nvmeof,rdma等等。
本文关注多队列的通用技术和优化权衡,分为三个部分。
第一部分先理一下网卡的通用处理和框架。
第二部分深入下Tx发包方向的队列mapping选择和分发。
第三部分深入下Rx收包方向的预解析/流分类/过滤/分发。
简单描述下第一部分。网卡根据报文流向可以分为入向(Ingress)和出向(Egress)两个方向。
01
—
NIC报文入向框图
Ingress方向框图如下:

(1) 接口测
在目前的data center中,主要有如下接口:
l 1G-SFP-AOC/1G-SFP-DAC
l 10G-SFP+-AOC/10G-SFP+-DAC
l 25G-SFP28-AOC/25G-SFP28-DAC
l 100G-QSFP28-AOC/100G-QSFP28-DAC
光模块的适配/兼容是个重点,link/CRC错误/MAC过滤等系列问题会时常遇到。性能第一步的MAC收发包统计计数是必备的工具。
(2) Parser/整包
报文从接口测经过物理层和MAC层,一般对应内部会map到FIFO层。后续的处理,为了提高效率,一般都会分为并行的两个方向:
l Parser。硬件可以解析报文头,根据提取信息,比如五元组或者其他预解析字段,作为后面流分类和分发的key值。这部分有的NIC是固化的寄存器,解析L2/L3/L4等有限;有些功能强大的会配合一个微处理器,增强解析功能。如果无法解析的报文,只能到后端的CPU来进行分析处理。如果前端parser越强,那么后端的CPU的处理就会越少,节省的cycles可以用于转发性能提升。
l DMA。真正的报文要实现整包的处理,dma到指定的buffer中。
也就是报文的控制和数据通道是分离的。这个扩展到具体应用场景,可以配合后续的QoS模块等实现控制通道和数据通道的分离,防止线头阻塞(HOL)等。
(3) 流分类/过滤/分发
因为有多队列,那么就要面临如何选择队列的问题,也就是mapping。Parser提取字段可以作为流分类的基础,这里有两种技术:RSS和Flow Director。RSS是根据hash散列到指定目的地,flow director是精确匹配。有些NIC比较简单,片上TCAM作为flow director的表向,只能支持几个条目;有些功能比较强,那么可以支持几K甚至通过spill技术用到DRAM来补充片上资源的不足。但就其本质而言,还是查表来选择drop/组播复制/出端口发送。
对于智能网卡而言,这一部分也是技术的重心。在转发性能保障的情况下,flow支持的越多,offload能够做的事情越多,对后端CPU的压力就越小。所以,该部分技术核心在于业务模型的熟悉和理解,ULP抽象层要尽可能的支持度广,NIC硬件驱动做好底层适配。
(4) 分发到CPU,可以增加软件队列,实现负载均衡或者QoS,以弥补硬件NIC无法支持的功能。这里的RPS技术就可以配合使用。
02
—
NIC报文出向框图
Egress方向框图如下:
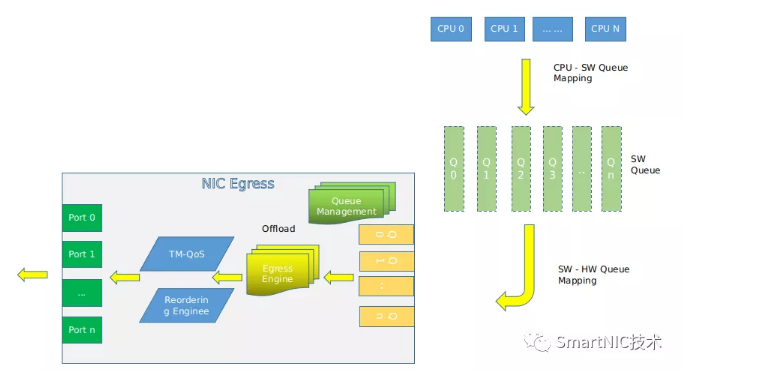
(1) 发送端的队列选择
发送测和接收测类似,可以实现软件队列到硬件队列的mapping。软件队列可以根据需求实现硬件无法支持的部分功能。这里Linux和DPDK的队列选择机制是不相同的,后面根据代码分析。一般是由应用来提供灵活的队列选择机制,可以根据driver制定的策略,也可以根据队列优先级,也可以hash均衡,也可以1:1映射。XPS就是对应此处的一项技术,用于transmit flow steering。
(2) Egress engine
可以硬件实现TSO等来加速。各个NIC支持的功能均不相同。
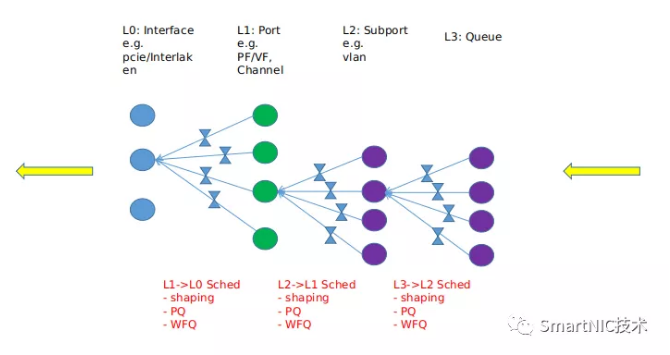
(3) QoS调度
Egress方向的调度模型示例如下:
(4) 保序
有些实现了硬件保序,有些没有。如果没有的情况下,全路径根据flow进入单一队列来完成保序也是可用的方案。
总之,对于任何一个NIC而言,报文的生命周期是要了解的。对于NP等复杂NIC而言,里面的设计机制尤为复杂,需要投入较多的精力才能掌握。