Scrapy基础命令
- 创建目录 :
scrapy startproject scrapystest - 创建爬虫
- 进入项目
cd scrapytest - 创建爬虫
scrapy genspider xxx(爬虫名) xxx.com(爬取域)
- 进入项目
- 生成文件 :
scrapy crawl xxx -o xxx.json(生成某种类型的文件) - 运行爬虫 :
scrapy crawl xxx - 列出所有爬虫 :
scrapy list - 获取配置信息 :
scrapy settings[options]
Scrapy文件
- scrapy.cfg : 项目配置文件
- scrapytest : 生成的项目文件
- items : 创建容器的文件,爬取的信息分别放到不同的容器里面
- middlewares : 定义Downloader Middlewares(下载中间件)和Spider Middlewares(爬取中间件)的实现
- pipelines : 定义Item Pipeline的实现,实现数据的清晰,储存,验证
- settings : 全局配置文件
settings设置
-
项目名称,默认的USER_AGENT由他来构成,也作为日志记录的日志名
BOT_NAME = 'scrapytest' -
爬虫储存的文件路径
SPIDER_MODULES = ['scrapytest.spiders'] -
创建爬虫文件的模板,创建好的爬虫文件会存放在这个目录下
NEWSPIDER_MODULE = 'scrapytest.spiders' -
客户端User-Agent请求头,伪装UA
USER_AGENT = 'scrapytest (+http://www.yourdomain.com)' -
是否遵守爬虫协议,默认遵守
ROBOTSTXT_OBEY = True -
设置请求的最大并发数据(下载器)默认是16
CONCURRENT_REQUESTS = 32 -
设置请求的下载延时,默认为0
DOWNLOAD_DELAY = 3 -
设置网站的最大并发请求量,默认是8
CONCURRENT_REQUESTS_PER_DOMAIN = 16 -
设置某个ip的最大并发请求数量,默认是0,设置某个ip的最大并发请求数量,默认是0,如果非0,CONCURRENT_REQUESTS_PER_DOMAIN不生效, 这时的请求并发数量针对于ip,而不是网站置,DOWNLOAD_DELAY针对ip而不是网站
CONCURRENT_REQUESTS_PER_IP = 16 -
是否支持cookie,cookiejar进行操作cookie,默认开启
COOKIES_ENABLED = False -
跟踪cookies,默认为Flase
COOKIES_DEBUG = False
- 一个终端的扩展插件
TELNETCONSOLE_ENABLED = False
-
设置默认的请求头
DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } -
设置和激活爬虫中间件,后面的数字代表优先级,数字越小优先级越高
SPIDER_MIDDLEWARES = { 'scrapytest.middlewares.ScrapytestSpiderMiddleware': 543, } -
设置和激活下载中间件
DOWNLOADER_MIDDLEWARES = {
'scrapytest.middlewares.ScrapytestDownloaderMiddleware': 543,
}
-
设置扩展
EXTENSIONS = { 'scrapy.extensions.telnet.TelnetConsole': None, } -
设置和激活管道文件
ITEM_PIPELINES = { 'downloadmiddlewares.pipelines.DownloadmiddlewaresPipeline': 300, } -
默认情况下,自动限速扩展是关闭的
AUTOTHROTTLE_ENABLED = True
- 初始的下载延时,默认5秒
AUTOTHROTTLE_START_DELAY = 5
- 最大下载延时
AUTOTHROTTLE_MAX_DELAY = 60
- 针对于网站的最大并行请求数量
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
- 调试模式:默认为False,未开启
AUTOTHROTTLE_DEBUG = False
- 设置数据缓存,默认未开启
HTTPCACHE_ENABLED = True
- 设置缓存超时时间,默认为0,表示永久有效
HTTPCACHE_EXPIRATION_SECS = 0
- 设置缓存数据的存储路径
HTTPCACHE_DIR = 'httpcache'
- 忽略某些状态码的请求结果
HTTPCACHE_IGNORE_HTTP_CODES = []
- 开启缓存的扩展插件
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
Scrapy流程图

Scrapy框架主要有六大组件组成,它们分别是Scrapy引擎(Scrapy Engine)、调度器(Scheduler)、下载器(Downloader)、爬虫(spider)、中间件(Middleware)、实体管道(Item Pipeline)
- Scrapy Engine(引擎) : Scrapy引擎是整个框架的核心。它用来控制调试器、下载器、爬虫。它就相当于计算机中的CPU,控制着整个流程。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎再把其他模块中请求回来的数据再发送给爬虫,爬虫就会去解析想要的数据。爬取链接以及解析页面中的数据都是由自己来写的。
- Scheduler(调度器):它负责引擎发过来的请求,按照一定的方式进行排序和整理,负责调度请求的顺序等。
- Downloader(下载器):它负责引擎发过来的下载请求,然后去网络上下载对应的数据后,再把这个数据交还给引擎。
- Item Pipeline(实体管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里应该看我们自己的需要。
- Middleware(中间件):负责对Request对象和Response对象进行处理
Scrapy流程
- 首先从Spider发送一个请求,初始化了一个Resquest对象,并且设置了回调函数( def parse(self, response) ),把请求传给引擎
- 引擎收到请求后,并不会把请求马上发出去,而是传给了调度器。调度器接受到引擎发过来的Request请求后,把Request对象按照一定的排序算法储存到它里面的一个队列当中
- 接下来引擎会不断的从调度器当中取出已经处理好的Request
- 当引擎拿到Request后,再把这个请求扔给下载器
- 下载器拿到请求后,按照下载中间件中的设置去下载request请求。下载好数据后再把数据传给引擎
- 引擎拿到数据后,把数据通过爬虫中间件返回给Spider。并把response作为参数传递给第一步设置好的回调函数
- Spider拿到数据后,经过数据分析筛选出需要的信息,之后再把信息传给引擎
- 引擎拿到数据传给实体管道, 通过管道中定义的储存规则进行存储
crawlspider
-
crawlspider是spider的一个子类,除了继承Spider的功能外,海派生了其更强大的功能和特性。其中最显著的功能就是 LinkExtractors链接提取器 Spider是所有爬虫的基类
-
创建项目
#创建一个scrapy工程 scrapy startproject projectName #进入工程文件 cd projectName #创建爬虫文件,在创建时比之前创建爬虫文件多了 -t crawl表示的是创建的爬虫文件是一个基于Crawl Spider这个类 scrapy genspider -t crawl spidername www.xxx.comimport scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class BaiduSpider(CrawlSpider): name = 'baidu' #allowed_domains = ['www.baidu.com'] start_urls = ['http://www.baidu.com/'] #allow表示链接提取器提取链接的规则 rules = ( #Rule 规则提取器:将链接提取器提取到的链接所对应的页面进行指定形式的解析 #follow 让连接提取器继续作用到链接提取器提取到的链接所对应的页面中 Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True), ) def parse_item(self, response): item = {} #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() return item
scrapy-redis
Scrapy是一个通用的爬虫框架,虽然功能很强大,但本身并不支持分布式。Scrapy-redis是一个基于redis的Scrapy组件,用于快速实现scrapy项目的分布式部署和数据爬取。
Scrapy使用python自带的collection.deque来存放待爬取的request。scrapy-redis提供了一个解决方案,把deque换成redis数据库,可以通过多个爬虫读取同一个redis数据库里的数据,解决了多样主要问题。
Scrapy-redis架构
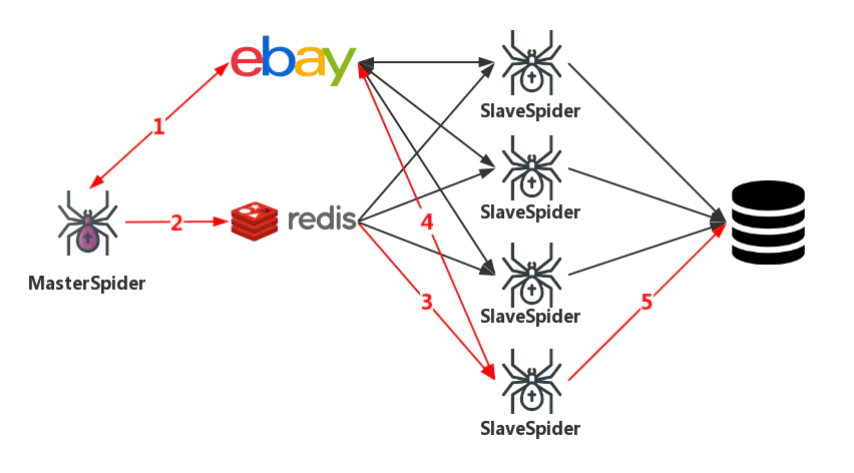
MasterSpider对start_urls中的urls构造request,获取responseMasterSpider将response解析,获取目标页面的URL,利用Redis的对URL重去生成并爬待request队列SlaveSpider读取redis中的待爬样本,构造requestSlaveSpider发起请求,获取目标页面的responseSlavespider解析response,获取目标数据,写入生产数据库
Scrapy-redis组件
-
Scheduler : Scrapy中跟“待爬队列”直接相关的就是调度器
Scheduler,它负责对新的request进行入列操作(加入Scrapy queue),取出下一个要爬取的request(从Scrapy queue中取出)等操作。 但是原来的Scheduler已经无法使用,所以使用Scrapy-redis的scheduler组件。 -
Duplication Filter : 在scrapy-redis中去重是由
Duplication Filter组件来实现的,它通过redis的set 不重复的特性,巧妙的实现了Duplication Filter去重。scrapy-redis调度器从引擎接受request,将request的指纹存⼊redis的set检查是否重复,并将不重复的request push写⼊redis的 request queue。引擎请求request(Spider发出的)时,调度器从redis的request queue队列⾥里根据优先级pop 出⼀个request 返回给引擎,引擎将此request发给spider处理。
-
Item Pipeline : 引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。
-
Base Spider : 不再使用scrapy原有的Spider类,重写的
RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
- 一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用
schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。 - 一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用
schedule_next_request函数,获取下一个request。
- 一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用
配置调整
# 过滤器
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度状态持久化
SCHEDULER_PERSIST = True
# 请求调度使用优先队列
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
# redis 使用的端口和地址
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379