1.Jupyter notebook中的魔法命令
%run 在Jupyter中加载.py文件
先搞清楚Jupyter中文件的默认路径,修改完后再运行
import os print(os.path.abspath('.'))
F:python_DemoCodeJuypterNotebook
%run ../fushi/P2018_1.py
导入模块(二选一即可)
import mymodule.FirstML
mymodule.FirstML.predit(1)
from mymodule import FirstML FirstML.predit(1)
%timeit测试代码性能(会多次执行,%%time可以测试区域代码)
%timeit L=[i**2 for i in range(1000000)]
1 loop, best of 3: 459 ms per loop
%%timeit L=[] for i in range(1000): L.append(i**2)
1000 loops, best of 3: 477 µs per loop
Tip:因为%timeit会执行多次,如果后面紧跟的语句每次执行的效率差别较大的话,取平均值的意义不大。
%time执行一次计时
%time L=[i**2 for i in range(1000)]
Wall time: 486 µs
其他魔法命令:
%lsmagic显示所有魔法命令
%run? run魔法命令对应文档
2.numpy基础
import array arr=array.array('i',[i for i in range(10)]) arr Out[7]:array('i', [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) arr[5]=100 arr Out[8]:array('i', [0, 1, 2, 3, 4, 100, 6, 7, 8, 9])
numpy.array的创建
import numpy as np nparr=np.array([i for i in range(10)]) nparr Out[9]:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) nparr.dtype Out[10]:dtype('int32') nparr[5]=5.0 nparr Out[11]:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) #对于整型来说,传给他浮点数会自动截位 nparr2=np.array([1,2,3.0]) nparr2.dtype Out[13]:dtype('float64')

np.zeros(10) Out[14]:array([ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]) np.zeros((3,5),dtype=int) #np.zeros(shape=(3,5),dtype=int)
Out[15]: array([[0, 0, 0, 0, 0], [0, 0, 0, 0, 0], [0, 0, 0, 0, 0]])
arange方法和python2中的arange方法类似,默认值是0-n-1,但是它支持步长为小数。
np.arange(10)
Out[16]:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(0,20,2) Out[17]:array([ 0, 2, 4, 6, 8, 10, 12, 14, 16, 18])
np.arange(0,1,0.2) Out[18]:array([ 0. , 0.2, 0.4, 0.6, 0.8])
np.linspace(0,20,10) #0到20之间等间距地分成10份,包含0和20两个点
np.linspace(0,20,10) Out[20]: array([ 0. , 2.22222222, 4.44444444, 6.66666667, 8.88888889, 11.11111111, 13.33333333, 15.55555556, 17.77777778, 20. ])
numpy.random

random() [0,1)之间的随机浮点数
np.random.seed(666)
np.random.randint(0,10,10) #创建10个[0,10)之间的整数(注意前闭后开) Out[21]:array([3, 6, 8, 6, 2, 7, 9, 2, 3, 9])
np.random.randint(4,8,size=(3,5))
Out[22]:
array([[4, 5, 5, 5, 4],
[4, 7, 4, 6, 4],
[7, 6, 5, 7, 4]])
np.random.random(10) #10是指size
Out[23]:
array([ 0.50242227, 0.17298419, 0.26348954, 0.600199 , 0.6691488 ,
0.39283773, 0.37043944, 0.30396405, 0.99071216, 0.65455463])
![]()
默认符合均值为0,方差为1的随机浮点数
np.random.normal(10,100,size=(3,5)) Out[26]: array([[ -24.5258828 , -23.72306007, 6.88579462, -23.29286657, -33.32319528], [ -39.33190778, 2.43981867, -30.17166951, 6.22937488, 3.79212453], [ 22.72826743, -156.27817465, 8.43966765, -46.36703314, 33.91110828]])
查看相关文档:
np.random.normal?可以调出normal相关文档(会开一个新页面)。
np.random?调出random模块相关文档(会开一个新页面)。
help(np.random.normal)
numpy.array的基本操作
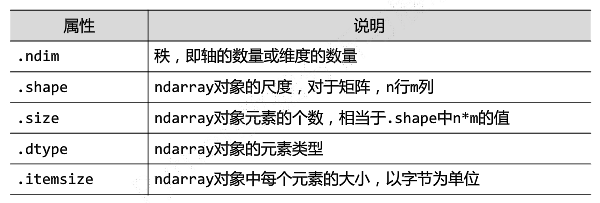
numpy.array的数据访问
1.索引访问
2.切片访问
X=np.arange(15).reshape(3,5) X Out[27]: array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]]) X[2,2] Out[28]:12 X[:2,:3] Out[29]: array([[0, 1, 2], [5, 6, 7]]) X[:,:3] #选取某个维度用单个: Out[30]: array([[ 0, 1, 2], [ 5, 6, 7], [10, 11, 12]])
subX=X[:2,:3]
subX获得的是对原X的引用,对subX的操作会作用到原X中,同步变化(浅拷贝)
subX2=X[:2,:3].copy()
subX获得的是对原X的副本,对subX的操作不会作用到原X中(深拷贝)
numpy.array的数组变换

x=np.arange(10) x Out[31]:array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) x.reshape(2,5) Out[32]: array([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]) x.reshape(5,-1) #只关心第一维度5行,第二维度自动计算(能自动整除,否则报错),可赋值为-1 Out[33]: array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]])
矩阵的合并与分割
![]()
x=np.array([1,2,3]) y=np.array([3,2,1]) z=np.array([6,6]) np.concatenate([x,y,z]) Out[34]: array([1, 2, 3, 3, 2, 1, 6, 6]) A=np.array([[1,2,3], [3,4,5]]) np.concatenate([A,A]) Out[35]: array([[1, 2, 3], [3, 4, 5], [1, 2, 3], [3, 4, 5]]) np.concatenate([A,A],axis=1) #axis表示维度,默认为0 Out[36]: array([[1, 2, 3, 1, 2, 3], [3, 4, 5, 3, 4, 5]]) np.concatenate([A,x.reshape(1,-1)]) #concatenate只能处理维数一致的情况,不一致的话要转换 Out[37]: array([[1, 2, 3], [3, 4, 5], [1, 2, 3]]) 或者采用vstack(竖直方向堆叠) np.vstack([A,x]) Out[38]: array([[1, 2, 3], [3, 4, 5], [1, 2, 3]])
hstack(水平方向堆叠) B=np.array([[1,1], [1,1]]) np.hstack([A,B]) Out[40]: array([[1, 2, 3, 1, 1], [3, 4, 5, 1, 1]])
np.split()
x=np.arange(10) np.split(x,[3,7]) #以3或7为间隔分割 Out[41]:[array([0, 1, 2]), array([3, 4, 5, 6]), array([7, 8, 9])] np.split(x,5) #第二个参数为整数表示用该数平均切分,不能整除会报错 Out[42]:[array([0, 1]), array([2, 3]), array([4, 5]), array([6, 7]), array([8, 9])] A=np.arange(16).reshape([4,4]) np.split(A,[2]) #默认是按行的维度 Out[45]: [array([[0, 1, 2, 3], [4, 5, 6, 7]]), array([[ 8, 9, 10, 11], [12, 13, 14, 15]])] np.split(A,[2],axis=1) Out[46]: [array([[ 0, 1], [ 4, 5], [ 8, 9], [12, 13]]), array([[ 2, 3], [ 6, 7], [10, 11], [14, 15]])] np.vsplit(A,[2]) #上下分割 Out[47]: [array([[0, 1, 2, 3], [4, 5, 6, 7]]), array([[ 8, 9, 10, 11], [12, 13, 14, 15]])] np.hsplit(A,[2]) Out[48]: #左右分割 [array([[ 0, 1], [ 4, 5], [ 8, 9], [12, 13]]), array([[ 2, 3], [ 6, 7], [10, 11], [14, 15]])]
分割可以应用于分离数据的特征和标签
x,y=np.hsplit(A,[-1])
y[:,0]
Out[50]:array([ 3, 7, 11, 15])
numpy.array中的运算
一元函数:
+,-,*,/,//,**,%作用于数组的每一个元素


np.power(3,x)==3**x 计算数组各元素的3的指数次方
二元函数(矩阵之间的运算要保证是可以运算的)
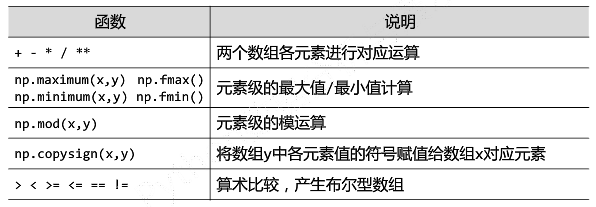
A*B是指对应元素相乘
A.dot(B)是数学意义上的矩阵乘法运算
A.T是矩阵A的转置
向量和矩阵的运算
一个向量和一个矩阵做加法,这个向量和这个矩阵中的每一行做加法
A=np.arange(1,5).reshape([2,2]) v=np.array([1,2]) v+A Out[54]: array([[2, 4], [4, 6]]) np.vstack([v]*A.shape[0]) #水平方向堆叠 Out[56]: array([[1, 2], [1, 2]]) np.tile(v,(2,1)) #元组(2,1)表示行向量堆叠2次,列向量堆叠1次 Out[57]: array([[1, 2], [1, 2]]) v.dot(A) Out[59]:array([ 7, 10]) A.dot(v) #v被看成2*1的矩阵 Out[60]:array([ 5, 11])
矩阵的逆
A 为方阵时:
A的逆=np.linalg.inv(A)
A*A的逆=单位矩阵
A=np.arange(4).reshape(2,2) np.linalg.inv(A) Out[61]: array([[-1.5, 0.5], [ 1. , 0. ]]) A.dot(np.linalg.inv(A)) Out[67]: array([[ 1., 0.], [ 0., 1.]])
A非方阵时,A的伪逆矩阵=np.linalg.pinv(A)
聚合运算
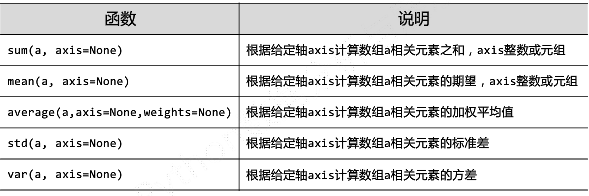
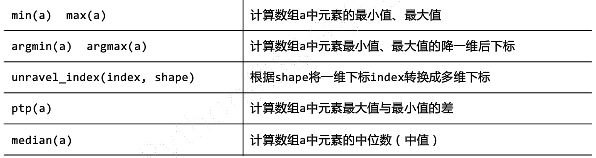
prod(a) 计算数组a中的元素之积
percentile(a,q) 数组中q%个元素小于等于的值(q=50时,该值等于中位数)
A=np.arange(16).reshape(4,-1) A Out[69]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15]]) np.sum(A,axis=0) #把行压缩掉,就是对每列相加 Out[70]:array([24, 28, 32, 36]) np.sum(A,axis=1) #对每行相加 Out[71]:array([ 6, 22, 38, 54])
排序
sort()
A=np.random.randint(10,size=(4,4)) A Out[73]: array([[7, 7, 7, 0], [6, 2, 9, 2], [7, 5, 5, 0], [0, 5, 1, 6]]) np.sort(A,axis=1) #默认axis=1,按行排序 Out[74]: array([[0, 7, 7, 7], [2, 2, 6, 9], [0, 5, 5, 7], [0, 1, 5, 6]]) np.sort(A,axis=0) #按列排序 Out[75]: array([[0, 2, 1, 0], [6, 5, 5, 0], [7, 5, 7, 2], [7, 7, 9, 6]])
x=np.arange(16) np.random.shuffle(x) x Out[77]:array([10, 9, 13, 15, 4, 11, 14, 5, 0, 3, 2, 7, 6, 8, 12, 1]) np.argsort(x) #根据索引项排序后即为正序 Out[78]:array([ 8, 15, 10, 9, 4, 7, 12, 11, 13, 1, 0, 5, 14, 2, 6, 3], dtype=int64) np.partition(x,4) #一次快排的结果,4前面的元素比4小,后面的元素比4大 Out[79]:array([ 1, 0, 2, 3, 4, 5, 14, 9, 11, 15, 13, 7, 6, 8, 12, 10])
numpy中的比较和FancyIndexing
numpy提供对索引数组的访问
x=np.arange(16) ind=[3,5,8] x[ind] Out[80]:array([3, 5, 8]) ind=np.array([[0,2], [1,3]]) x[ind] Out[81]: array([[0, 2], [1, 3]]) A=x.reshape(4,-1) row=np.array([0,1,2]) col=np.array([1,2,3]) #三个点坐标分别为(0,1)(1,2)(2,3) A[row,col] Out[83]:array([ 1, 6, 11]) A[:2,col] Out[84]: array([[1, 2, 3], [5, 6, 7]])
对bool值进行FancyIndexing
比较运算符:<,>,<=,>=,==,!=
col=[True,False,True,True] A[1:3,col] Out[84]: array([[4, 6, 7], [8, 10, 11]]) A<4 Out[86]: array([[ True, True, True, True], [False, False, False, False], [False, False, False, False], [False, False, False, False]], dtype=bool) 2*x==24-4*x Out[87]: array([False, False, False, False, True, False, False, False, False, False, False, False, False, False, False, False], dtype=bool) np.sum(x<=3) #实际应用eg年龄小于4的学生个数,等价于np.count_nonzero(x <= 3) Out[89]:4 np.sum(x%2==0) #偶数个数(通过axis可以指定列数) np.sum((x>3) & (x<10)) #注意中间只用位运算符 np.any(x==0) #是否存在为0的数字,返回True np.all(x>0) #是否所有的数都大于0,返回False np.sum(~(x==0)) #等价于np.sum(x!=0) x[x<5] #小于5岁的学生的具体年龄 Out[94]:array([0, 1, 2, 3, 4]) A[A[:,3]%3==0,:] #抽取出满足最后一个数3整除的行 Out[95]: array([[ 0, 1, 2, 3], [12, 13, 14, 15]])