Life-long兴趣建模视角CTR预估模型:Search-based Interest Model
最近正好也花了一些成块的时间来梳理和总结过去的一系列工作,进入了一部分写作状态。乘兴而行,给我们最新的工作写一篇中文解读,介绍我们如何在工业界实现对10000级别的行为序列建模,并将其应用到CTR预估领域。同时也分享一些学术论文里不方便写的个人观点,兜售点私货。论文在这:
https://arxiv.org/pdf/2006.05639.pdf背景
其实在过去的两年时间里,我们团队一直都在思考和探索一个核心的问题:能不能对用户所有的历史行为进行建模,构建这个用户在互联网应用上全生命周期的兴趣?
互联网让人们和这个世界的沟通变得更加"高效"和频繁,每个用户在互联网上都留下了非常丰富的行为足迹。即使局限在一个应用上,比如淘宝这样一个小电商场景,用户的行为是海量的,平均到每个用户其交互行为都过万了。把问题缩小到电商场景这一范围,用户不会写文章或邮件来告诉系统他们想要什么。即使用户有这个意愿,他们也很难去具体的描述自己抽象的兴趣。大多数情况下我们只能通过用户在电商场景的行为来推测其兴趣以及行为模式。要想做一个尊重用户的模型,给每个用户提供其个性化的诉求,会面临两个方面的问题:1. 过去的算法有点“短”。2. 电商应用处在用户交互的末端。
- 过去的算法有点“短”:过去的算法大多数是对一个较短长度的行为序列设计的,比如DIN[1]/DIEN[2]/GRU4REC[3]等。它们的算法复杂度就注定了在线处理的行为序列长度是有限的。有的工作用transformer来代替GRU,其中一个强调的优点是其计算可以并行化。其实这个点在解决序列长度这方面其实是没有什么意义的,因为当前系统在线计算的瓶颈并不是GRU/RNN这类模型计算各个time step的线性依赖,而是卡在了整体模型计算的绝对计算量flops上,毕竟硬件能提供的算力是有成本的,可并行度再高意义也不大。同时在线也不仅仅只需要考虑计算,还需要考虑通信,存储的开销。
- 电商应用处在用户交互的末端。电商场景本身的特性进一步会给建模增加难度:电商应用是用户在互联网交互的一个末端模块,最接近成交这一环。用户在电商场景的行为能表达的信息相对来说是比较有限的,很有可能只包括了其最后的决策行为,比如点击、收藏、购买某个商品,却丢失掉了很多决策路径上的信息。举个例子:“格雷福斯在某新闻APP看到了关于频繁用手机上网浏览技术最新进展会眼红从而导致眼部疲劳的报道,然后到知乎去询问如何缓解这个问题,仔细浏览了几个高赞答案对几款最新的手机膜做了详细的对比分析,最后到淘宝进行商品的浏览并购买了一款自带过滤功能的手机膜完成成交”。这个过程中,电商应用能获取到关于格雷福斯的行为仅仅是最后的几次浏览,无法直接获取其背后全面的决策逻辑信息。这个问题本身非常的困难,也不是我们这篇工作要去解决的,不过它会强化基于用户短期行为的模型带来问题。如果我们本身获取的行为信息就已经集中于末端,再仅仅只关注近期的用户行为,模型接收的信息就太局限了。纵向来看,势必会导致模型观测的大部分行为都集中于最近的热点。与此同时用户的个性化兴趣会因为被“大多数”带来的行为热潮掩盖,而被忽视。
如果我们能对用户更长的行为做建模,引入用户更长周期更多的行为信息,对于每个用户我们也许能更好的理解他多样的兴趣,以及潜在的兴趣逻辑。引入用户更多的行为信息,建模用户全周期更完善的兴趣,给用户提供更个性化的服务,也是在更好的尊重用户。避免其诉求被短时的热点掩盖,被“大多数”所代表。在我们最初讨论的时候, @朱小强 提出了一个模糊却大胆的想法:
“我们能不能为每个用户构建一个索引,将其一生的行为数据进行结构化存储。在线做点击率建模也好,召回也好,可以高效的检索出其和当前建模问题相关的行为,最终进行推断。”
Search-based Interest Model(后文简称SIM)这个工作也是我们兜兜转转实践摸索了一两年,最终选择沿着最早的这个设想设计出了可以在工业界落地的一个解决方案。
在建模用户更长的行为这个方向,我们首先想到的是解耦用户兴趣建模和CTR预估这两个过程,让这两部分的计算异步化。在19年我们披露了UIC&MIMN[4]实践了这一思路。MIMN借鉴了memory network的思想,用一个固定的memory矩阵对用户的兴趣信息进行存储。对于用户每一个新增的行为进行兴趣的encode后,写入其对应的memory slot中。在线计算某个用户CTR的时候使用当前最新的用户兴趣矩阵信息,在进行CTR的推断。这样的做法将长期兴趣建模和CTR预估两部分进行解耦,用户兴趣矩阵提前计算完毕,不会在对CTR预估计算带来latency瓶颈,同时在线需要通信和存储的内容也从原始行为序列变成了固定大小的memory矩阵。在这样的设计帮助下,我们实现了对1000量级的行为序列进行建模,并落地到了在线生产环境。但是这样的方案设计其实存在一些问题,其系统上带来的技术债暂且不表,算法上在目前的技术水平下存在一定的局限性。一个固定大小的memory 矩阵表达信息是有限的,如果我们想建模更长的用户行为序列,比如10000+,memory-based的方法会面临表达能力有限,难以过滤噪声,建模随时间信息遗忘的问题。UIC&MIMN解耦了兴趣建模和在线CTR预估的计算,建模用户兴趣时模型无法获取和使用待预估的候选item的信息。
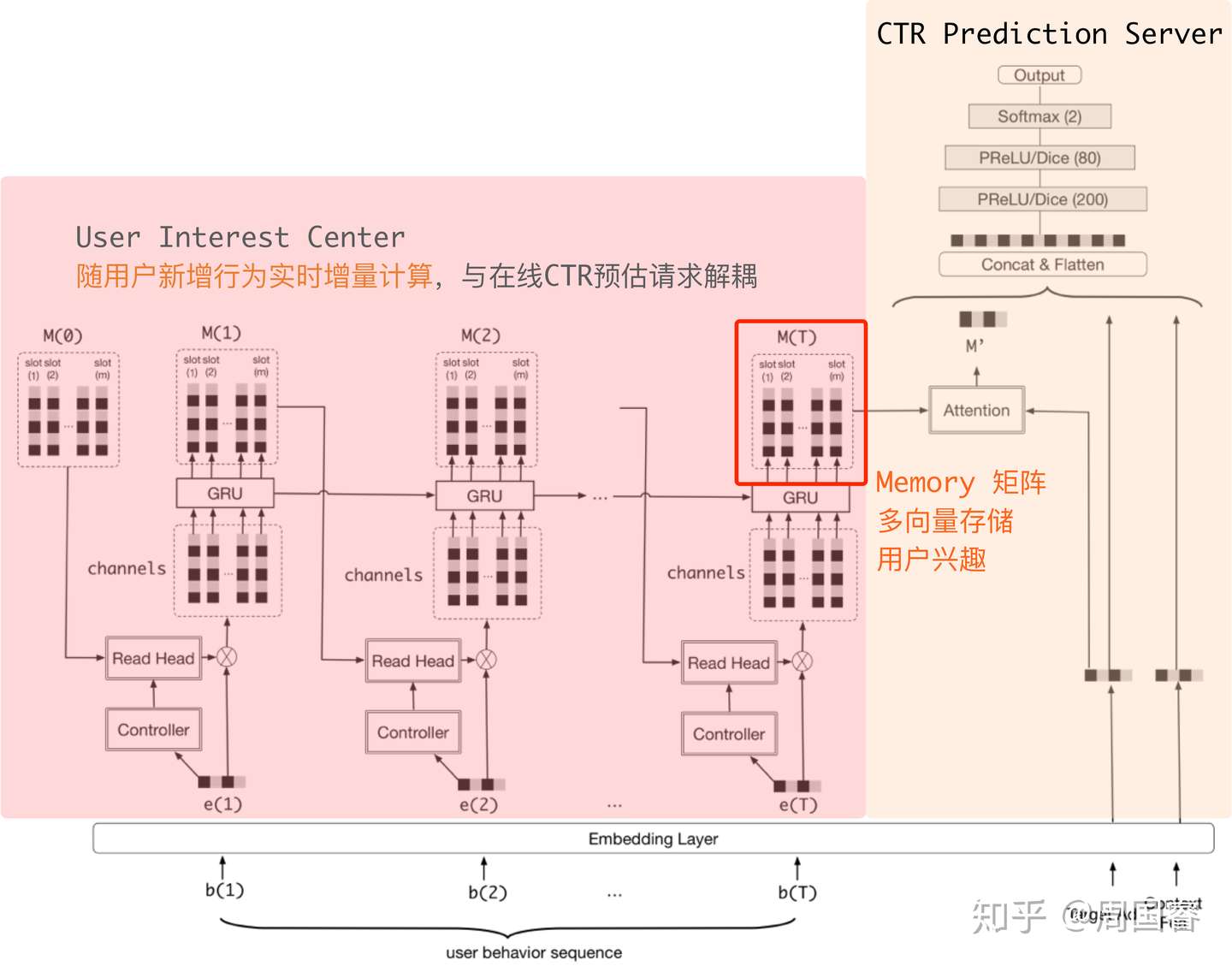 UIC-MIMN
UIC-MIMN
研发MIMN的过程中,我们又一次印证了DIN和DIEN中对预估目标item信息利用的重要性。DIN和DIEN一个很核心的思想是用预估目标item的信息对用户过去的行为进行搜索,找出相关的有效信息,建模用户对当前预估目标item相关的兴趣。这样做的好处是赋予了一个定长的用户兴趣向量根据预估目标item动态变化的表达能力,同时这种做法也很大程度降低了原始的行为序列中隐藏的和当前预估目标item不相关的噪声。CTR预估的核心目标是预测一个用户对一个具体item的CTR,那么模型表达在item维度的自由度显然是其中关键。对MIMN做实验前我预判如果能对原始的行为序列用attention的机制做soft search,这几乎就会是MIMN的一个天花板,后来我们在样本充分的生产数据集上印证了这一点。到这里,我们对电商场景兴趣建模的理解愈发清晰:1. 通过预估目标item的信息对用户过去的行为做search提取和item相关的信息是一个很核心有效的技术。2. 更长的用户行为序列信息对CTR建模是非常有效且珍贵的。从用户的角度思考,我们也希望能关注用户长期的兴趣。但是当前的search方法无论是DIN和DIEN都不允许我们在线对一个超长的行为序列比如1000以上做有效搜索。所以我们的目标就比较明确了,即研发一个可以根据预估目标item信息对用户全生命周期行为进行search,获取该item相关信息的方法。
方法
直接用类似DIN或者DIEN的方案对全行为序列search无疑是在线计算时无法接受的,因此我们想到了能否把搜索解开来,在文中我们提出了两阶段的search模式:general search 和 exact search。从精度角度我们将搜索拆解为一个相对粗糙普适的搜索和一个更为具体精确的搜索。从计算过程角度我们希望general search的大部分计算可以离线完成,并且将历史行为的数量缩小到几百的量级,给exact search部分的建模保留充足的计算复杂度空间。
exact seatch部分我们没有投入太多的精力,可以把它看做是一个短序列建模问题,用DIN/DIEN或者一些其他的类似结构皆可行。当然在长序列建模里,我们发现以前尝试不那么有效的时间信息影响变大了,因此在exact search这部分引入了时间信息,具体的做法可以看披露的论文SIM。核心的难点还是在general search部分,研发过程中有两种思路:1. 用参数化的方式,我们通过对用户的行为和item进行向量化,然后用基于内积的近似最近邻检索出Top_K个相关的行为,比如这篇文章Maximum Inner Product Search (MIPS)[5]。在线计算CTR时,通过向量对每个用户的历史行为构建一个基于内积距离的近似近邻层次索引,每个item可以高效的检索与其相关的行为。具体此方法的在线和离线实现可以看看论文,这里不详细介绍。2. 在实践过程中,我们发现电商数据天然的账户体系或者结构性让general search有更简单的实现方式。电商场景用户行为大部分交互对象也是item,item有其固有的类目信息category,我们可以对每个用户的历史行为基于category构建一层索引,类目相关的行为可以离线进行挂载。整体用户的行为数据会被构建为一个 的结构,一级索引
为user,二级索引
为类目category,value为该类目下的行为序列,或者也可以进一步扩展为类目相关的行为序列。在线的时候根据用户信息以及每个预估目标商品的类目进行general search,得到一个和当前item相关的子序列。general search后的结果根据我们的数据特性大致会从几万的原始行为量级降低到几百,这个量级就可以轻松的完成在线通信、实时的exact search计算以及CTR的计算。需要注意的是无论是索引结构存放的数据和general search后的结果,都是用户的行为序列原始信息,可以是原始的ID序列。这样保障了我们对信息仅仅做了general search这一步选择维度的过滤,没有类似embedding这样的信息压缩,最大程度的保留了原始信息。
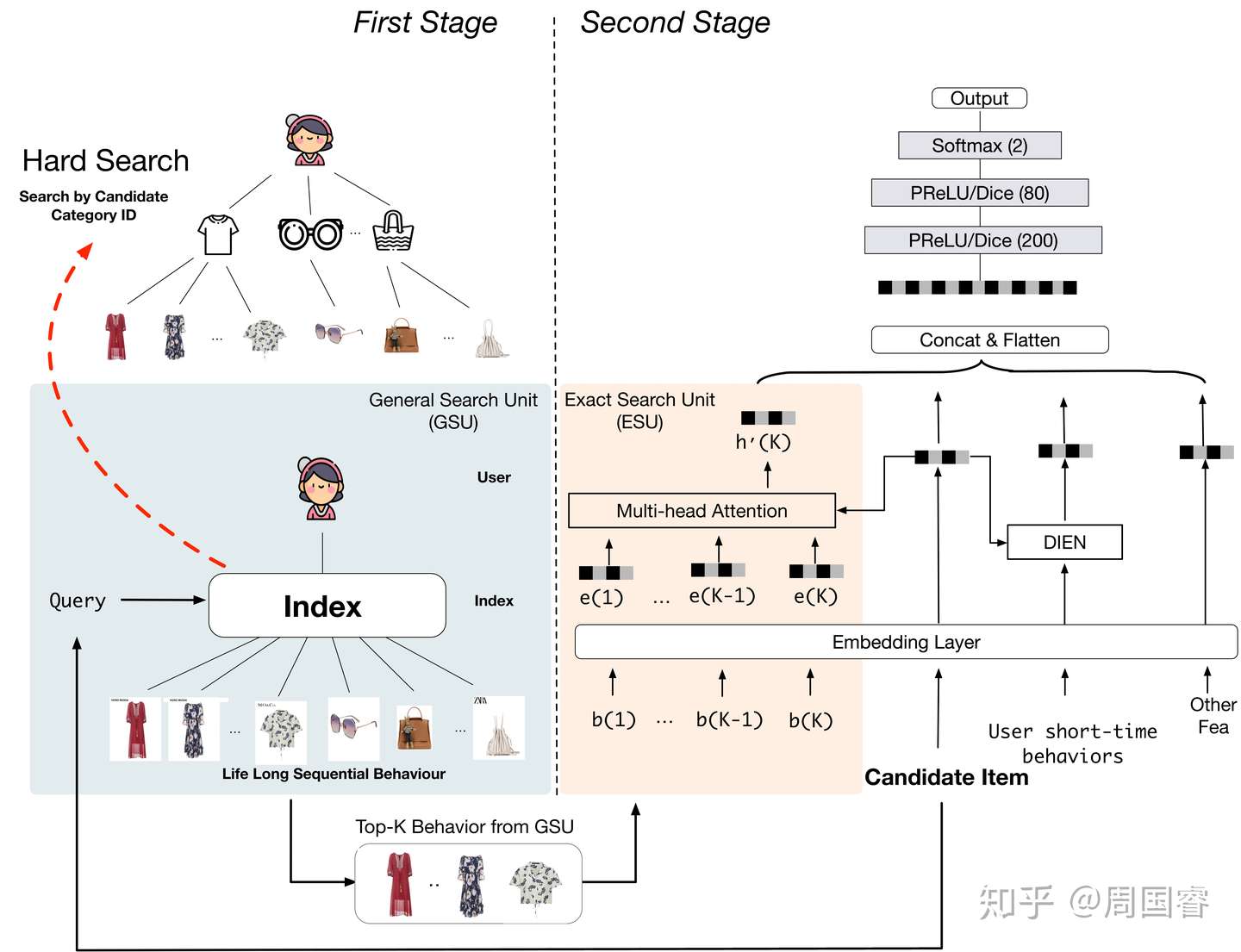 SIM. 以候选的item 信息为query,对用户的所有行为序列,进行分两阶段的search。这里只展示了hard模式的general search.
SIM. 以候选的item 信息为query,对用户的所有行为序列,进行分两阶段的search。这里只展示了hard模式的general search.
当然了这种简化的general search在我们的离线实验中表现的效果还是弱于基于向量检索的方式,但是其实现成本非常低,只需要有一个支持key-key-value存储的data base就能轻松的实现。同时在线计算部分只增加了exact search的计算开销,能比较轻松的在线服务。并且其对未来的进一步模型迭代也未增加太多成本。综合下来我们选择了这个简化版本的SIM。用category或者其他粒度合适的item描述信息作为一个固定的索引结构,新增的行为可以增量的更新这个索引,训练的时候索引部分是非参的,不会在训练过程中变化。因此可以用最新的检索结果可以对所有的参数进行端到端的训练,相当的轻便,非常适合在实际工业场景中部署。当然所处的数据环境如果没有对行为数据进行类似category这样的结构化处理,那么就得想办法构建其他的索引结构了。
SIM在我们看来更大的贡献是提供了一个思路以及具体的两种实现方式。我们目前在线采用的是非参数化的general search。对general search部分进行参数化,比如我们文中提出的使用向量的方式,可以进一步提升效果和扩大该模块未来的迭代空间。如何去对构建的索引做建模,如何进一步的提升general search的精度和效率,都是未来可以进一步迭代的。但是值得一提的是general search部分的参数化会带来额外的系统迭代负担,这部分参数日常学习与更新,学习的遗忘,学习结果的存储都是较大的挑战。当然这也给大家留下了探索和研究的空间。
吹水看介绍,细节看请论文:
https://arxiv.org/pdf/2006.05639.pdf结果
结果就是上线了,效果好,具体数字多说无益。我们其中一部分数据分析倒是值得分享,其印证了我们长期以来在长期兴趣部分的坚持是有意义的。
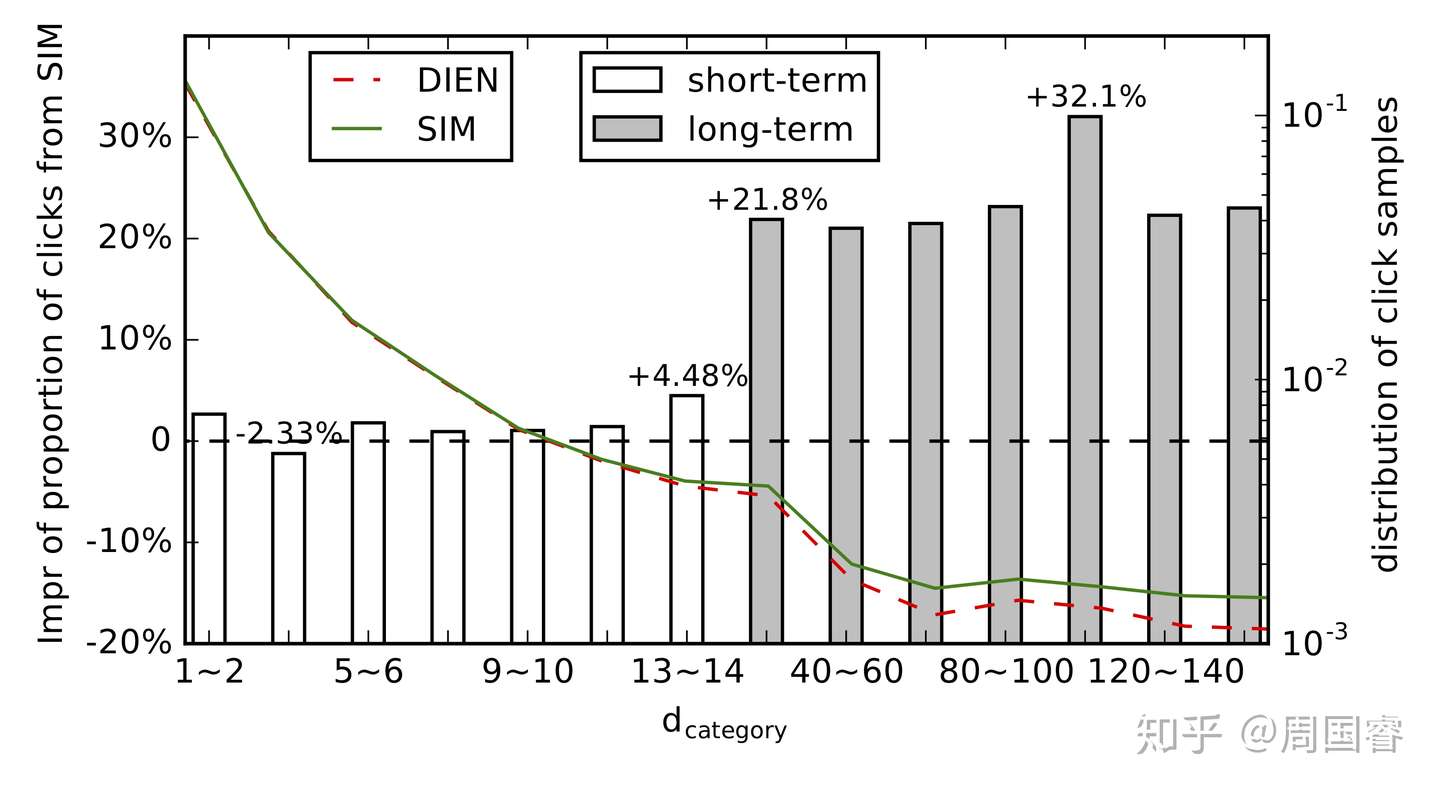
以长短期兴趣建模做区分,我们统计了DIEN和SIM在实际在线的推荐结果。d_category的定义:与用户点击的item 类目相同的行为最近发生日期离当前的天数。同时我们简单的将过去14天内的行为类目覆盖的点击行为定义为短期,超过14天的定义为长期。比如图中40~60这个部分,就是指SIM推荐且被用户点击的item,该用户在过去的仅在40~60天有过同类目的行为,在其他时间都没有于相同类目的item发生交互。同时纵坐标表示SIM的推荐且被点击的item在不同兴趣时间跨度上的数量,我们可以看到虽然SIM和DIEN主要的推荐结果还是集中于近期部分,但是在长期部分SIM的推荐且被点击的结果是显著高于DIEN的。这说明SIM真正更多的推荐出了用户偏向长期行为相关的结果,且用户进行了点击,侧面说明SIM相对更好的建模了长期兴趣。
SIM给出了一个通用的framwork让我们可以给每个用户的所有行为都构建一个索引,在预估CTR的时候可以充分的考虑用户的所有行为表达。具体的SIM在我们的场景有具备构建万级别长度的行为序列的能力,实践里最长的超过了5万。同时理论上,这个长度远没有达到SIM的能力上限。
未来的工作
其实一直以来我都希望做更尊重用户的推荐&广告系统,很早以前就取好了比较口语的名字叫Show U More Respect。SIM这篇工作是我们持续探索后,在用户行为利用的角度给用户更多的尊重,我们充分尊重用户在平台上的行为交互表达,算是向前迈进了一小步。但是当前的索引构建的逻辑无论是简单的以类目构建还是做向量化以内积距离构建,其构建逻辑对每个用户都是相同的,没有在索引构建做到个性化。同时具体到模型上,大部分的参数和学习过程还是共享的。之前在meta-learning方面我尝试过把参数和模型做到一个用户一个模型,不过最后公开数据集比较有效,生产没有明显收益就暂时hold了,毕竟实在没空灌水。希望未来的推荐系统能真正的做到一人一世界,每个用户通过和系统的交互,为自己喜欢和不喜欢投票,构建一个属于自己的推荐系统。让推荐不再是铺天盖地的大数据,不再是无足轻重的多个结果一划而过显得廉价,不再仅仅是理所当然的重定向,让用户得到真正私人定制的个性化服务。让用户更重视推荐结果,更享受和推荐系统交互的过程,自己来打造更好的推荐系统。
参考
- ^[Zhou et al. KDD 2018] Deep interest network for click-through rate prediction. https://dl.acm.org/doi/pdf/10.1145/3219819.3219823
- ^[Zhou et al. AAAI 2019] Deep Interest Evolution Network for Click-Through Rate Prediction. https://arxiv.org/pdf/1809.03672.pdf
- ^[Hidasi et al. 2015] Session-based Recommendations with Recurrent Neural Networks. https://arxiv.org/abs/1511.06939
- ^[Pi et al. KDD 2019] Practice on Long Sequential User Behavior Modeling for Click-Through Rate Prediction. https://dl.acm.org/doi/pdf/10.1145/3292500.3330666
- ^[Shrivastava et al. NeurIPS 2014]Asymmetric LSH (ALSH) for sublinear time maximum inner product search (MIPS).