什么是Faster
Faster 是一个很屌的嵌入式KeyValue 数据库项目
我简单的把 微软官网怎么吹的给大家翻译一下:
Faster:一个为状态管理而生的嵌入式并发KeyValue数据库
在过去的十年间,资源密集型应用程序和云端服务有了巨大的发展。数据由各种各样设备产生出来,云端应用处理这些并作出决策。
这些应用程序典型的特点是密集更新大量的状态,这些状态已经超出了内存容量。并且,他们的访问模式呈现出明显的时间局部性(即,一个数据如果被访问,那么近期他还会大概率被访问)
我们(指微软)设计了Faster,一个新的KeyValue数据库。他是一个混合系统,一部分是一个使无锁并发Hash索引的混合Log数据库,这个数据库可以跨内存和存储器。另一部分是直接在内存中立即更新
Faster的目标是提供比今天广泛部署的系统更强数量级的吞吐量。我们将他设计为一个包含动态代码生成的嵌入式的高级语言组件,并且能够配合任何存储后端,本地SSD硬盘或者云存储。
我们的展示焦点在于:
1. 易用性,可以被高效的整合在云端程序的逻辑代码中
2. 创新的系统设计带来的高性能,能适应不同的内存容量,耐久性和自带的缓存特性
简单说就是屌、很屌、非常屌
微软宣称的数据也很迷人
每秒 一亿6千万 次操作,只用一台"普通"的电脑
自己试一试
https://github.com/microsoft/faster
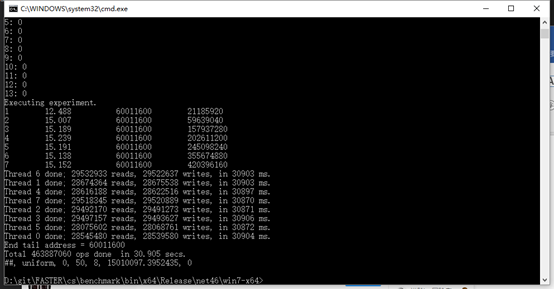
先跑一下benchmark,好的,你是一个异步系统我体会到了,调用系统资源的能力很强。
跑benchmark 连鼠标都动不了
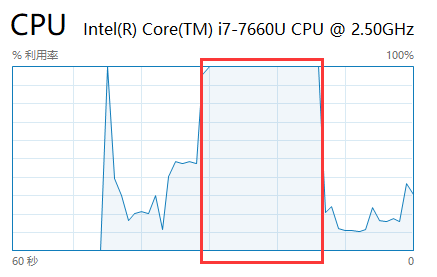
Cpu 是这样的
在我的普通电脑上没有达到一亿6千万,但是有一亿五千多万的ops,还是十分惊人。
遗憾的是因为faster 可以纯内存,也可以写入一个log型数据库,这个成绩是纯内存的。
但是仅仅作为一个缓存,有如此性能也着实令人惊叹,这让我对Faster产生了兴趣,后续会做更多的Faster研习