1.数据库优化概述
为什么要进行数据库优化
1、 避免网站页面出现访问错误
由于数据库连接timeout产生页面5xx错误
由于慢查询造成页面无法加载
由于阻塞造成数据无法提交
2、 增加数据库的稳定性
很多数据库问题都是由于低效的查询引起的
3、 优化用户体验
流畅页面的访问速度
良好的网站功能体验
2.数据库如何进行优化
2.1 数据库设计规范(三大范式)
2.2 添加索引(普通索引,唯一索引,全文索引等等)
2.3 分库分表(垂直分割和水平分割)
2.4 读写分离
2.5 存储过程
2.6 配置MySQL连接参数
2.7 SQL语句优化
2.8 清理碎片化
2.9 mysql服务器优化
3.数据库三大范式
3.1 第一范式:保证每一个列的原子性,不可再分
3.2 第二范式: 在满足第一范式基础之上,保证表中数据的唯一,每一个列都和主键相关,一张表只描述一件事情
3.3 第三范式:在满足第二范式基础之上,保证表中每一个列都和主键直接相关,而不是间接相关
在实际开发场景当中,根据业务需求来定,没有必要非得严格按照三大范式
4.分库分表:mycat
什么时候分库:垂直分割,专库专用
分布式项目,每一个模块是一个工程,进行分库,一个数据库对应一个模块
优点:
1.拆分之后业务更加清晰,拆分规则更加明确
2.系统之间整合或者扩展更加方便
3.数据维护简单
缺点:
1.如果遇到关联,维护起来比较麻烦
2.受各种业务限制
什么时候分表:单张表数据量过大的情况下,进行水平分割,(取模算法)
统计日志(几年),每天产1000,一年365000,单独分析2019年日志
分表规则:
日志根据年份时间 ,腾讯QQ:位数 6 7 8 9 10 (均匀) 手机号开头:13 15 18
优点:
1.每一张表不存在大量的数据
2.对应用透明
3.按照合理的查新规则进行拆分,避免夸库
4.提高了系统的负载能力
缺点:
1.拆分规则不好确定
2.对事务一致性难以解决
3.分页不好做
取模算法:利用id取模进行表的拆分
新建springboot工程
配置文件:application.yml
spring: datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://localhost:3306/levelof username: root password: root
service
@Service public class LevelService { @Resource private JdbcTemplate jdbcTemplate; //用户注册的方法 public String register(String name,String password){ //向UUID表中插入数据 jdbcTemplate.update("insert into uuid values (null)"); //取模算法 //获取插入数据的id Integer id = jdbcTemplate.queryForObject("select last_insert_id()", Integer.class); //计算表 String tableName="user"+id%3; //向分表中插入数据 jdbcTemplate.update("insert into "+tableName+" values ('"+id+"','"+name+"','"+password+"')"); return "success"; } public String getUser(Integer id){ String tableName="user"+id%3; return jdbcTemplate.queryForObject(("select name from "+tableName),String.class); } }
controller
@RestController public class LevelController { @Resource private LevelService levelService; @RequestMapping("/register") public String register(String name,String password){ return levelService.register(name,password); } @RequestMapping("/get") public String get(Integer id){ return levelService.getUser(id); } }
取模其实就是取余,要将数据分到三个表中,就取最后插入数据的id余3
是几就插入到几号库中
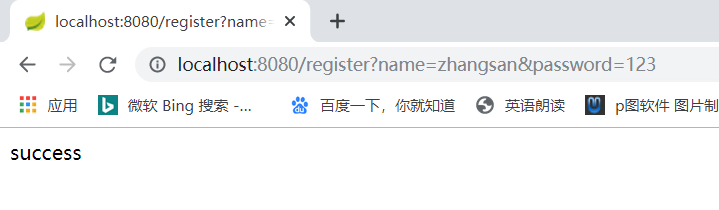
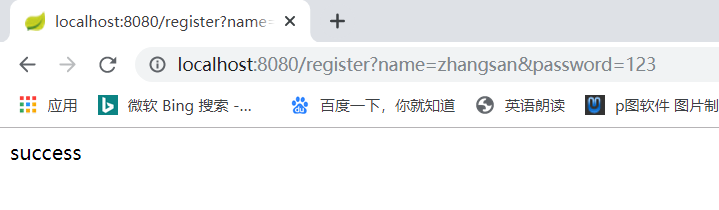
例如第一次插入zhangsan这条记录,UUID表的最后插入的ID为1
1%3=1,所以插入到一号库中
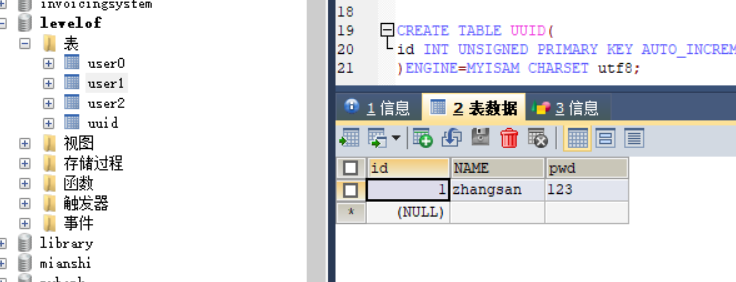
第二次插入lisi这条记录,UUID表的最后插入的ID为22%3=2,所以插入到二号库中
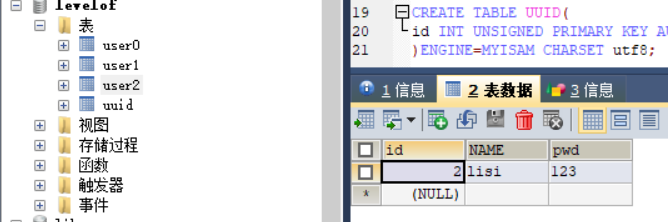
第三次UUID表的最后插入id为3,3%3=0
所以插入到零号库中
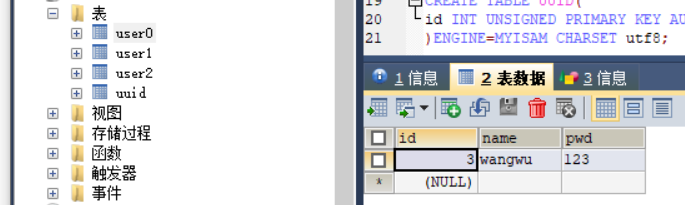
第四次再插入又向一号库插入,依次类推,保证数据量平均
5.定位慢查询
定位到查询慢的SQL语句,MySQL默认认为慢查询时间为10s
##查询慢查询时间,mysql默认10s
SHOW VARIABLES LIKE 'long_query_time';
##查询慢查询的次数
SHOW STATUS LIKE 'slow_queries';
##怎么定位慢查询语句,启动慢查询日志
##1.准备慢查询时间,修改慢查询时间尽量1s set long_query_time=1; 修改my.ini文件(C:ProgramDataMySQLMySQL Server 5.7)
##2.开启慢查询日志:mysql5.7版本默认就是开启,所以在此更改时间和日志路径即可
##慢查询生成日志时间
#slow-query-log=1
#日志文件
#slow_query_log_file="D:\show-query.log"
##慢查询时间
#long_query_time=1
##3.更改完毕后重启服务器
先准备数据
DELIMITER $$ CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255) #该函数会返回一个字符串 BEGIN #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; DECLARE return_str VARCHAR(255) DEFAULT ''; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1)); SET i = i + 1; END WHILE; RETURN return_str; END $$ DELIMITER $$ CREATE FUNCTION rand_num() RETURNS INT(5) BEGIN DECLARE i INT DEFAULT 0; SET i =FLOOR(10+RAND()*500); RETURN i; END $$ DELIMITER $$ CREATE PROCEDURE insert_emp(IN START INT(10),IN max_num INT(10)) BEGIN DECLARE i INT DEFAULT 0; #set autocommit =0 把autocommit设置成0 SET autocommit = 0; REPEAT SET i = i + 1; INSERT INTO emp VALUES ((START+i) ,rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num()); UNTIL i = max_num END REPEAT; COMMIT; END $$ CALL insert_emp (100001,40000000);
执行 SHOW STATUS LIKE 'slow_queries';查询慢查询的次数

是0次
再随便执行几条执行时间超过一秒的sql
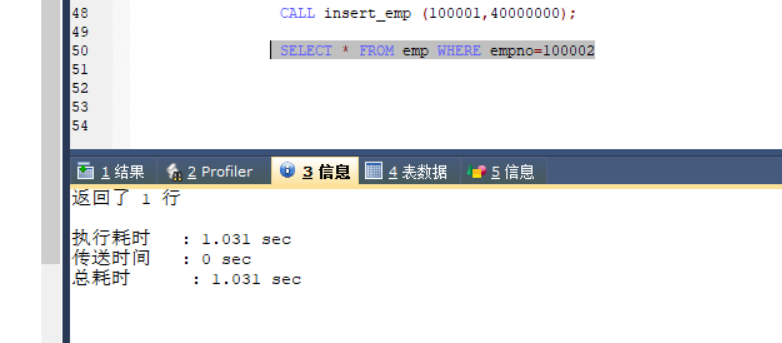
再次查询次数,执行时间超过一秒的记录都被记录了
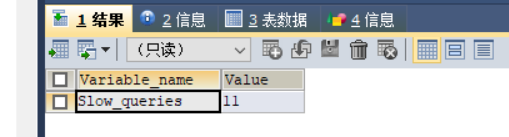
再查看日志文件,这些sql也都被记录下来了