MySQL常用语句
haveing groupby
- WHERE语句在GROUP BY语句之前;SQL会在分组之前计算WHERE语句。
- HAVING语句在GROUP BY语句之后;SQL会在分组之后计算HAVING语句。
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件显示特定的组,也可以使用多个分组标准进行分组。
- select deptno,sum(sal) from emp where sal>1200 group by deptno having sum(sal)>8500 order by deptno;
select sum(age) from member group by sex having sum(age)>400
这条申请量语句的意思就是:从member表中按sex(性别)分组,然后求出各组的年龄总和,至于后面的having是筛选出那些年龄总和大于400的组,在这样的sql语句中我们不能用where来筛选超过年龄超过400的组,因为表中不存在这样一条记录。这时只能用HAVING子句筛选成组后的各组数据。
Varchar nvarchar区别
varchar(n)
长度为 n 个字节的可变长度且非 Unicode 的字符数据。n 必须是一个介于 1 和 8,000 之间的数值。存储大小为输入数据的字节的实际长度,而不是 n 个字节。
Unicode字符集就是为了解决字符集这种不兼容的问题而产生的,它所有的字符都用两个字节表示,即英文字符也是用两个字节表示
nvarchar(n)
包含 n 个字符的可变长度 Unicode 字符数据。n 的值必须介于 1 与 4,000 之间。字节的存储大小是所输入字符个数的两倍。
|
类型 |
长度 |
使用说明 |
长度说明 |
|
char(n) |
定长 |
索引效率高 程序里面使用trim去除多余的空白 |
n 必须是一个介于 1 和 8,000 之间的数值,存储大小为 n 个字节 |
|
varchar(n) |
变长 |
效率没char高 灵活 |
n 必须是一个介于 1 和 8,000 之间的数值。存储大小为输入数据的字节的实际长度,而不是 n 个字节 |
|
nvarchar(n) |
变长 |
处理unicode数据类型(所有的字符使用两个字节表示) |
n 的值必须介于 1 与 4,000 之间。字节的存储大小是所输入字符个数的两倍。所输入的数据字符长度可以为零 |
常用的模糊查询
%为通配符
|
通配符:(LIKE用于字符串,,,,,如果要对数字进行操作用in...in (200,230))
|
drop/ truncate/ delete区别
truncate和delete只删除数据不删除表的结构(定义)
delete语句是数据库操作语言(dml),这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发。
truncate、drop是数据库定义语言(ddl),操作立即生效,原数据不放到rollback segment中,不能回滚,操作不触发trigger。
使用上,想删除部分数据行用delete,注意带上where子句. 回滚段要足够大.
想删除表,当然用drop
delete from friends where user_name = 'simaopig';
truncate 命令很简单,它的意思是:删除表的所有记录。相当于 delete 语句不写 where 子句一样
Where 和on 区别
http://www.2cto.com/database/201301/185770.html
Count(1)和count(*)的区别
count(1) 其实1就代表你这个查询的表里的第一个字段
用Nolock(约束)后果
要提升SQL的查询效能,一般来说大家会以建立索引(index)为第一考虑。其实除了index的建立之外,当我们在下SQL Command时,在语法中加一段WITH (NOLOCK)可以改善在线大量查询的环境中数据集被LOCK的现象藉此改善查询的效能。
不过有一点千万要注意的就是,WITH (NOLOCK)的SQL SELECT有可能会造成Dirty Read(脏读)。
脏读: 一个用户对一个资源做了修改,此时另外一个用户正好读取了这条被修改的记录,然后,第一个用户放弃修改,数据回到修改之前,这两个不同的结果就是脏读。
内连接 (LEFT RIGHT FULL Outer join)外联结
http://www.cnblogs.com/Ewin/archive/2009/10/05/1578322.html
聚集索引和非聚集索引的区别(索引优缺点)
SQL SERVER提供了两种索引:聚集索引和非聚集索引。其中聚集索引表示表中存储的数据按照索引的顺序存储,检索效率比非聚集索引高,但对数据更新影响较 大。非聚集索引表示数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置,非聚集索引检索效率比聚集索引低,但对数据更新影响较 小。
索引就是加快检索表中数据的方法。
http://maoyunaa.blog.163.com/blog/static/550393742012654335711/
临时表和全局临时表
1> -- 本地临时表.
2> CREATE TABLE #temp_table_local (
3> id INT,
4> value VARCHAR(10)
5> );
6> go
1> -- 全局临时表.
2> CREATE TABLE ##temp_table_global (
3> id INT,
4> value VARCHAR(10)
5> );
6> go
对于 本地临时表 (#开头的) 其他会话无法访问数据与表结构
对于 全局临时表 (##开头的) 其他会话可以访问数据与表结构
SQL Server会在会话结束以后,自动删除临时表。
存储过程的优缺点
存储过程是经过预编译的,他的运行效率是要高于简单的SQL语句的。
优点:
1)执行效率高
2)安全性高;
3)可复用高;
缺点
1)维护比较麻烦:比如一个储存过程被N个程序调用,如果更改了这个储存过程的参数,N个程序都要进行更改;
2)容易乱:你写了一个储存过程,如果你离职了别人不知道有个储存过程,可能还需要写一个一样的储存过程,导致浪费;
总结:任何东西都是优缺点共存的,如何做到扬长避短就看个人的了!
数据库的约束()
写几个事务
数据库的数据类型强制转黄 Convert
Union 和union all的区别
Povit和unpovit完成行列转换
关键字:distinct having
Sql 优化
锁定 乐观锁定/悲观锁定
悲观锁,就是不管是否发生多线程冲突,只要存在这种可能,就每次访问都加锁。
乐观锁,就是通过标记值控制,每次操作前通过标记值判断是否是最新内容,最新内容就可以操作,不是最新的就继续循环判断标记值,直到是最新类容。
在大量冲突发生时,悲观锁的锁消耗大,乐观锁的读取次数会多。
http://www.cnblogs.com/kongsq/p/5841397.html
并发修改
索引 结构 哪些列适合建索引
1、表的主键、外键必须有索引;
2、数据量超过300的表应该有索引;
3、经常与其他表进行连接的表,在连接字段上应该建立索引;
4、经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
以上是一些普遍的建立索引时的判断依据。一言以蔽之,索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据。
因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。
另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
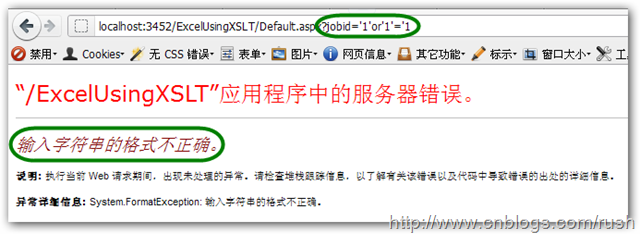
什么是sql注入?如何避免sql注入?
可以这样输入实现免帐号登录:
用户名: ‘or 1 = 1 –
密 码:
从理论上说,后台认证程序中会有如下的SQL语句:
String sql = "select * from user_table where username=
' "+userName+" ' and password=' "+password+" '";
当输入了上面的用户名和密码,上面的SQL语句变成:
SELECT * FROM user_table WHERE username=
'’or 1 = 1 -- and password='’
参数化SQL语句
还是回到之前动态拼接SQL基础上,我们知道一旦有恶意SQL代码传递过来,而且被拼接到SQL语句中就会被数据库执行,那么我们是否可以在拼接之前进行判断呢?——命名SQL参数。
string sql1 = string.Format("SELECT job_id, job_desc, min_lvl, max_lvl FROM jobs WHERE job_id = @jobId");
using (var con = new SqlConnection(ConfigurationManager.ConnectionStrings["SQLCONN1"].ToString()))
using (var com = new SqlCommand(sql1, con))
{
// Pass jobId to sql statement.
com.Parameters.Add("@jobId", SqlDbType.Int).Value = jobId;
com.Connection.Open();
gdvData.DataSource = com.ExecuteReader();
gdvData.DataBind();
}
数据库三范式是什么?
说出一些数据库优化方面的经验?
索引内部原理:想象成Dictionary,插入、删除、更新的速度慢了,加上索引也多占用了空间,查询的速度快了。加上索引以后速度提升非常明显。
(1)在经常检索的字段上(select * from Person where Name=@Name)使用索引提高查询速度。(2)select中只列出必要的字段,而不是*。(3)避免隐式类型转换造成的全表扫描,在索引上使用函数也会造成全表扫描(因为索引只是为字段建立的,一旦使用表达式或者函数,那么索引就是失效了,当然也可以使用“函数索引”、“表达式索引”解决这个问题),使用索引不一定能提高查询速度。(4)避免在索引列上使用计算(where Name+'A'=@MyName)
加分的回答:不进行无意义优化,根据性能查看器的报表,对最耗时的SQL进行优化。
什么是数据库事务?
事务三个特性:一致性、原子性、隔离性。
几个SQL语句,要么全部执行成功,要么全部执行失败。举例就用最经典的银行转账的例子就行,然后再举一个项目中用的例子:传智播客.net培训中批量导入客户数据的时候要么全部导入成功,要么全部导入失败。事务的三个操作:Begin、Commit、RollBack。
取刚插入数据的id值,就要用事务来隔离:Insert 和select top 1 id from ....
一个文本文件含有如下内容:
4580616022644994|3000|赵涛
4580616022645017|6000|张屹
4580616022645090|3200|郑欣夏
上述文件每行为一个转账记录,第一列表示帐号,第二列表示金额,第三列表示开户人姓名。
创建一张数据库表(MS SQLServer数据库,表名和字段名自拟),请将上述文件逐条插入此表中。