| 作业要求 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 我在这个课程的目标是 | 学习软件工程,会独立编写程序 |
| 此作业在哪个具体方面帮我实现目标 | 学习python语言 |
| 其他参考文献 | https://blog.csdn.net/weixin_30657541/article/details/99123704 |
| 作业正文(码云链接) | https://gitee.com/chenyue666/MyGit/blob/master/2.py |
| 结对 | https://www.cnblogs.com/dragonD/p/12635628.html |
作业一
作业二
两人自由组队进行结对编程
参考结对编程的方法、过程(https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html)开展两人合作完成本项目
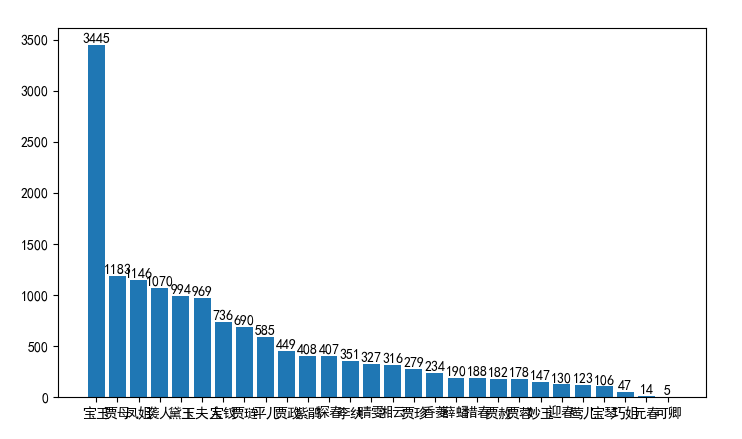
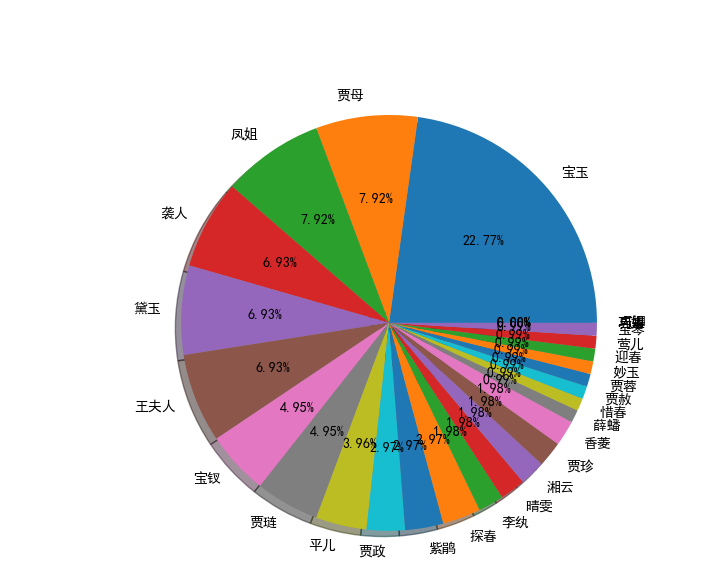
针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。实现一个简单而完整的软件工具(中文文本文件人物统计程序):
进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
《红楼梦》与《水浒传》的文本小说将会发到群里。
注意,要求能够分章节自动获得人物出现次数
运行结果
代码
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
def showNameBar(self,name_list_sort,name_list_count):
x = np.arange(len(name_list_sort))
plt.rcParams['font.sans-serif'] = ['SimHei']
bars = plt.bar(x,name_list_count)
plt.xticks(x,name_list_sort)
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
plt.show()
def showNamePie(self, name_list_sort, name_list_fracs):
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
plt.show()
def getNameTimesSort(self,name_list,txt_path):
for k in name_list:
jieba.add_word(k)
file_obj = open(txt_path, 'rb').read()
jieba_cut = jieba.cut(file_obj)
book_counter = Counter(jieba_cut)
name_dict ={}
name_total_count = 0
for k in name_list:
if k == '熙凤':
name_dict['凤姐'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
name_counter = Counter(name_dict)
name_list_sort = []
name_list_fracs = []
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
self.showNameBar(name_list_sort, name_list_count)
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
name_list = ['宝玉', '黛玉', '宝钗', '元春', '探春', '湘云', '妙玉', '迎春', '惜春', '凤姐', '熙凤', '巧姐', '李纨', '可卿', '贾母', '贾珍', '贾蓉', '贾赦', '贾政', '王夫人', '贾琏', '薛蟠', '香菱', '宝琴', '袭人', '晴雯', '平儿', '紫鹃', '莺儿']
txt_path = 'D:/123.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)