1、整数(int)
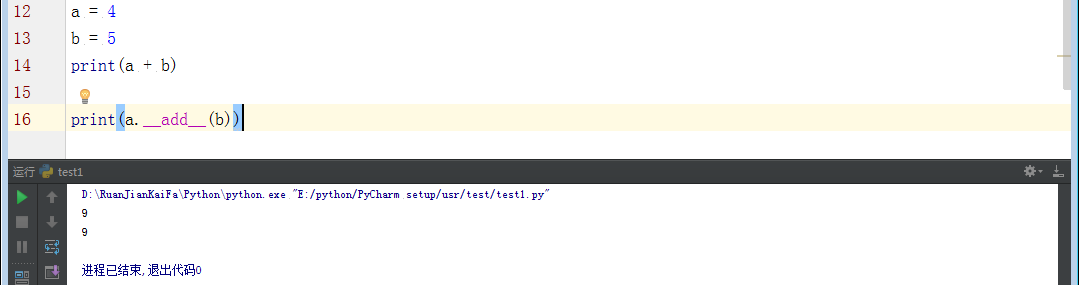
1)基本数据类型提供了许多内部调用方法,如__add__,其效果和加法一样,即整数在做加法时,会内部调用__add__方法来完成。带下划线的方法用的少,所以其带下划线方法可以忽略。
2、str类型
1)下面列出部分API解释。
str.capitalize() Return a copy of the string with its first character capitalized and the rest lowercased. """首字母变大写""" 示例: c = "chl" print(c.capitalize()) 结果: Chl
str.center(width[, fillchar]) Return centered in a string of length width. Padding is done using the specified fillchar (default is an ASCII space). The original string is returned if width is less than or equal to len(s). """内容居中,width:总长度,fillchar:空白处填充内容,默认无""" 示例: a = "chl" print(a.center(9, "*")) 结果: ***chl***
str.count(sub[, start[, end]]) Return the number of non-overlapping occurrences of substring sub in the range [start, end]. Optional arguments start and end are interpreted as in slice notation. """计算子序列出现次数,sub:子序列,start和end:定义查找范围,默认整个字符串""" 示例: a = "chl is chl" print(a.count("chl", 0, 10)) 结果: 2
str.endswith(suffix[, start[, end]]) Return True if the string ends with the specified suffix, otherwise return False. suffix can also be a tuple of suffixes to look for. With optional start, test beginning at that position. With optional end, stop comparing at that position. """是否以XXX结尾,返回布尔值,start和end:定义查找范围,默认整个字符串"""
"""类似的有startswith,判断是否以XXX开头"""
示例: a = "chl is chl" print(a.endswith("chl")) print(a.endswith("is", 0, 6)) 结果: True True
str.expandtabs(tabsize=8) Return a copy of the string where all tab characters are replaced by one or more spaces, depending on the current column and the given tab size. Tab positions occur every tabsize characters (default is 8, giving tab positions at columns 0, 8, 16 and so on). To expand the string, the current column is set to zero and the string is examined character by character. If the character is a tab ( ), one or more space characters are inserted in the result until the current column is equal to the next tab position. (The tab character itself is not copied.) If the character is a newline ( ) or return ( ), it is copied and the current column is reset to zero. Any other character is copied unchanged and the current column is incremented by one regardless of how the character is represented when printed. """将制表符转换为空格,默认为8个空格""" >>> '01 012 0123 01234'.expandtabs() '01 012 0123 01234' >>> '01 012 0123 01234'.expandtabs(4) '01 012 0123 01234' 示例: a = "chl is chl" print(a.expandtabs()) print(a.expandtabs(20)) 结果: chl is chl chl is chl
str.find(sub[, start[, end]]) Return the lowest index in the string where substring sub is found within the slice s[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 if sub is not found. """查找子序列,返回第一个元素下标,如果没有找到返回-1,start和end:定义查找范围,默认整个字符串""" Note The find() method should be used only if you need to know the position of sub. To check if sub is a substring or not, use the in operator: >>> 'Py' in 'Python' True 示例: a = "chl is chl" print(a.find("l")) print(a.find("is", 2, 10)) 结果: 2 4
str.format(*args, **kwargs) Perform a string formatting operation. The string on which this method is called can contain literal text or replacement fields delimited by braces {}. Each replacement field contains either the numeric index of a positional argument, or the name of a keyword argument. Returns a copy of the string where each replacement field is replaced with the string value of the corresponding argument. """字符串格式化,动态参数""" API示例:其中{0}称为占位符 >>> "The sum of 1 + 2 is {0}".format(1+2) 'The sum of 1 + 2 is 3'
str.index(sub[, start[, end]]) Like find(), but raise ValueError when the substring is not found. """功能与find一样,只是找不到时报错""" 示例: a = "chl is chl" print(a.index("is")) print(a.index("Hello")) 结果: 4 Traceback (most recent call last): File "E:/python/PyCharm setup/usr/test/test1.py", line 41, in <module> print(a.index("Hello")) ValueError: substring not found
str.isalnum() Return true if all characters in the string are alphanumeric and there is at least one character, false otherwise. A character c is alphanumeric if one of the following returns True: c.isalpha(), c.isdecimal(), c.isdigit(), or c.isnumeric(). """判断字符串是否只包含数字和字母""" 示例: a = "chl123456" b = "chl******" print(a.isalnum()) print(b.isalnum()) 结果: True False
str.isalpha() Return true if all characters in the string are alphabetic and there is at least one character, false otherwise. Alphabetic characters are those characters defined in the Unicode character database as “Letter”, i.e., those with general category property being one of “Lm”, “Lt”, “Lu”, “Ll”, or “Lo”. Note that this is different from the “Alphabetic” property defined in the Unicode Standard. """判断字符串是否都是字母"""
str.isdigit() Return true if all characters in the string are digits and there is at least one character, false otherwise. Digits include decimal characters and digits that need special handling, such as the compatibility superscript digits. Formally, a digit is a character that has the property value Numeric_Type=Digit or Numeric_Type=Decimal. """判断字符串是否都是数字"""
str.islower() Return true if all cased characters [4] in the string are lowercase and there is at least one cased character, false otherwise. """判断字符串是否都是小写字母"""
str.isspace() Return true if there are only whitespace characters in the string and there is at least one character, false otherwise. Whitespace characters are those characters defined in the Unicode character database as “Other” or “Separator” and those with bidirectional property being one of “WS”, “B”, or “S”. """判断是不是空格"""
str.istitle() Return true if the string is a titlecased string and there is at least one character, for example uppercase characters may only follow uncased characters and lowercase characters only cased ones. Return false otherwise. """判断是不是标题,即所有首字母都大写"""
str.isupper() Return true if all cased characters [4] in the string are uppercase and there is at least one cased character, false otherwise. """判断字符串是否都是大写字母"""
str.join(iterable) Return a string which is the concatenation of the strings in the iterable iterable. A TypeError will be raised if there are any non-string values in iterable, including bytes objects. The separator between elements is the string providing this method. """以指定字符串连接,参数是可序列化的""" 示例: li = ["chl", "is", "chl"] print("_".join(li)) 结果: chl_is_chl
str.ljust(width[, fillchar]) Return the string left justified in a string of length width. Padding is done using the specified fillchar (default is an ASCII space). The original string is returned if width is less than or equal to len(s). """字符串左对齐,width:总宽度,fillchar:填充内容"""
"""类似的有rjust,字符串右对齐"""
示例: a = "chl" print(a.ljust(9, "*")) 结果: chl******
str.lower() Return a copy of the string with all the cased characters [4] converted to lowercase. """字符串变小写"""
str.lstrip([chars]) Return a copy of the string with leading characters removed. The chars argument is a string specifying the set of characters to be removed. If omitted or None, the chars argument defaults to removing whitespace. The chars argument is not a prefix; rather, all combinations of its values are stripped: """移除左边字符,默认为空格"""
"""类似的有rstrip,移除右边空白;strip,移除两端空白"""
API示例: >>> ' spacious '.lstrip() 'spacious ' >>> 'www.example.com'.lstrip('cmowz.') 'example.com'
str.partition(sep) Split the string at the first occurrence of sep, and return a 3-tuple containing the part before the separator, the separator itself, and the part after the separator. If the separator is not found, return a 3-tuple containing the string itself, followed by two empty strings. """将字符串分割成前、中、后三部分,返回元组""" 示例: a = "chl is chl" print(a.partition("is")) 结果: ('chl ', 'is', ' chl')
str.replace(old, new[, count]) Return a copy of the string with all occurrences of substring old replaced by new. If the optional argument count is given, only the first count occurrences are replaced. """替换字符串,old:待替换字符串,new:新字符串,count:替换几个字符串""" 示例: a = "chl is chl" print(a.replace("chl", "ccc")) print(a.replace("chl", "ccc", 1)) 结果: ccc is ccc ccc is chl
str.rfind(sub[, start[, end]]) Return the highest index in the string where substring sub is found, such that sub is contained within s[start:end]. Optional arguments start and end are interpreted as in slice notation. Return -1 on failure. """与find类似,只是默认从右向左查找"""
str.split(sep=None, maxsplit=-1) Return a list of the words in the string, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done (thus, the list will have at most maxsplit+1 elements). If maxsplit is not specified or -1, then there is no limit on the number of splits (all possible splits are made). """按字符分割字符串,默认为空格,maxsplit:分割多少次,返回列表""" """类似的有rsplit方法,从右向左分割""" If sep is given, consecutive delimiters are not grouped together and are deemed to delimit empty strings (for example, '1,,2'.split(',') returns ['1', '', '2']). The sep argument may consist of multiple characters (for example, '1<>2<>3'.split('<>') returns ['1', '2', '3']). Splitting an empty string with a specified separator returns ['']. For example: >>> '1,2,3'.split(',') ['1', '2', '3'] >>> '1,2,3'.split(',', maxsplit=1) ['1', '2,3'] >>> '1,2,,3,'.split(',') ['1', '2', '', '3', ''] If sep is not specified or is None, a different splitting algorithm is applied: runs of consecutive whitespace are regarded as a single separator, and the result will contain no empty strings at the start or end if the string has leading or trailing whitespace. Consequently, splitting an empty string or a string consisting of just whitespace with a None separator returns []. For example: >>> '1 2 3'.split() ['1', '2', '3'] >>> '1 2 3'.split(maxsplit=1) ['1', '2 3'] >>> ' 1 2 3 '.split() ['1', '2', '3']
str.swapcase() Return a copy of the string with uppercase characters converted to lowercase and vice versa. Note that it is not necessarily true that s.swapcase().swapcase() == s. """大写变小写,小写变大写"""
str.title() Return a titlecased version of the string where words start with an uppercase character and the remaining characters are lowercase. """把字符串变成标题""" For example: >>> 'Hello world'.title() 'Hello World'
str.upper() Return a copy of the string with all the cased characters [4] converted to uppercase. Note that str.upper().isupper() might be False if s contains uncased characters or if the Unicode category of the resulting character(s) is not “Lu” (Letter, uppercase), but e.g. “Lt” (Letter, titlecase). """变大写"""
str.zfill(width) Return a copy of the string left filled with ASCII '0' digits to make a string of length width. A leading sign prefix ('+'/'-') is handled by inserting the padding after the sign character rather than before. The original string is returned if width is less than or equal to len(s). """返回指定长度的字符串,字符串右对齐,前面填充0""" API示例: >>> "42".zfill(5) '00042' >>> "-42".zfill(5) '-0042'
~~~API走了一遍,留个大概印象~~~
2)字符串索引
示例:
a = "chl is chl"
print(a[0])
结果:
c
3)字符串切片
示例:
a = "chl is chl"
print(a[0:5])
结果:
chl i
4)字符串长度
示例:
a = "chl is chl"
print(len(a))
结果:
10