系统稳定性评测
什么是系统的稳定性评测呢,主要验证在以下两个条件下,系统依然能够正常的提供服务。
- 持续施压
- 暴力破坏
持续施压
这一点和自动化遍历的原理很像, 我们长期运行自动化测试, 持续给后端服务施压。 只不过有两个不一样的地方
- 自动化遍历是单线程执行, 而在后端的稳定性测试中,要放大这个量。 比如说本来一次自动化测试是启动50个线程,但我继续放大这个量,比如我放大10倍, 100倍。让这个系统处于一种较高的压力。
- 自动化遍历是随机点击,深度不够。 而后端的稳定性测试的场景一般是针对整个系统的,所以测试用例都是应用级的,而不是单接口测试。 也就是说不管自动化的方式是UI的还是接口的还是SDK的,都要讲独立的API组合各种业务场景。 覆盖的真实场景越多越好。
这里需要注意的是我们需要让系统在这个场景下持续运行很长一段时间。 多久呢? 比如说1个星期,甚至更久, 因为很多诸如内存泄露的问题是会在系统运行很久之后才会出现的。所以在这期我们也需要间监控服务是否出现异常,自动化测试用例是否会出现失败。
实现思路:
最简单的方法就是写个java的 schedulerExecutor。 按策略持续并发的调度自动化测试。比如以下是部分核心代码:
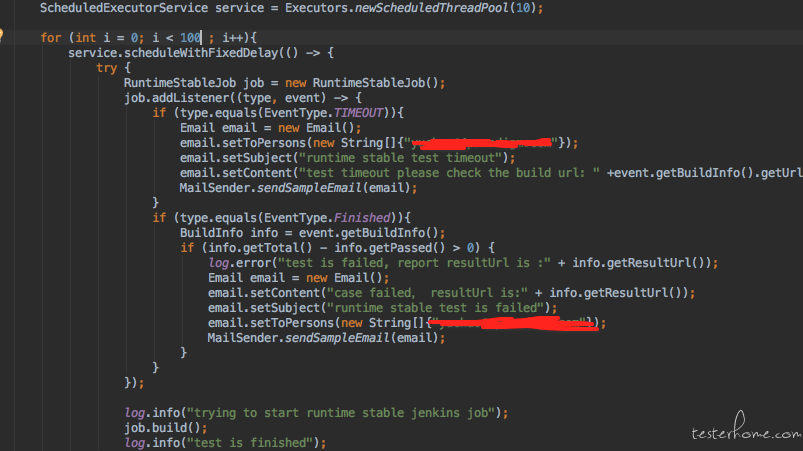
暴力破坏
第二种测试就是在人为造成的事故的场景下,系统依然能够稳定运行。比如现在的软件很多都是微服务架构了, 并且做了很多高可用,负载均衡,容灾等设计。 所以是保证了即便部分模块甚至节点出现问题,也能够保证系统正常提供服务的。 为了验证这一点,我们自然也需要做一点破坏工作。 比如我们公司的产品是部署再k8s中的,那么在运行稳定测试的途中就要使用工具按不同的策略kill不同的服务。 在业界有个很出名的工具叫chaos monkey, 是在云服务器中模拟各种事故,对服务进行各种破坏的工具。 当然它的使用场景有限,无法应用在k8s集群中,但我们可以借鉴其思路调用k8s的API开发自己的工具。
比如我们按事故等级划分:
- 等级一:周期随机破坏一个服务的部分实例
- 等级二:周期按百分比随机破坏数个服务的部分实例
- 等级三:周期破坏所有服务的部分示例
PS:以上说的部分实例是因为都是开启了高可用与负载均衡的部署架构,理论上只要有一个实例就可以对外提供服务。 所以在每个事故等级下都会有更细粒度的划分。 比如:
- 只破坏当前服务的一个实例
- 破坏当前服务的多个实例(由测试人员自己指定)
- 只留下当前服务的一个实例,其他实例均破坏掉。
实现思路:
也很简单,封装k8s的API server达到按策略随机破坏的目的。以下是核心代码:
-
package chaos;
-
-
import chaos.pod.PodKillPolicy;
-
import chaos.pod.PodKiller;
-
import com.fasterxml.jackson.annotation.JsonProperty;
-
import io.fabric8.kubernetes.client.DefaultKubernetesClient;
-
import k8s.K8SClientFactory;
-
import lombok.Data;
-
import lombok.extern.log4j.Log4j;
-
import utils.Common;
-
-
import java.util.*;
-
import java.util.concurrent.TimeUnit;
-
-
/**
-
* Created by sungaofei on 18/11/7.
-
*/
-
@Data
-
@Log4j
-
public class NamespaceKiller {
-
@JsonProperty
-
private String namespace;
-
@JsonProperty
-
private List<String> deploymentList = new ArrayList<>();
-
-
@JsonProperty
-
private PodKillPolicy podKillPolicy;
-
@JsonProperty
-
private AccidentLevel accidentLevel = AccidentLevel.ONE_SERVICE;
-
@JsonProperty
-
private double percent;
-
-
public NamespaceKiller(String namespace) {
-
this.namespace = namespace;
-
DefaultKubernetesClient k8s = K8SClientFactory.getK8SClient();
-
k8s.inNamespace(namespace).apps().deployments().list().getItems().forEach((deploy) -> this.deploymentList.add(deploy.getMetadata().getName()));
-
this.podKillPolicy = PodKillPolicy.KILL_ONE;
-
}
-
-
-
public void kill() {
-
log.info(Common.parseJson(this));
-
-
List<PodKiller> podKillers = new ArrayList<>();
-
-
for (String deployName : deploymentList) {
-
PodKiller podKiller = new PodKiller(namespace, deployName, podKillPolicy);
-
podKillers.add(podKiller);
-
}
-
-
Random random = new Random();
-
-
// 如果策略是按照百分比去kill掉namespace下的服务
-
if (accidentLevel.equals(AccidentLevel.Percent_Kill)) {
-
int size = new Long(Math.round((double) podKillers.size() * percent)).intValue();
-
Map<Integer, PodKiller> deletedPod = new HashMap<>();
-
for (int i = 0; i < size; i++) {
-
-
// 如果随机的index是之前已经被删除过的。 那么需要重新随机
-
int index = random.nextInt(podKillers.size());
-
while (true){
-
if (!deletedPod.containsKey(index)){
-
deletedPod.put(index, podKillers.get(index));
-
break;
-
}
-
log.info("recreate the random index");
-
index = random.nextInt(podKillers.size());
-
}
-
-
PodKiller podKiller = podKillers.get(index);
-
podKiller.kill();
-
deletedPod.put(index, podKiller);
-
}
-
}
-
-
// 如果策略是一个namespace下只随机杀死一个deployment的服务的情况
-
if (accidentLevel.equals(AccidentLevel.ONE_SERVICE)){
-
int index = random.nextInt(podKillers.size());
-
podKillers.get(index).kill();
-
}
-
-
// 如果策略是杀死一个namespace下所有的服务的情况
-
if (accidentLevel.equals(AccidentLevel.ALL_SERVICES)){
-
podKillers.forEach(PodKiller::kill);
-
}
-
-
}
-
-
-
}
监控
在稳定性测试中必然少不了监控体系, 因为我们在评测整个系统的稳定性的时候,必然要附带各个资源使用指标, 以及各种事故分析报告。 所以要对系统的方方面面提供完善的监控体系, 而我们使用的是prometheus 监控体系,k8s已经比较好的支持 prometheus了,所以可以整体集成进k8s中。 可以定制自己的仪表盘来可视化我们的事故分析报告。 比如使用granfna制定过去10天内OOM的事故报告:
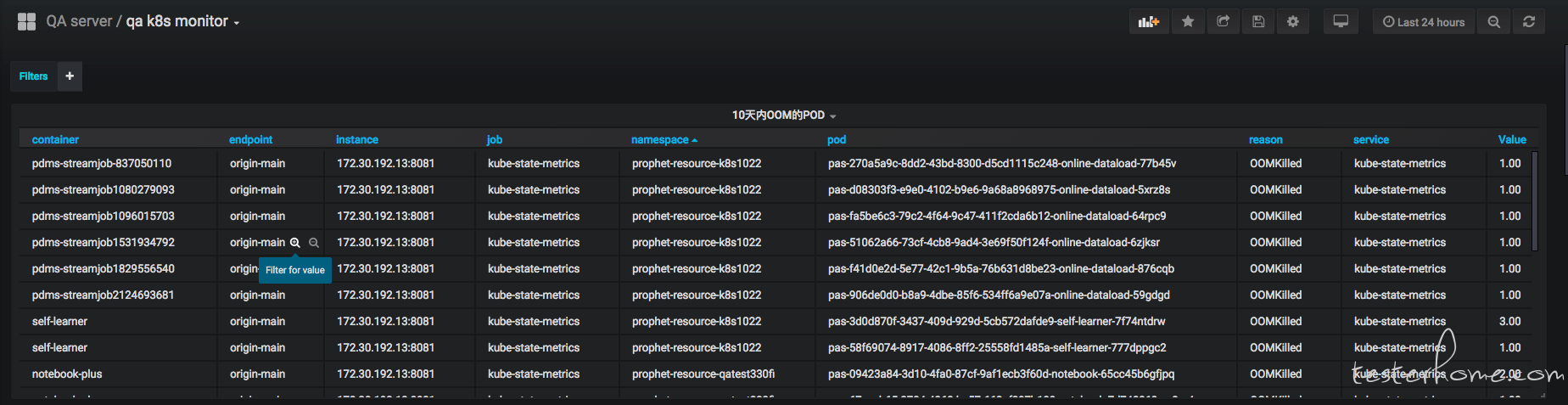
具体prometheus的教程我就先不写了。。。有好多。。不搬了。。
结尾
在软件界针对可靠性有以下指标:
3个9:(1-99.9%)*365*24=8.76小时,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是8.76小时。
4个9:(1-99.99%)*365*24=0.876小时=52.6分钟,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是52.6分钟。
5个9:(1-99.999%)*365*24*60=5.26分钟,表示该软件系统在连续运行1年时间里最多可能的业务中断时间是5.26分钟。
稳定性测试的目标之一就是验证并辅助系统达到更高的指标。