课后练习:

结果:
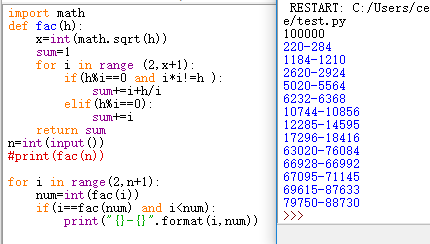

结果:

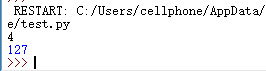
拓展练习:
1. 从键盘输入整数 n(1-9 之间),对于 1-100 之间的整数删除包含 n 并且能被 n 整除的 数,例如如果 n 为 6,则要删掉包含 6 的如 6,16 这样的数及是 6 的倍数的如 12 和 18 这 样的数,输出所有满足条件的数,要求每满 10 个数换行。
测试数据: Enter the number: 6
屏幕输出:

代码:
1 counter=0 2 n=int(input()) 3 StrN=str(n) 4 for i in range(1,101): 5 Str=str(i) 6 if(i%n!=0 and StrN not in Str ): 7 if(counter != 9): 8 print (i,end=',') 9 counter+=1 10 else: 11 print(i) 12 counter=0
输出结果:

2. 请用随机函数产生 500 行 1-100 之间的随机整数存入文件 random.txt 中,编程寻找这 些整数的众数并输出,众数即为一组数中出现最多的数。
1 import random 2 counter=0 3 List=[] 4 with open('random.txt','w')as f: 5 while(counter!=500): 6 n=random.randint(0,100) 7 f.writelines(str(n)+' ') 8 List.append(n) 9 counter+=1 10 maxnum=max(List.count(x) for x in set(List)) 11 for x in set(List): 12 if(maxnum==List.count(x)): 13 print(x)
运行结果:
3. 文件 article.txt 中存放了一篇英文文章(请自行创建并添加测试文本),假设文章中的 标点符号仅包括“,”、“.”、“!”、“?”和“…”,编程找出其中最长的单词并输出
字符串中的split函数只能用一个符号分割字符。re模块中的split可以用多个符号分割字符,因此注意导入re模块。
1 import re 2 with open('article.txt','r')as f: 3 Str=f.read() 4 List=re.split(' |?|!|,|.{1,3}',Str) 5 print(List) 6 maxlength=max(len(x) for x in set(List)) 7 for x in set(List): 8 if len(x)==maxlength: 9 print(x)
输入文件的内容:
aaa,bb,c.good!?emm mmm...thisistheanswer.
输出结果:

爬虫小实验:
爬虫进阶练习:
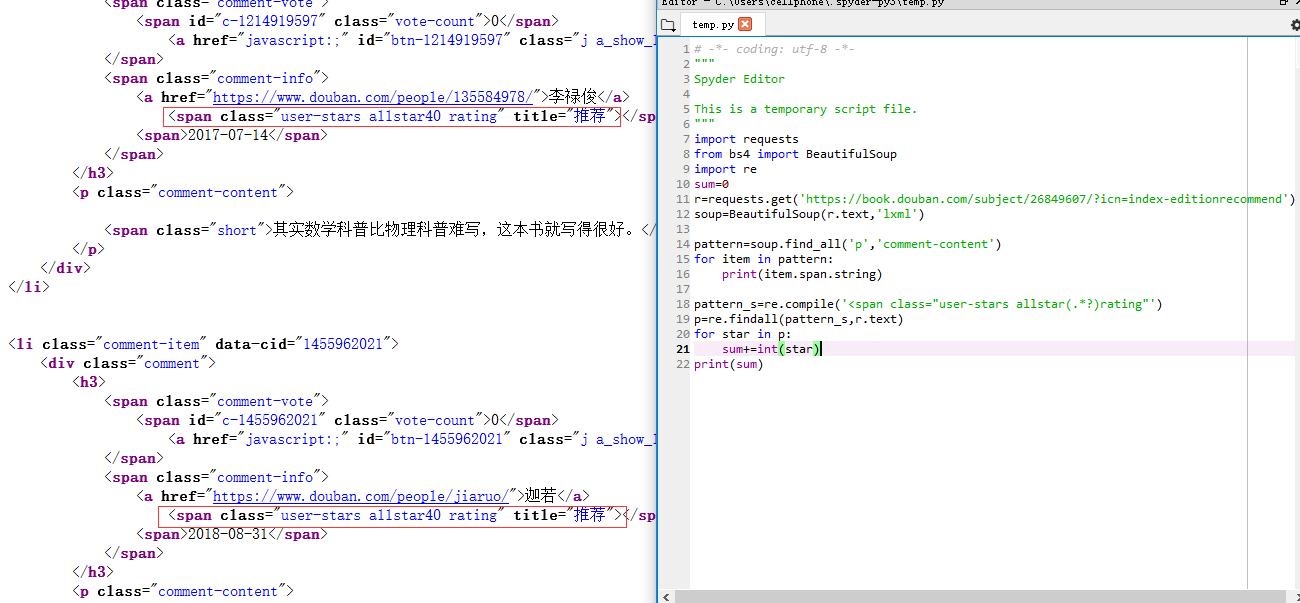
1. “迷你爬虫编程小练习”进阶:抽取某本书的前 50 条短评内容并计算评分(star)的平
均值。提示:有的评论中并不包含评分。
没有评分的情况如下图所示:
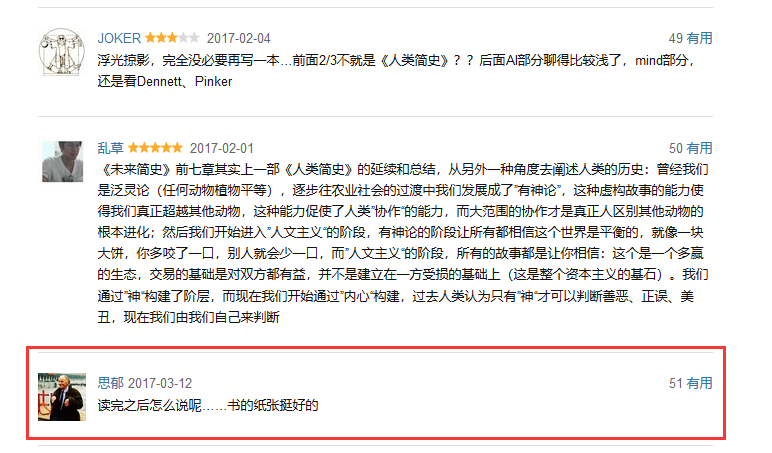
(注:以下是Dazhuang老师的代码
1 import requests,re,time 2 from bs4 import BeautifulSoup 3 4 count=0 5 i=0 #页数 6 s,count_s,count_del=0,0,0 7 lst_stars=[] 8 while count<50: 9 try: 10 r=requests.get('https://book.douban.com/subject/26943161/comments/hot?p='+str(i+1)) 11 except Exception as err: 12 print(err) 13 break 14 soup=BeautifulSoup(r.text,'lxml') 15 comments=soup.find_all('span','short') #直接取得评论 16 17 pattern=re.compile('<span class="user-stars allstar(.*?)rating"') 18 p=re.findall(pattern,r.text) 19 for item in comments: 20 count+=1 21 if(count>50): 22 count_del+=1 #超出50条记录的部分 23 else: 24 print(count,item.string) 25 26 for star in p: 27 lst_stars.append(int(star)) 28 29 time.sleep(5) 30 i+=1 #更新页数 31 32 for star in lst_stars[:-count_del]: 33 s+=int(star) 34 print(s//(len(lst_stars)-count_del))
2. 在“http://money.cnn.com/data/dow30/”上抓取道指成分股数据并将 30 家公司
的代码、公司名称和最近一次成交价放到一个列表中输出。
1 import requests 2 import re 3 4 def retrieve(): 5 r=requests.get('http://money.cnn.com/data/dow30/') 6 pattern=re.compile('class="wsod_symbol">(.*?)</a>.*?<span.*?">(.*?)</span>.*? .*?class="wsod_stream">(.*?)</span>') 7 List = re.findall(pattern,r.text) 8 return List 9 10 alist=retrieve() 11 print(alist)
3. 请爬取网页(http://www.volleyball.world/en/vnl/women/results-and
ranking/round1)上的数据(包括 TEAMS and TOTAL, WON, LOST of MATCHES)
提示:在处理时可以用已学的方法将每一项需要的内容(如 USA 和 15)单独解析 出来,但这种做法将有联系的数据打散了,较好的做法是将每个 TEAM 的相关数据按 组解析出来。但是由于包含这 4 项信息的源代码(请自行观察)分在多行,所以在处 理时可以通过设置 flags 参数以多行模式来解决这个问题(形如 pattern = re.compile(…, flags=re.M) ) , 并且在构造正则表达式时要把换行时的空白字符表示出来(用s+可表 示多个空白字符)。
正则表达式补充知识:

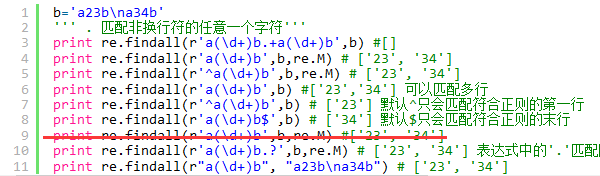
若没有re.M,且没有^与$,正则表达式默认匹配多行(如6)。